Parquet vs Avro: A Technical Guide to Big Data Formats

The choice between Parquet and Avro is a fundamental engineering decision based on a single trade-off: Parquet is a columnar storage format optimized for fast analytical queries, while Avro is a row-based format designed for efficient data ingestion and flexible schema evolution. Your decision depends on the primary workload: read-heavy analytics or write-heavy data streaming.
Choosing Your Data Format: Parquet vs Avro
In data engineering, the file format is a foundational choice that impacts query performance, storage costs, and architectural flexibility. The Parquet vs. Avro debate isn’t about a universal winner; it’s about matching the right tool to a specific technical requirement. A mismatch here leads to slow pipelines and inflated cloud infrastructure bills.
Parquet’s primary advantage is its columnar layout. By storing data in columns instead of rows, it enables analytical query engines like Apache Spark, Snowflake, and Databricks to read only the specific columns needed for a query, skipping irrelevant data. This significantly reduces I/O and accelerates performance for business intelligence (BI) and data science workloads.
Conversely, Avro’s row-based structure is engineered for high write throughput. It serializes an entire record at once, an efficient method for capturing event streams from sources like Apache Kafka. Its design, which tightly couples the schema with the data, provides robust support for schema evolution—a critical feature in dynamic environments where data structures change frequently.
Technical Recommendation: Use Parquet for analytical data stores like a data warehouse or data lakehouse, where query performance is the primary concern. Use Avro for the data ingestion layer, particularly in streaming architectures where write throughput and schema flexibility are critical.
High-Level Comparison
To make a sound technical decision, it’s essential to understand the core trade-offs. The optimal choice aligns with the primary workload—fast data reads for analysis or rapid data writes for ingestion.
This table provides a concise summary of the key differentiators between the two formats.
Parquet vs Avro Key Differentiators
| Criterion | Apache Parquet | Apache Avro |
|---|---|---|
| Storage Layout | Columnar (column-oriented) | Row-based (row-oriented) |
| Primary Use Case | Analytical queries, BI, data warehousing | Data serialization, event streaming (Kafka) |
| Query Performance | Excellent for analytical queries (reads a subset of columns) | Fair; slower for analytics as it must read entire rows |
| Write Performance | Slower due to columnar organization and sorting | Excellent due to simple append-only writes |
| Compression | Superior; groups similar data types for high compression ratios | Good; compresses entire rows, less effective than columnar |
| Schema Evolution | Supported but more rigid (schema is in the file footer) | Highly flexible; schema is part of the file, enabling easy evolution |
This comparison reinforces the central principle: Parquet is optimized for reading columns, while Avro is optimized for writing rows. This distinction is the key to selecting the appropriate format for your data pipeline.
How Storage Architecture Impacts Performance
The most significant difference between Parquet and Avro is their physical data layout on disk. This architectural choice dictates performance characteristics, storage costs, and optimal use cases. One is designed for high-performance analytics, the other for efficient record writing.

Understanding the columnar versus row-based distinction is the critical first step in choosing the right format for a given task.
Parquet’s Columnar Storage Advantage
Parquet organizes data using a columnar storage strategy. Instead of writing data out one full row at a time, it groups all the values from a single column together. For a customer table, all customer_id values are stored in one block, all email_address values in another, and so on.
This layout is highly effective for analytical (OLAP) queries. When an engine executes a query like SELECT AVG(order_value) FROM sales, it can read the order_value column data directly. It completely skips the bytes on disk holding customer_id, product_name, and all other unnecessary columns, which dramatically reduces I/O.
Key Insight: Parquet’s columnar layout is the foundation of modern analytics performance. It allows query engines to read only the required columns, minimizing data scanning. In cloud environments, less data scanned means faster queries and lower compute costs.
This capability, known as projection pushdown, is why Parquet is the de facto standard for data warehouses and lakehouse platforms like Snowflake and Databricks. For a deeper look at this architecture, our guide on Databricks Delta Lake explains how it leverages Parquet’s strengths.
