What Is Data Observability? A Practical Guide

Data observability is the capacity to fully understand the health and state of your data ecosystem. It extends beyond simple monitoring by providing the context needed to diagnose why data issues occur. Instead of just flagging a known problem, observability tooling allows you to explore unexpected failures and trace their impact from the source system to the final dashboard.
Beyond the “Check Engine” Light
Traditional data monitoring is like the check-engine light in a car. It indicates a problem exists but offers no specific diagnosis. Is it a critical engine failure or a loose gas cap? This reactive approach forces engineers to run time-consuming diagnostics to find the root cause, which is insufficient for today’s complex data architectures.
Data observability, in contrast, functions like a full diagnostic dashboard. It provides a complete, end-to-end view of the data ecosystem using detailed metrics, logs, and lineage to pinpoint the exact location and nature of any issue. This shift from reacting to predefined alerts to proactively understanding system behavior is critical for any data-driven organization.
The Problem of Data Downtime
Modern data stacks, built on platforms like Snowflake or Databricks, are inherently complex. Within this complexity, subtle issues can corrupt analytics, degrade AI model performance, and erode business trust in its data.
This is data downtime—any period when data is missing, inaccurate, or otherwise unreliable. These issues often go unnoticed until they surface in a critical executive report or a customer-facing application, causing significant business impact.
Data observability directly addresses this by giving data teams the tools to detect and resolve these hidden problems before they cascade into major incidents. The market reflects this necessity; the global data observability market, valued at $2.94 billion in 2023, is projected to reach $5.27 billion by 2029. This growth is a direct response to the massive scale of modern data, where even minor errors can have outsized financial consequences. You can explore the market trends to see how quickly this space is growing.
Data observability is not just about faster error detection. It’s about establishing foundational trust in data assets, ensuring that every report, model, and decision is based on reliable, accurate, and timely information.
Data Monitoring vs. Data Observability at a Glance
To clarify the distinction, it helps to compare the two concepts. Monitoring answers questions you already know to ask (“Is the pipeline running on schedule?”). Observability provides the tooling to ask new questions when systems fail in unexpected ways.
This table breaks down the fundamental differences:
| Capability | Traditional Data Monitoring | Modern Data Observability |
|---|---|---|
| Focus | Answers known questions (e.g., “Is the job complete?”) | Explores unknown issues (e.g., “Why did this data arrive incomplete?”) |
| Approach | Reactive—alerts on predefined thresholds and known failure modes. | Proactive—automatically detects anomalies and unexpected behavior. |
| Scope | Often siloed, looking at individual components of a pipeline. | Holistic, providing end-to-end lineage and impact analysis across the entire system. |
| Outcome | Tells you that something is broken. | Tells you what broke, why it broke, and who is affected. |
While monitoring remains useful for verifying known system states, observability provides the deeper context required to navigate the unpredictable failures inherent in modern data systems.
The Six Pillars of a Resilient Data Observability Strategy
An effective data observability strategy provides a complete health assessment of your data ecosystem. It relies on six core pillars, each answering a critical question about the state and flow of your data. Neglecting any one of these pillars creates a significant blind spot where data downtime can occur.
Observability is an evolution of monitoring. Monitoring is reactive and limited; observability is proactive and comprehensive.
