Data Lakehouse vs Data Mesh: A 2026 Decision Guide

Your CTO asks a simple question: should we standardize on a lakehouse, or move to data mesh? The wrong answer locks you into the wrong team design as much as the wrong platform. That’s why the usual architecture diagrams miss the core issue.
Most leadership teams hit this decision at the same moment. The central data team has become a queue manager for the rest of the company. Product, finance, operations, and AI teams all want faster access to data. At the same time, nobody wants a sprawl of poorly governed pipelines across Snowflake, Databricks, dbt, Airflow, and three cloud accounts.
What follows isn’t a definitional tour. It’s a buyer’s guide for engineering leaders making a platform and consulting decision under real delivery pressure.
The Strategic Crossroads Facing Every Data Leader
A common pattern shows up in enterprise modernization programs. The company has already invested in cloud data infrastructure on AWS, Azure, or GCP. It has some mix of warehouse workloads, raw object storage, and orchestration. It has also learned that centralization solves one class of problems and creates another.
A data lakehouse appeals to the CTO who wants one governed platform, one storage backbone, and fewer duplicated pipelines. A data mesh appeals to the CTO who wants each business domain to stop waiting on a central team. The decision sounds technical, but it determines who owns quality, who funds platform work, and who gets blamed when AI initiatives stall.

If you’re resetting your architecture, it helps to start from a modern data strategy rather than from tooling preferences. The architecture has to follow the operating model you can sustain.
The real tension is operational
The lakehouse choice says: build a strong platform core, enforce standards centrally, and drive efficiency through shared storage, governance, and compute patterns.
The mesh choice says: give domains ownership, force data product accountability closer to the business, and accept that governance has to become federated rather than fully centralized.
| Decision dimension | Lakehouse bias | Data mesh bias |
|---|---|---|
| Primary bottleneck | Central platform fragmentation | Central team backlog |
| Operating model | Shared platform with central stewardship | Domain ownership with federated standards |
| Talent pattern | Strong platform engineering bench | Domain-aligned engineers and product-minded data owners |
| Consulting need | Migration, optimization, governance implementation | Org redesign, self-serve platform, domain enablement |
| Failure mode | Efficient platform, slow business response | Fast domains, inconsistent quality |
The architecture debate is usually a proxy for an org design problem. If you don’t resolve the org question first, the platform decision won’t hold.
An Architectural and Technology Stack Deep Dive
The technical stack matters because the implementation burden differs sharply. In a lakehouse, the platform team unifies storage, metadata, security, and processing patterns. In a mesh, the platform has to support decentralization without turning every domain into its own infrastructure shop.
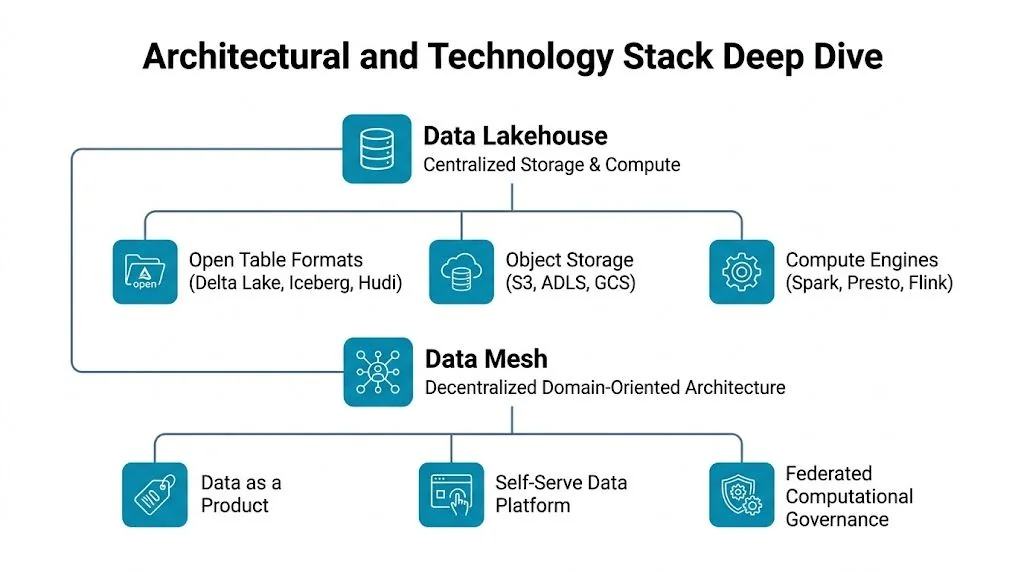
What a lakehouse actually looks like in production
A modern lakehouse usually sits on object storage such as S3, ADLS, or GCS, with open table formats such as Delta Lake, Apache Iceberg, or Apache Hudi. Compute comes from engines such as Spark, Flink, or Presto-family query layers. Governance sits in a catalog and policy layer. In practice, that often means Databricks with Unity Catalog, or a Snowflake-centered model with native governance and external table patterns.