Consider this simple customer dataset:
Customer Data Example
| Customer ID | City | |
|---|---|---|
| 101 | [email protected] | New York |
| 102 | [email protected] | London |
| 103 | [email protected] | Tokyo |
With Parquet, the data on disk is conceptually organized with each column’s values grouped together:
- Customer ID Block:
[101, 102, 103] - Email Block:
["[email protected]", "[email protected]", "[email protected]"] - City Block:
["New York", "London", "Tokyo"]
Avro’s Row-Based Storage Efficiency
Avro uses a row-oriented (or row-based) storage model. It serializes and stores an entire record—with all its fields—as a single, continuous block of data. Using the same customer example, Avro writes each complete row sequentially.
This method is highly efficient for write-heavy systems that process whole records at once. It is ideal for event streaming with tools like Apache Kafka, where producers continuously emit new, complete events. Avro simply appends the next serialized record to the file, a low-overhead operation.
For Avro, the physical layout would be:
[101, "[email protected]", "New York"][102, "[email protected]", "London"][103, "[email protected]", "Tokyo"]
While this structure facilitates fast writes, it creates a significant bottleneck for analytics. To calculate the average order_value from an Avro file, a query engine must read and deserialize every row—including all irrelevant columns—to access the one required field. This makes Avro substantially slower than Parquet for most analytical workloads.
Gauging Analytical Query Speed and Cost
For analytics, query speed is a direct driver of cloud costs and team productivity. This is where the architectural difference between Parquet and Avro is most pronounced. Parquet’s columnar structure is specifically engineered for analytical query performance, resulting in lower compute costs and faster insights.

The performance delta is not trivial; it is a fundamental advantage that modern data platforms like Spark, Snowflake, and Databricks are designed to exploit.
Parquet’s Engine for Speed: Projection Pushdown
The key to Parquet’s analytical speed is projection pushdown. Because data is stored in columns, a query engine reads only the specific columns required to answer a query. For a table with 200 columns where an analysis requires only three, the engine physically reads just those three columns from disk, ignoring the other 197.
An Avro-based query, in contrast, forces the engine to process every byte of every row to extract the same three columns. This dramatic reduction in I/O with Parquet means less data is scanned from cloud storage and loaded into memory, resulting in significantly faster and cheaper queries. Our detailed comparison of Snowflake vs Databricks examines how these platforms are optimized for columnar formats.
Filtering Data Efficiently with Predicate Pushdown
Parquet also employs predicate pushdown. Parquet files are organized into blocks of rows called row groups, each containing metadata such as the minimum and maximum values for each column within that block.
When a query includes a filter like WHERE order_date > '2025-11-01', the query engine first examines this metadata. If a row group’s min/max date range does not overlap with the query’s filter, the engine skips that entire block of data without reading it. This intelligent filtering prevents large volumes of irrelevant data from being processed.
Key Insight: Predicate and projection pushdown are the core mechanisms for columnar performance. Projection pushdown reduces the width of data read (fewer columns), while predicate pushdown reduces the length (fewer rows). Avro, being row-based, cannot support these critical optimizations effectively.
Benchmarking the Performance and Cost Impact
These architectural advantages produce measurable gains. Parquet’s columnar design consistently delivers 2-10x faster query performance than row-based formats like Avro, particularly for analytics on wide tables where only a subset of columns is queried. In benchmarks on datasets with nearly 60 million events, Avro took 7.46 seconds to run queries by scanning 7.51 GB of data. Parquet completed the same task in just 3.86 seconds, scanning only 5.39 GB. You can review the full research about these performance findings for more details.
This performance improvement directly impacts cloud expenditure. Since cloud data platforms bill based on compute time or data scanned, Parquet delivers:
- Lower Compute Costs: Shorter query execution times reduce virtual warehouse or cluster bills.
- Reduced I/O Charges: Fewer read operations from cloud storage like Amazon S3 or Google Cloud Storage result in lower API costs.
- Faster Time-to-Insight: Analysts and data scientists obtain results more quickly, accelerating business processes.
For any analytical workload, from BI dashboards to ad-hoc data exploration, choosing Parquet over Avro is a sound engineering decision. Its design directly addresses the core challenges of big data analytics, providing a faster, more cost-effective foundation for your data lake or lakehouse.