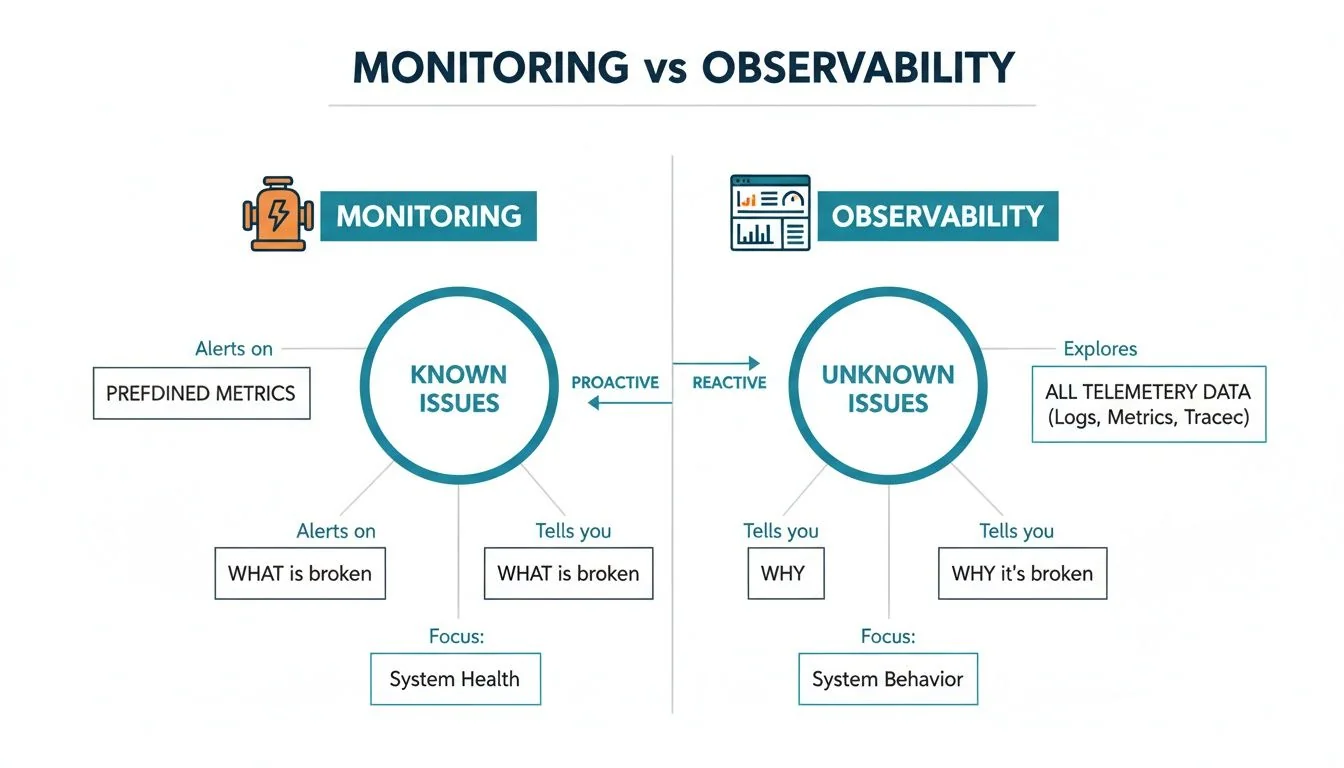
The key difference is that monitoring looks for predefined problems. Observability provides the tools to investigate problems you didn’t anticipate.
Let’s break down the six pillars that enable this deep understanding.
Freshness and Volume
Freshness and volume are the vital signs of your data pipelines. They confirm that data is arriving on time and in the expected quantities—foundational requirements for reliable analytics.
-
Freshness answers the question: “Is our data up to date?” If a daily sales report runs on 48-hour-old data, any decision based on it is flawed. Freshness checks ensure data is delivered within its required timeframe.
-
Volume asks: “Is our data complete?” If a pipeline that typically ingests 5 million customer events per day suddenly drops to 5,000, something is critically broken. This pillar detects when data is missing or when an upstream change has disrupted the expected flow.
Distribution and Schema
Distribution and schema are the structural integrity checks for your data. They ensure the data within tables is valid and that the tables themselves have not been altered unexpectedly.
An unexpected schema change is a common cause of data pipeline failure. An upstream change to a column (e.g., add, remove, or rename) can cause downstream dashboards and models to fail silently for hours or days without schema observability.
Distribution monitors the range and validity of values within a column. If a field for customer age suddenly contains negative numbers or shows a 95% null rate, it indicates data corruption—an issue a simple volume check would miss.
