MLOps Consulting Services: A Buyer's Guide for 2026

Your team already proved the model works. The notebook is clean. The offline metrics look good. Product wants it live. Legal wants auditability. Platform engineering wants to know who is on call when it breaks.
That is where most ML programs stall.
I have hired MLOps consultants three times. Two engagements were worth every dollar because the consultants built production systems, documented handoff, and forced hard decisions on tooling and ownership. One was a slow-motion train wreck. The firm talked endlessly about AI strategy, delivered slideware, and left us with half-wired pipelines no internal team wanted to own.
If you are evaluating mlops consulting services, treat this as a data engineering buying decision, not an innovation exercise. You are buying pipeline architecture, orchestration, deployment workflows, observability, governance, and operating discipline. The model matters. The system around it matters more.
Your ML Model Works But It Won’t Ship
A familiar scene. Data science has a fraud model, churn model, or demand forecast that performs well in a notebook. Then the handoff starts.
Engineering asks how the features will be computed in production. Nobody knows if training data matches serving data. The deployment script lives on one person’s laptop. Retraining is manual. Nobody has defined rollback criteria. If the model starts drifting, there is no alerting path and no owner.
That is not a modeling problem. It is an operations problem.
The first successful MLOps engagement I ran fixed this by narrowing scope. We did not ask the consultants to “build our AI platform.” We asked them to productionize one model, on one cloud stack, with one deployment path and one monitoring standard. That forced concrete decisions around Airflow, MLflow, containerization, registry gates, and incident ownership.
The failed engagement did the opposite. The consultants spent weeks “assessing maturity” while the team kept shipping manual workarounds. They never produced a deployment-ready architecture. They never connected model delivery to the same discipline you would expect from a well-engineered CI/CD pipeline. They treated ML as special enough to avoid engineering rigor.
If your model can only be deployed by the person who trained it, you do not have an ML capability. You have a fragile demo.
Good mlops consulting services close the gap between notebook success and platform reality. They replace tribal knowledge with repeatable workflows your data engineers, ML engineers, and platform team can run.
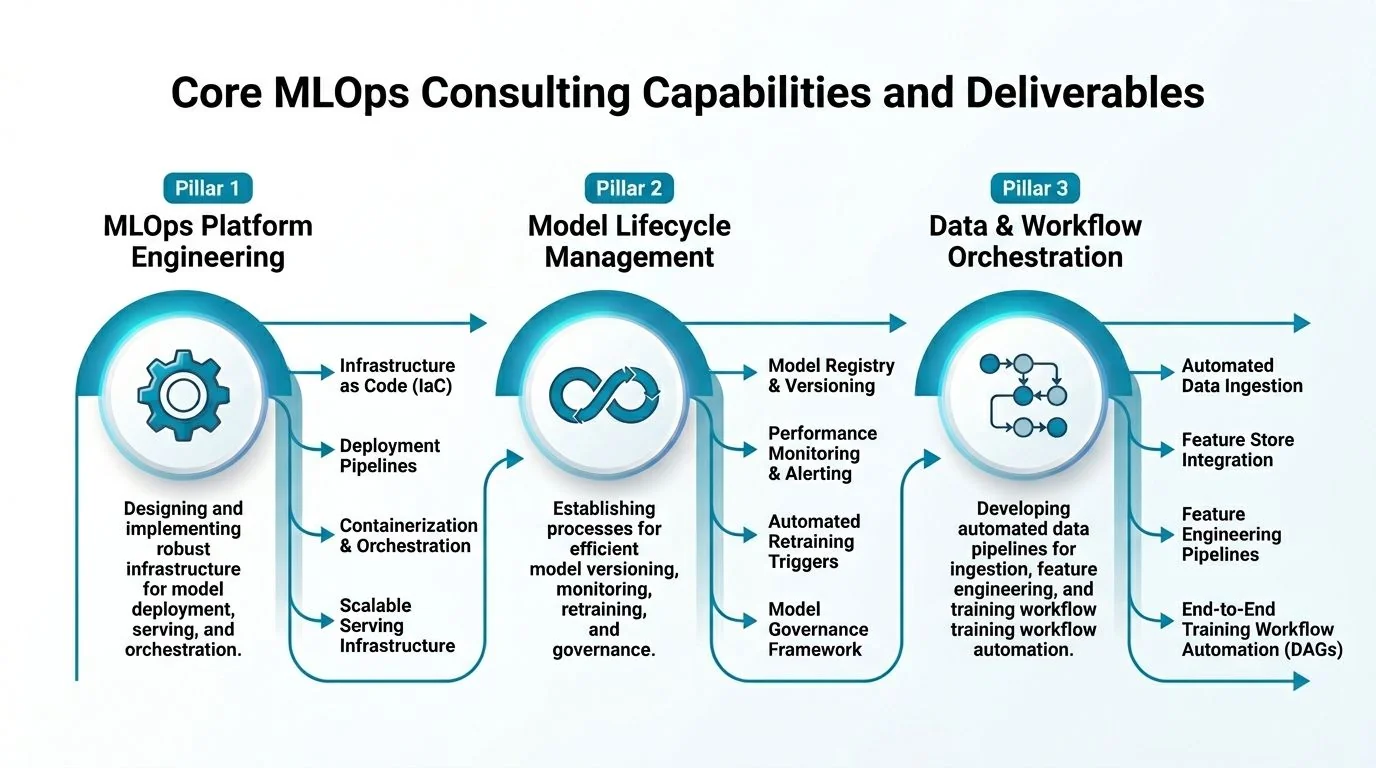
Core MLOps Consulting Capabilities and Deliverables
The term “MLOps consulting” is too vague to buy responsibly. Push vendors to describe what they will build, what artifacts you will own at the end, and how those artifacts fit into your existing data stack.