Comparing Storage Footprints and Compression
Beyond query speed, storage efficiency directly impacts cloud costs. In a direct comparison, Parquet almost always has a smaller storage footprint than Avro. This is a direct consequence of its columnar architecture.

This efficiency is a cornerstone of cost optimization in large-scale data platforms. For a data lakehouse, where storage is a primary cost, this becomes even more critical. The reason for Parquet’s advantage lies in how compression algorithms interact with the data layout.
How Columnar Layout Maximizes Compression
Compression algorithms like Snappy and Gzip work by identifying and reducing repetition. They scan data for repeating patterns and replace them with small references, which shrinks the file size. The more uniform the data, the more patterns they find, and the higher the compression ratio.
Parquet’s columnar layout is ideal for this process. It groups all values from a single column together—for instance, all user_country values or every event_timestamp. This creates long, homogenous blocks of data of the same type, often containing similar values. For a compression algorithm, this low-entropy data is highly compressible.
Avro’s row-based structure, in contrast, stores each record as a mix of different data types: an integer ID, a string email, a timestamp, and perhaps a boolean flag. This heterogeneity within each row makes it difficult for compression algorithms to identify repeating patterns, leading to less effective compression and larger files.
Key Takeaway: Parquet’s compression advantage is a direct result of its columnar design. Grouping similar data types creates homogenous data blocks that compression algorithms can shrink far more effectively than Avro’s mixed-type rows.
Benchmarking the Storage Savings
This architectural difference is reflected in performance metrics. Real-world tests consistently show Parquet achieving superior compression ratios. In one benchmark processing 59.7 million events, the Parquet files occupied 4.2 GB, while the Avro files required 6.7 GB—a 37% storage saving.
Another test with 18.5 million events demonstrated the same pattern: Parquet files consumed 1.3 GB compared to Avro’s 2.1 GB, giving Parquet a 38% advantage in space efficiency. A complete Athena performance comparison provides further details on these findings.
This is not merely about saving disk space. Smaller files result in less data to transfer over the network and less data for query engines to read from disk, which contributes to the faster query performance discussed earlier.
Translating Compression into Financial Impact
A 30-40% reduction in storage has a significant financial impact at petabyte scale. Consider a realistic scenario for a large organization.
Scenario: A 1 Petabyte (PB) Data Lake
Assumptions:
- Total Data Size: 1 PB (1,000 TB)
- Cloud Storage Cost: $23 per TB/month (a standard rate for major cloud providers)
- Parquet Storage Savings: A conservative 35% advantage over Avro
The annual costs are as follows:
| Format | Storage Required | Monthly Cost | Annual Cost |
|---|---|---|---|
| Avro | 1,000 TB | $23,000 | $276,000 |
| Parquet | 650 TB | $14,950 | $179,400 |
| Annual Savings | $96,600 |
By choosing Parquet, this organization saves nearly $100,000 annually on storage for every petabyte of data managed. As data volumes grow, these savings scale accordingly, making Parquet an essential tool for managing the economics of a modern data platform. Understanding the architectural differences between a data warehouse vs a data lake is also fundamental to optimizing both cost and performance.
Write Speed and Schema Evolution: Where Avro Shines
While Parquet is the standard for analytical queries, the focus shifts when write performance and schema flexibility are the primary requirements. This is Avro’s domain. In a Parquet vs. Avro comparison, Avro’s design for high-speed data ingestion and management of evolving data models sets it apart.
For systems that must capture data as it is generated, such as in real-time event streaming, Avro’s design provides a distinct advantage.
Avro’s Edge in Write Throughput
Avro’s row-based layout is inherently faster for writes. When a new record arrives, Avro serializes the entire row and appends it to the end of the file. This is a simple, low-overhead operation that maximizes throughput, making it ideal for high-velocity data streams.
Parquet, in contrast, requires more processing. To maintain its columnar structure, it must buffer incoming records, sort them by column, and then write them into organized row groups. This internal management consumes additional CPU and memory, creating latency that can become a bottleneck in real-time ingestion pipelines.