The technical reason enterprises like it is straightforward. According to QodeQuay’s architecture analysis, lakehouses support ACID transactions, schema evolution, time travel, and optimized storage formats, which lets teams run BI reporting and ML training on the same dataset without duplication. The same analysis notes that tuning techniques like Z-ordering, bloom filters, secondary indexing, and materialized views can improve query performance, though lakehouses can still lag purpose-built warehouses for purely structured workloads by 20% to 50% in some cases.
That trade-off is easy to miss in consulting proposals. A partner can sell “one platform for everything,” but your finance reporting workloads may still need careful modeling, clustering, and compute isolation to perform predictably.
For a more detailed technical primer on platform design, this guide to lakehouse architecture patterns is useful before you write an RFP.
Practical rule: If your consulting partner can’t explain partitioning, table maintenance, workload isolation, and catalog design in concrete terms, they aren’t ready to lead a serious lakehouse migration.
What a mesh actually requires
A data mesh isn’t a storage engine. It’s a way of assigning responsibility. Domain teams own data products. A central enablement team provides shared capabilities such as cataloging, identity controls, lineage, templates, observability, and platform standards.
That means the technology stack is broader and less uniform. You still use storage and compute somewhere, often on Databricks, Snowflake, BigQuery, or a mix. But you also need product interfaces, metadata standards, discoverability, reusable dbt patterns, orchestration templates in Airflow or managed equivalents, and governance automation that domain teams can use without waiting for the center.
If your team is comparing implementation paths, this review of data pipeline tools is a practical supplement because the architecture choice changes which orchestration, transformation, and observability tools become first-class.
The hidden implementation issue
The hard part in data lakehouse vs data mesh isn’t choosing between Databricks and Snowflake. It’s deciding where engineering complexity should live.
- In a lakehouse, complexity sits in platform design, optimization, and shared governance.
- In a mesh, complexity sits in domain enablement, interface contracts, and federated standards.
- In both cases, dbt, orchestration, and governance tooling only work if ownership boundaries are explicit.
The strongest consulting teams know this and design delivery around operating responsibilities, not just around Terraform modules and ingestion accelerators.
Comparing Ownership and Governance Models
The biggest difference between these models is governance. Not governance as policy documents. Governance as daily control over schemas, SLAs, quality checks, and release decisions.

Lakehouse governance is centralized by design
In a lakehouse model, the platform team typically owns ingestion standards, storage conventions, identity and access patterns, data quality frameworks, and curated serving layers. Domain teams consume and sometimes contribute, but the center defines the contract.
This works well in regulated environments and in organizations where the business already expects shared services. It also fits Snowflake and Databricks programs where leadership wants a controlled migration from fragmented marts and legacy ETL.
The upside is clarity. The downside is queue formation. Every exception request lands with the same platform team.
Mesh governance is federated and heavier to operate
According to Starburst’s comparison of data mesh and data lakehouse, data mesh prioritizes decentralized socio-technical scalability by distributing ownership to domain teams and can reduce ingestion delays by 30% to 50% in large organizations through distributed ETL. The same analysis is equally clear about the cost of that model: mesh requires higher organizational maturity and domain owners who can ensure data product quality.
That sounds attractive until you staff it. Someone in each domain has to own semantics, documentation, lifecycle decisions, and producer-consumer agreements. That person isn’t just a data engineer. They need enough business context to act like a product owner.
Here’s the governance split in practical terms:
-
Lakehouse governance
- Who sets standards: Central platform and governance leads
- Who enforces quality: Usually central engineering with shared checks
- Who resolves disputes: Platform leadership or architecture board
-
Mesh governance
- Who sets standards: Small federated governance group
- Who enforces quality: Domain teams
- Who resolves disputes: Cross-domain governance forum with executive backing
A useful reference point for leaders designing those controls is this guide to data governance strategies, especially if your consulting scope includes operating model design rather than only platform build-out.