Schema observability tracks the structure of your data, alerting you to unapproved or undocumented changes to columns and data types. As data systems grow, managing data quality becomes untenable without automated tracking of these structural shifts.
Lineage and Anomalies
Finally, lineage and anomalies provide the deep context needed for rapid problem resolution. They connect dependencies and help identify the “unknown unknowns” that traditional monitoring cannot detect.
-
Lineage acts as a GPS for your data. It maps the entire journey of a data asset from its source to its consumption points. When a critical report breaks, lineage immediately reveals all upstream dependencies, reducing troubleshooting time from hours to minutes.
-
Anomalies serve as a safety net. This pillar typically uses machine learning to detect unusual patterns that do not violate predefined rules. It might flag a sudden spike in duplicate records or a subtle shift in the correlation between two key metrics, revealing hidden integrity issues before they become business problems.
A common point of confusion is how data observability fits with existing data quality and monitoring efforts. It is not a replacement but an evolution. Data observability encompasses quality and monitoring, providing context that makes them more effective and shifts a team from a reactive to a proactive posture.
Consider this healthcare analogy for your data ecosystem:
The Roles of Monitoring, Quality, and Observability
Data monitoring is the patient’s heart-rate monitor. It tracks a specific, known metric and alerts when it crosses a preset threshold (e.g., heart rate exceeds 150 bpm). In data, a monitor signals that a pipeline job failed or daily data volume dropped by 50%. It is effective for flagging known failure modes.
Data quality is the series of lab tests. These tests check for specific conditions against a set of defined rules. A blood test confirms cholesterol is within a healthy range, just as a data quality rule confirms a customer_id column contains no null values. It provides a clear pass/fail on whether data conforms to predefined standards.
Data observability is the full diagnostic workup from a team of specialists. They do not analyze symptoms or lab results in isolation. They understand how the entire system functions—from neurology to cardiology—to diagnose complex, interconnected problems and identify the true root cause.
This is the key distinction. Observability doesn’t just report a symptom (like a monitoring alert) or a failed test (like a quality check). It connects disparate signals to determine why the patient is experiencing fatigue, dizziness, and a low heart rate simultaneously. It helps you uncover the “unknown unknowns” that isolated checks would completely miss.
From Reactive Firefighting to Proactive Resilience
Observability does not make existing tools obsolete; it makes them more intelligent. A monitoring alert becomes the starting point for a deeper investigation. A failed quality check is no longer an isolated error but a symptom whose blast radius can be traced downstream using data lineage.
By layering observability on top of an existing stack, you build a deep, intuitive understanding of your entire data environment. This is why many organizations begin with foundational data pipeline monitoring tools and then expand into a full observability practice.
The goal is to shift from reactive incident response to proactive issue prevention, building a resilient data platform where trust is the default.
Measuring the Business Impact
Investing in new technology requires a clear line to business value. The impact of data observability is not abstract; it translates directly into measurable improvements for both technical teams and executive stakeholders. The key is to focus on operational and financial outcomes rather than technical jargon.
The most immediate gains appear in core data engineering metrics. These KPIs provide the quantitative evidence needed to build a compelling business case and demonstrate ROI.
Core Operational KPIs
- Mean Time to Detection (MTTD): How long does it take for your team to become aware of a data problem? Without observability, this can be days or weeks, often initiated by an end-user complaint. With a proper observability setup, MTTD can be reduced from hours to minutes.
- Mean Time to Resolution (MTTR): Once an issue is detected, how long does it take to resolve? This is where significant engineering time is lost. By providing instant root-cause analysis and end-to-end lineage, observability eliminates tedious manual investigation, drastically reducing MTTR.
- Reduced Data Downtime Hours: This is the ultimate bottom-line metric for data reliability. It calculates the total time data is incorrect or unavailable, directly tying observability to business continuity.