The Bottom Line: Avro writes are simple appends, making the format extremely fast for ingestion. Parquet writes require buffering and sorting to construct columnar blocks, an inherently slower process. This is the critical difference for any write-heavy workload.
This design choice is why Avro is the standard for data serialization in Apache Kafka. In event-driven architectures, capturing every message with minimal delay is paramount. Avro’s write efficiency aligns perfectly with Kafka’s high-throughput requirements.
The Make-or-Break Role of Schema Evolution
Beyond write speed, Avro’s most critical feature is its robust handling of schema evolution. In modern, agile environments, data structures are dynamic; new fields are added, old ones are retired, and data types may change. Avro was designed to manage this reality without breaking data pipelines.
Avro includes the writer’s schema with the data. This allows a consumer application to use its own schema (the “reader’s schema”) to interpret the data, ensuring compatibility between different versions. This system supports several key compatibility modes:
- Backward Compatibility: Data written with a new schema can be read by applications using an older schema, provided new fields have default values.
- Forward Compatibility: Data written with an old schema can be read by applications expecting a new schema. This works when fields have been removed, as the new reader can ignore the missing data.
- Full Compatibility: The schemas are both backward and forward compatible, allowing producers and consumers on different versions to exchange data seamlessly.
This flexibility prevents the brittle pipelines that can occur with more rigid formats. When a microservice adds a new field to an event, downstream consumers continue to function. While Parquet supports schema evolution, it is less flexible. Its schema is stored once in the file footer, and changes like reordering columns or complex type modifications are more difficult to manage.
Ultimately, write performance is Avro’s primary strength, solidifying its position as the top choice for real-time data ingestion and event-driven systems. It achieves faster write throughput by avoiding the computationally expensive task of reorganizing data into columns. For systems handling continuous streams from Kafka pipelines, event logs, or sensor data, this efficiency is a core operational requirement. You can learn more about why Avro is a great fit for ingestion pipelines.
Making The Right Choice For Your Use Case
The decision between Parquet and Avro depends on a single question: is the pipeline’s primary function reading data or writing it? The wrong choice can lead to performance bottlenecks and unnecessarily high cloud costs.
This video from a data engineering expert breaks down the core trade-offs in a practical manner.