The video below is worth sharing with architecture and product leaders together, not just the data team, because mesh fails when the business treats data ownership as somebody else’s problem.
In a lakehouse, governance is a platform competency. In a mesh, governance is a management discipline.
Enterprise Performance and Cost Implications
CTOs usually ask about storage and compute first. That’s reasonable, but incomplete. The larger cost difference often comes from who you need to hire, how many teams need to coordinate, and how much rework appears after the first release.
Where lakehouses win financially
Lakehouses are winning current enterprise adoption because they package performance and governance into a migration path most organizations can execute. The 2025 comparative study in the International Journal of Innovative Research in Management and Physical Sciences reports a 50% reduction in data processing time and a 30% improvement in data processing efficiency for lakehouse implementations. The same study says 33.6% of organizations treat lakehouses as a strategic priority for unified BI and ML workloads, 67% of organizations expect lakehouses to handle the majority of analytics within three years, and 19% of respondents cite cost efficiency as the main reason for adoption.
Those numbers matter because they map directly to consulting economics. A lakehouse migration usually lets one partner deliver storage redesign, ingestion consolidation, governance setup, and workload optimization within one program structure. That lowers coordination overhead.
Where mesh gets expensive
Mesh doesn’t just add tooling. It adds operating layers. You need self-serve templates, metadata controls, enablement, domain onboarding, and an escalation model for cross-domain quality disputes. If your consulting partner prices mesh close to a straightforward lakehouse migration, they’re underestimating the work or implicitly assuming your internal teams will absorb it.
The cost issue isn’t only day one. Mesh spreads engineering responsibility deeper into the organization, which improves responsiveness when domain teams are mature. It becomes wasteful when domains don’t have enough technical depth to own pipelines and data products properly.
The budget question CTOs should ask
Ask vendors where they expect your marginal cost to rise after go-live.
- For lakehouse programs, primary cost risk sits in compute optimization, table maintenance, and a central team becoming a delivery choke point.
- For mesh programs, primary cost risk sits in duplicated effort across domains, uneven quality practices, and the need for stronger senior hiring in each business unit.
- For both, migration cost is less important than the operating model you can afford for three years.
The blunt assessment: if your main objective is platform consolidation on Snowflake or Databricks with better BI and AI readiness, lakehouse usually delivers the cleaner economic case. If your main objective is reducing central backlog across many independent business units, mesh can justify its higher organizational burden.
Choosing Your Path Ideal Use Cases and Anti-Patterns
Architects get into trouble when they treat both models as equally valid for every enterprise. They aren’t.
Choose lakehouse when the platform has to unify before it can scale
A lakehouse is the stronger choice when you’re consolidating fragmented analytics stacks, rationalizing storage, or trying to support BI and ML from one governed data foundation. It fits especially well when:
- Your organization is still platform-led. A central data team already owns standards and can enforce them.
- Your industry is compliance-heavy. Central policy enforcement and auditability matter more than domain autonomy.
- You’re modernizing to Databricks or Snowflake. The migration path aligns with how these platforms are bought, staffed, and governed.
- Your consulting scope is execution-heavy. You need pipeline migration, medallion-style modeling, dbt adoption, orchestration cleanup, and governance rollout.
Anti-patterns show up fast. Don’t force a lakehouse-first model when business units already behave like independent product organizations with their own engineering leadership and hard delivery deadlines. You’ll centralize cost, then decentralize work through side channels anyway.
Choose mesh when your bottleneck is organizational, not storage
Mesh becomes the better fit when your core problem is that a central team can’t keep up with domain demand and shouldn’t try to. It works best when:
-
Business units already own engineering outcomes Data ownership maps naturally to existing product or domain structures.
-
Data products differ materially by domain Finance, operations, risk, and customer platforms need different semantics, SLAs, and release cadences.
-
You can fund enablement, not just infrastructure Mesh only works when the platform team builds guardrails, templates, discovery, and federated governance support.
The anti-pattern is common: a mid-sized company with one data team, limited senior talent, and no appetite for domain ownership decides to “do data mesh” because it sounds modern. That usually creates duplicated pipelines, inconsistent definitions, and a catalog full of untrusted assets.
If your leaders won’t assign named business-domain owners for data products, you don’t have a mesh plan. You have a decentralization slogan.