By instrumenting your data platform for observability, you are not just catching errors faster. You are systematically shrinking the window during which bad data can influence decisions, corrupt models, or break customer-facing products.
From Technical Metrics to Business Value
These operational improvements have a ripple effect across the organization, unlocking tangible business benefits. The efficiency gained is not merely about saving engineering hours; it’s about rebuilding and reinforcing trust in the company’s data assets.
This is why industry adoption is accelerating. Gartner predicts that by 2026, 50% of enterprises with distributed data architectures will use data observability, a significant increase from under 20% in 2024. This is a direct response to the “data downtime” crisis, which costs businesses an average of $15 million annually.
Companies that adopt observability early often report 40-60% faster issue resolution. This speed directly accelerates the delivery of analytics and AI projects. You can discover more insights about the best data observability tools in 2025.
This faster resolution translates directly into:
- Higher Data Team Efficiency: Engineers transition from reactive firefighters to proactive system builders, focusing on innovation instead of fixing broken pipelines and dashboards.
- Greater Trust in Analytics: When executive reports and BI dashboards are consistently reliable, business leaders can make faster, more confident decisions, ending debates about data trustworthiness.
- More Reliable AI Deployment: AI and machine learning models are highly sensitive to data quality. Observability acts as a safeguard, ensuring the data feeding these models is trustworthy, which reduces model drift and improves performance.
- Stronger Data Governance: With clear lineage and automated monitoring, enforcing data policies becomes simpler and more effective, reducing compliance risks.
A Practical Roadmap for Implementing Data Observability
Knowing you need data observability is different from implementing it. A phased, deliberate approach is essential to avoid being overwhelmed and to deliver early wins that build momentum.
This roadmap breaks the journey into four practical phases, providing a clear path to embedding data reliability within your organization.
Phase 1: Assess and Prioritize
First, focus your efforts where they will have the greatest impact. Not all data assets are equally critical, and attempting to monitor everything from day one is a recipe for failure.
Start by identifying your most critical data assets—the tables and pipelines that feed executive dashboards, financial reports, or customer-facing applications. Collaborate with business stakeholders to map these high-value data flows. This assessment creates a clear priority list and ensures your first observability project delivers a noticeable impact.
Phase 2: Pilot and Learn
With your priorities established, select one or two high-impact yet manageable pipelines for a pilot project. The objective is to prove value quickly and create a repeatable implementation blueprint. An ideal candidate is a system with known issues, such as a marketing analytics dashboard that frequently breaks.
During this phase, your team gains hands-on experience with the observability platform—interpreting alerts, tracing data lineage, and conducting root-cause analysis. Document key wins, particularly the reduction in time spent on incident resolution. This success story becomes the internal business case for a broader rollout.
Phase 3: Scale and Integrate
After a successful pilot, expand your coverage. Using the lessons learned, methodically instrument the other critical data assets identified in Phase 1. The key to this phase is integration. Embed observability directly into your team’s daily workflows.
This involves routing alerts to the appropriate Slack channels, connecting incident resolution processes to ticketing systems like Jira, and establishing the observability platform as a standard tool for every data engineer. To scale effectively, ensure your setup is compatible with a modern data stack designed for growing complexity.
A successful observability implementation is not just about the tool; it’s about making data reliability a shared responsibility. When alerts and insights are integrated into daily workflows, everyone from engineers to analysts begins to think proactively about data health.
Market projections underscore the urgency. The global data observability market is expected to reach $1.7 billion in 2025 and grow to $9.7 billion by 2034. This growth is driven by necessity: without these tools, 80% of enterprises report dealing with weekly pipeline failures. You can learn more about the data observability market drivers on Dimension Market Research.
Phase 4: Govern and Optimize
The final phase is about ensuring long-term data reliability. Formalize ownership and establish clear processes for managing data health. Assign explicit owners to key data assets and define Service Level Agreements (SLAs) for metrics like data freshness and quality.