The decision tree below illustrates the fundamental logic, focusing on each format’s primary strengths: write speed and schema flexibility versus analytical query performance.
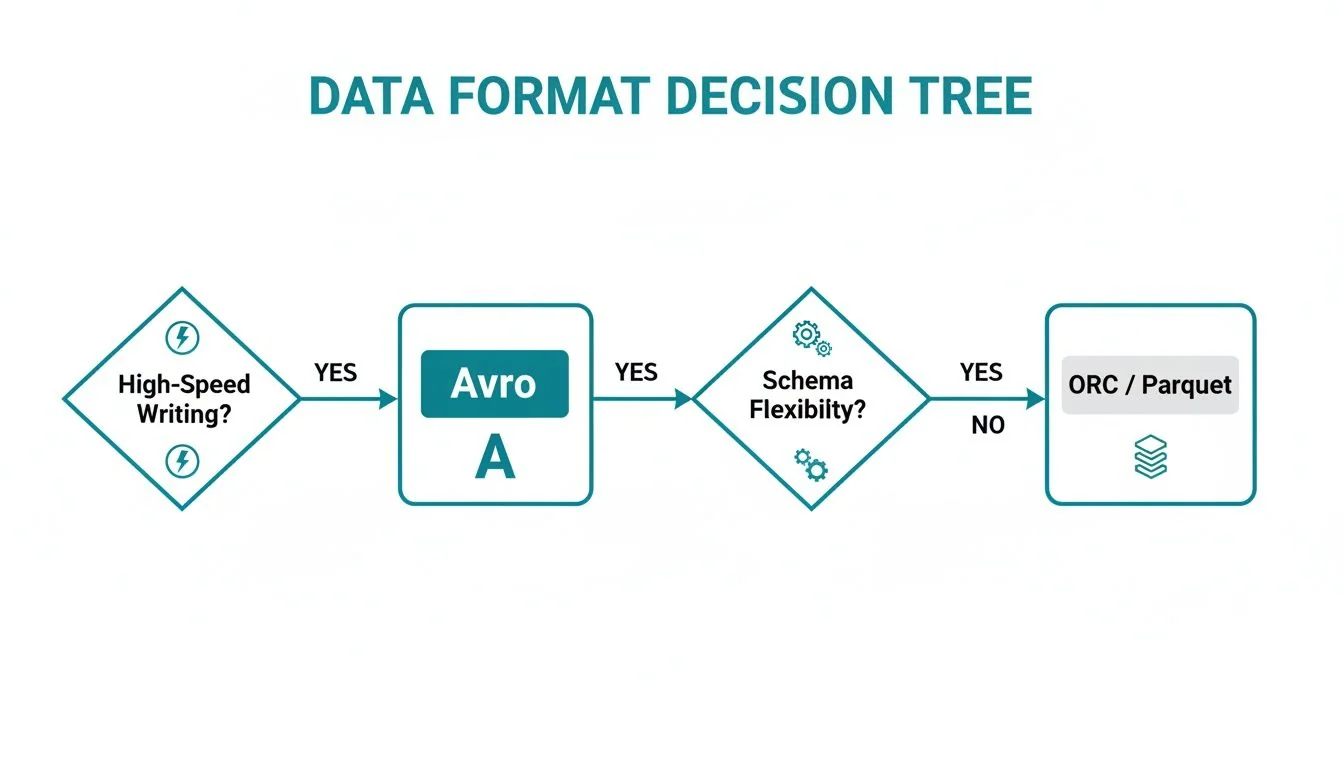
If the primary challenges are write throughput or managing evolving data structures, Avro is typically the correct choice.
Analytics And Data Warehousing: Parquet’s Home Turf
For any workload centered on analytical queries, business intelligence, or ad-hoc data exploration, Parquet is the clear winner. Its columnar layout is designed for the read-heavy patterns of modern data platforms like Snowflake and Databricks.
Use Parquet when:
- Powering BI Dashboards: Tools like Tableau or Power BI benefit from Parquet’s fast column scanning, which ensures responsive visualizations.
- Running Ad-Hoc Analytical Queries: Data scientists and analysts experience significantly reduced query times.
- Building a Cost-Effective Data Lakehouse: Parquet’s high compression and efficient data access reduce both storage and compute costs, making it the foundation of modern data lakehouse architectures.
Event Streaming And Data Ingestion: Where Avro Shines
For workloads focused on real-time data capture and pipeline resilience, Avro is the go-to choice. Its row-based structure is engineered for fast writes and flexible schema management.
Choose Avro for:
- Real-Time Event Streaming with Kafka: Avro is the de facto standard for serializing messages in Apache Kafka, due to its low write latency and robust integration with schema registries.
- Creating a Raw Data Landing Zone: Avro’s schema evolution capabilities allow ingestion pipelines to handle changes from diverse sources without failing.
- Handling Inter-Service Communication: In microservices architectures, Avro provides a reliable data contract that allows producers and consumers to evolve their schemas independently.
This decision matrix provides clear recommendations for common data engineering scenarios.
Decision Matrix For Data Formats
| Use Case | Recommended Format | Key Rationale |
|---|---|---|
| BI & Interactive Analytics | Parquet | Columnar reads are extremely fast for the selective queries that power dashboards. |
| Real-Time Event Ingestion | Avro | Optimized for high-throughput writes and flexible schema evolution, ideal for Kafka streams. |
| Data Science & ML Features | Parquet | Efficiently reads only the specific columns (features) required for model training and inference. |
| Raw Data Lake Staging Zone | Avro | Handles evolving schemas from diverse sources without breaking ingestion pipelines. |
| Archival & Cold Storage | Parquet | Achieves the highest compression ratios, significantly reducing long-term storage costs. |
| ETL/ELT Intermediate Steps | Avro or Parquet | Depends on the step. Avro is better for row-level transformations; Parquet excels at aggregations. |
The optimal choice depends on the specific stage in the data lifecycle. A single format is rarely sufficient for an entire end-to-end platform.