The consulting implication
Lakehouse projects need consultants who can migrate and optimize platforms. Mesh programs need consultants who can redesign operating models, not just infrastructure. That’s a different kind of partner. Many firms can implement Airflow, dbt, Databricks, and Snowflake. Fewer can coach domain teams, define federated governance, and leave behind a workable product model for data.
The Emerging Reality The Lakehouse-Mesh Hybrid
The strict data lakehouse vs data mesh framing no longer reflects where enterprise programs are going. The market is moving toward hybrid models that use lakehouse as the technical foundation and mesh as the ownership model.
The strongest evidence comes from Databricks’ analysis of lakehouse and data mesh adoption. It reports that hybrid lakehouse-mesh adoption surged 150% in 2025 for AI/ML pipelines, and that 40% of Databricks’ top global customers now run a mesh concept on top of a lakehouse foundation. The same analysis says this approach boosts scalability 4x, and notes that Unity Catalog updates for federated governance cut cross-domain access latency by 70%.
Why the hybrid model is winning
This structure solves the central contradiction.
The lakehouse gives you shared storage, open table formats, ACID behavior, and common governance primitives. The mesh model tells you who owns which data product, who publishes it, and who is accountable when quality slips. One handles the technical substrate. The other handles the operating model.
That’s why the hybrid path is becoming the sensible recommendation for large Snowflake and Databricks migrations. It avoids two bad extremes:
- Pure centralization, where every team waits on the same platform group
- Pure decentralization, where domains reinvent standards and multiply integration work
What this means for consulting engagements
A hybrid program changes what you should buy from a partner. Don’t ask for “lakehouse implementation” or “data mesh transformation” as isolated workstreams. Ask for a phased model:
-
Foundation phase Central storage, catalog, security model, CI/CD, baseline orchestration, shared quality tooling
-
Domain enablement phase Templates for data products, ownership model, documentation standards, service boundaries
-
Federation phase Cross-domain governance, discoverability, SLA management, escalation rules
The right partner for a hybrid model can talk credibly about both Unity Catalog or Snowflake governance primitives and the non-technical mechanics of domain accountability.
Your Decision Framework An RFP-Ready Checklist
Most RFPs fail because they ask vendors to compare platforms without forcing an honest assessment of the client’s operating model. Use this checklist before you issue the brief.
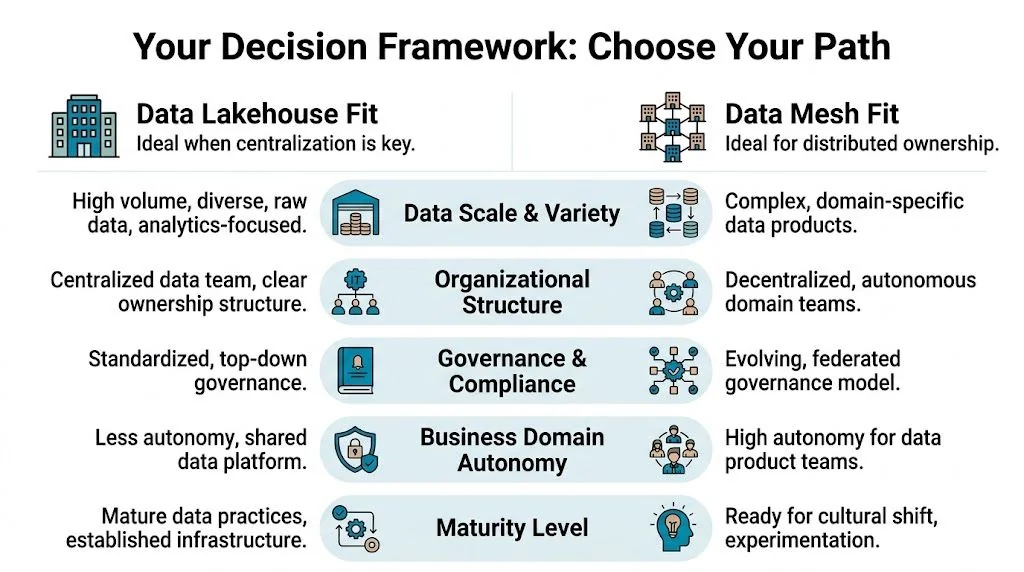
Score the organization before you score the vendors
| Evaluation area | Leans lakehouse | Leans mesh |
|---|---|---|
| Org structure | Centralized data or platform authority | Strong domain autonomy across business units |
| Primary goal | Consolidation, governance, cost control | Speed, local accountability, parallel delivery |
| Talent model | Strong platform engineers, fewer domain data owners | Senior domain engineers and product-minded owners |
| Governance style | Top-down standards and approvals | Federated standards with local enforcement |
| Workload pattern | Unified BI, reporting, shared ML datasets | Domain-specific products and local SLAs |
| Partner requirement | Migration and optimization depth | Change management and operating model depth |
Questions to put into the RFP
Don’t ask vendors whether they “support” both architectures. Everyone says yes. Ask these instead:
-
Ownership design Who owns data quality, schema evolution, and product documentation after go-live?