From here, the process is one of continuous improvement. Regularly review and refine monitoring rules and alert thresholds to reduce noise and improve signal quality. The ultimate goal is to build a culture of data reliability where every team member is accountable for the quality of the data they produce and consume. This ongoing optimization ensures your observability practice evolves with your data platform.
Choosing the Right Data Observability Partner
Selecting a data observability partner is a critical decision. The right choice accelerates your path to reliable data; the wrong one can set your team back months. The market is crowded with vendors rebranding legacy monitoring tools as “observability” platforms. To cut through the marketing claims, use a structured, vendor-neutral evaluation framework.
The first criterion is seamless integration. An effective platform must connect directly to your existing data stack, whether it’s Snowflake, Databricks, BigQuery, or a hybrid environment. If a vendor requires significant re-engineering of your current pipelines, it is a major red flag.
Next, consider the end-users. Is the tool easy to use? An analyst must be able to quickly understand why a dashboard is incorrect, while an engineer needs powerful features for deep root-cause analysis. A complex, engineer-only interface will likely go unused, negating its value.
Evaluating Core Capabilities
Once you have confirmed stack compatibility and usability, examine the platform’s core intelligence. Dig into how its AI-powered anomaly detection functions. Does it simply alert on static thresholds, or does it learn the unique seasonal patterns of your data to suppress false positives?
A platform that generates constant, low-value noise is worse than no platform at all. It trains your team to ignore alerts, leading to the very data downtime you’re trying to prevent.
Focus your evaluation on these key capabilities:
- Scalability: Demand evidence that the solution can handle your current and future data volume and complexity without performance degradation or cost overruns.
- Automated Lineage: How effectively does it automatically map the end-to-end journey of your data? Manual lineage mapping is not a scalable solution.
- Alerting Intelligence: Can you customize alerts with rich context and route them to the appropriate teams via tools like Slack or PagerDuty? Generic, untargeted alerts are ineffective.
Ultimately, you are not just purchasing a dashboard. You are investing in a partnership to deliver reliable data. By adhering to these practical criteria, you can cut through the hype and select a platform that empowers your entire team to trust your data.
Frequently Asked Questions About Data Observability
Here are direct answers to common questions from leaders evaluating data observability.
What is the most common pricing model?
Most data observability platforms use a consumption-based model, with pricing typically tied to the number of tables monitored or the volume of data processed.
This model is generally advantageous, as it allows you to start small with critical assets and scale costs predictably as you expand coverage. Be wary of rigid, per-seat licenses, as they often do not align with how modern data teams operate.
Should we build our own solution or buy one?
This is the classic build-versus-buy decision. Building an in-house solution offers complete control but almost always becomes a significant resource drain. You are not just building a tool; you are committing to a long-term project requiring a dedicated team for maintenance, integrations, and ML model tuning.
Purchasing a specialized platform allows you to achieve value—finding and fixing data problems—much faster. It lets your data team focus on delivering business outcomes, not on becoming full-time tool developers.
What is the first step to get started?
Do not try to “boil the ocean.” The most effective starting point is to identify your single most critical data asset. Ask: “If one data product failed, what would cause the biggest business impact?”
Apply observability to that single, high-impact pipeline. This strategy provides a quick, tangible win that demonstrates immediate value and strengthens the business case for expanding the program.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis
Data Pipeline Cost Estimation Guide 2026
How much does a data pipeline cost to build and run? Complete breakdown by pipeline type, cloud platform, team model, and project scope — with rate benchmarks from 86 verified data engineering firms.

A Leader's Guide to Apache Spark Optimization: Moving Beyond Quick Fixes
Unlock performance with apache spark optimization strategies for faster jobs, smarter tuning, and cost savings across your data platform.

Data Contracts in Data Engineering: A Guide for Engineering Leaders
Explore data contracts in data engineering to enforce agreements, prevent pipeline failures, and boost data reliability across Snowflake and Databricks.