Key Insight: An optimal strategy is rarely “either/or.” Modern data engineering uses a hybrid approach, leveraging each format’s strengths to build efficient, multi-stage pipelines.
The Hybrid Approach: A Modern Best Practice
The most effective data architectures today utilize a multi-stage pipeline that combines the strengths of both formats. In this model, Avro is used for initial ingestion, and Parquet is the final, optimized format for analytics.
This common architecture works as follows:
- Ingestion (Avro): Raw event data is captured from sources like Kafka and landed in a staging area of the data lake as Avro files. This stage prioritizes write speed and schema flexibility at the entry point.
- Transformation and Storage (Parquet): A batch or micro-batch process, often using Apache Spark™, reads the raw Avro data. It then cleans, transforms, and rewrites it into a partitioned Parquet structure for an optimized storage layer.
- Analytics (Parquet): All downstream consumers—analytical queries, BI tools, and machine learning models—query the optimized Parquet data, taking full advantage of its high-performance columnar reads.
This Avro-to-Parquet pipeline provides the benefits of both formats: high-throughput, resilient data ingestion coupled with fast, cost-effective analytics. When evaluating Parquet vs Avro, this hybrid model is often the most powerful and practical solution for a modern data stack.
Frequently Asked Questions
Common questions about Parquet and Avro arise during data platform development. Here are clear, practical answers.
Can I Use Parquet With Kafka?
While technically possible, it is an anti-pattern to be avoided. Kafka is designed for streaming a high volume of events with minimal delay. Avro’s simple, row-by-row serialization is optimized for this purpose.
Writing Parquet files directly from a Kafka stream introduces significant latency. Parquet needs to buffer data, sort it into columns, and then write it out—a process that undermines the real-time nature of Kafka.
The Field-Tested Approach: Use Avro for your Kafka topics. It is fast, efficient for writes, and integrates well with schema registries. The standard best practice is to land raw Avro events in a staging zone (e.g., S3 or ADLS) and then use a batch or micro-batch job to convert the data into Parquet for analytical workloads.
Which Format Do Databricks and Snowflake Prefer?
Both Databricks and Snowflake are unequivocally optimized for Parquet. Their query engines are engineered to leverage Parquet’s columnar structure.
This enables high-performance features like predicate pushdown (reading only necessary rows) and projection pushdown (reading only necessary columns). If they were to process Avro, their engines would have to read every row from start to finish, which would degrade performance and increase compute costs. For analytics in any modern lakehouse or data warehouse, Parquet is the native format.
How Different Is Schema Evolution in Practice?
The difference is substantial and directly impacts the resilience of data pipelines. Avro was designed for environments with frequently changing schemas.
Because Avro embeds the writer’s schema with the data, downstream consumers can handle new, missing, or renamed fields without failing. This flexibility is essential when ingesting raw data from multiple, uncontrolled sources.
Parquet’s schema evolution is stricter. While it handles the addition of new columns well, more complex changes can be problematic. This rigidity makes Parquet better suited for final, curated datasets that have been cleaned, transformed, and structured for analysis. The Parquet vs Avro decision often comes down to this trade-off: flexibility for ingestion versus structure for analytics.
Navigating the complexities of data engineering requires the right partners. DataEngineeringCompanies.com offers expert rankings and practical tools to help you confidently select top-tier data engineering firms for your next project. Find your ideal data engineering partner today.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Databricks Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A Leader's Guide to Apache Spark Optimization: Moving Beyond Quick Fixes
Unlock performance with apache spark optimization strategies for faster jobs, smarter tuning, and cost savings across your data platform.

Data Contracts in Data Engineering: A Guide for Engineering Leaders
Explore data contracts in data engineering to enforce agreements, prevent pipeline failures, and boost data reliability across Snowflake and Databricks.

A Data Lineage Tools Comparison Framework for Engineering Leaders
Cut through the noise with this data lineage tools comparison. Evaluate top vendors on architecture, integration, and pricing for your modern data platform.