-
Platform boundary Which controls stay centralized, and which responsibilities move to domains?
-
Tooling fit How will the vendor implement dbt, orchestration, cataloging, lineage, and observability under the chosen model?
-
Talent transfer Which roles must the client hire or backfill for the architecture to survive beyond the consulting engagement?
-
Failure handling What happens when one domain publishes low-quality data that another domain depends on?
The decision rule I’d use with a client CTO
Pick lakehouse if your enterprise needs a governed common platform now, and your domains aren’t staffed to act as data product teams.
Pick mesh if your business units already run with meaningful autonomy, and leadership is willing to assign durable accountability for data products inside those units.
Pick hybrid if you’re a large enterprise on Snowflake or Databricks and need central technical standards with distributed ownership.
The wrong move is buying a mesh story from a vendor that only knows centralized platform delivery, or buying a lakehouse migration from a vendor that ignores the backlog problem driving the change.
Frequently Asked Questions for Engineering Leaders
Can we start with a lakehouse and evolve toward mesh
Yes. In fact, that’s the cleaner path for many enterprises. Start by standardizing storage, governance, and core pipelines. Then move selected domains toward data product ownership once the shared platform is stable. This sequence reduces technical sprawl while giving leadership time to test whether domains will actually own quality and lifecycle decisions.
Does a mesh mean we need multiple platforms
No. Mesh is an ownership model, not a mandate for separate infrastructure per domain. Many organizations run domain-owned data products on a common platform. The question isn’t whether teams share Snowflake, Databricks, BigQuery, or object storage. The question is whether domains own the contract and lifecycle of the assets they publish.
Where do dbt and Airflow fit in each model
In a lakehouse, dbt often standardizes transformation logic on top of a common platform, while Airflow or a managed orchestrator coordinates centralized workflows and dependencies.
In a mesh, the same tools can still work, but the operating pattern changes. Templates, guardrails, and reusable components become more important than centralized control. The platform team’s job is to make the paved road easy enough that domains don’t bypass it.
How should we measure success
Measure success in terms of delivery behavior, platform reliability, and trust in data products.
For a lakehouse, the strongest signals are whether you reduced duplicate pipelines, improved workload performance, and tightened governance without slowing delivery. For a mesh, the strongest signals are whether domains publish usable, documented, trusted data products and resolve quality issues without escalating everything to the center.
Is mesh just a trend, or is it durable
The market signals say it’s durable, but not as a replacement for lakehouse everywhere. According to VertexCS’s 2025 architecture analysis, the global data mesh market was valued at $1.2 billion in 2023 and is projected to reach $2.5 billion by 2028, a 16.4% CAGR. The same analysis notes that 67% of organizations expect to run most analytics on lakehouses within three years. That’s the clearest market signal available: decentralization is growing, but lakehouse remains the dominant practical foundation.
What should we do next
Run a short architecture and operating model assessment before you talk to vendors. Document current bottlenecks, identify who can own data products, and decide whether your problem is platform fragmentation, central backlog, or both.
Then issue an RFP that tests delivery model, governance design, and talent assumptions. If you need a structured shortlist, cost benchmarks, and evaluation criteria for consulting partners, use the buyer tools and firm comparisons at DataEngineeringCompanies.com.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A CTO's Guide to Ecommerce Data Engineering
Build a high-performance ecommerce data engineering architecture. Compare platforms, integration patterns, and vendor selection criteria for maximum ROI.

Data Reliability Engineering A Guide for CTOs
Learn what Data Reliability Engineering (DRE) is, why it matters, and how to implement it. A complete guide for leaders evaluating data engineering partners.

A Guide to Fractional Data Engineering Services in 2026
Explore fractional data engineering services. Learn when to hire, compare pricing, and find the right experts for your data platform and pipeline projects.