Organizations adopting structured MLOps consulting services report a 3–4 fold increase in sustained model performance and significantly lower compliance failures. In the same source, Winder.AI’s work with Apartment List unified data pipelines and automated Kubeflow workflows, eliminating data drift and letting the team scale from a few models to dozens with the same headcount (dysnix.com/blog/mlops-consulting-companies).
Platform engineering deliverables
This is the foundation. If the vendor cannot talk clearly about cloud architecture, data movement, and environment reproducibility, stop the conversation.
A serious platform workstream usually includes:
- Reference architecture: A documented target architecture on AWS, Azure, or GCP that shows how training, registry, feature pipelines, batch inference, and real-time inference connect.
- Infrastructure as code: Terraform, Pulumi, or cloud-native templates for reproducible environments.
- Environment standards: Container build patterns, dependency management, secrets handling, access controls, and promotion paths across dev, staging, and production.
- Platform fit decisions: A clear recommendation on whether to center the stack on Databricks, SageMaker, Vertex AI, Azure ML, Kubeflow, MLflow, or a hybrid pattern tied to your data platform.
- Integration points: Explicit hooks into Snowflake, Databricks, dbt, Airflow, Kafka, BigQuery, Delta Lake, or your existing warehouse and orchestration layers.
The best consultants constrain the stack. They do not present ten “flexible” options. They explain why one stack fits your team’s existing operational muscle.
Model lifecycle deliverables
Many firms overpromise and underbuild in this area. Ask for the mechanics.
You want deliverables such as:
- Experiment tracking and lineage: Logged runs, datasets, parameters, artifacts, and model comparison history.
- Model registry with promotion gates: Defined criteria for when a model moves from candidate to staging to production.
- CI/CD workflows for models and infrastructure: Automated testing, packaging, deployment, and rollback controls.
- Release patterns: Shadow deployments, canary releases, staged approvals, and rollback logic tied to degradation signals.
- Retraining rules: Scheduled or event-driven retraining, drift-triggered retraining, and approval workflows for re-release.
A good consultant also specifies who owns each gate. Data science should not promote a model to production without review. Platform engineering should not block releases because the process was never codified.
The actual deliverable is not “automation.” It is a production path with named controls, known failure modes, and clear operators.
Governance and monitoring deliverables
Regulated environments separate competent firms from tourists in this area.
Look for:
- Data quality checks: Schema validation, freshness checks, and threshold-based input validation.
- Drift detection: Monitoring for changes in input distributions and model behavior.
- Performance dashboards: Executive-readable views for business stakeholders and operational dashboards for on-call engineers.
- Audit trails: Versioning of training runs, datasets, parameters, approvals, and deployments.
- Fairness and explainability controls: Especially for healthcare and financial services use cases.
One verified point matters here. Clear data quality standards in MLOps decrease workflow errors by 40% according to the referenced source on MLOps consulting outcomes (elsner.com/how-mlops-accelerates-machine-learning-models-from-dev-to-production).
What a buyer should insist on
Use this as a minimum acceptance checklist.
| Deliverable area | What you should receive |
|---|---|
| Architecture | Cloud and platform reference architecture tied to your stack |
| Pipelines | Automated training and deployment workflows for at least one production model |
| Registry | Configured model registry with promotion criteria |
| Monitoring | Drift, performance, and operational alerting dashboards |
| Governance | Audit trail design, access controls, and documentation |
| Handover | Runbooks, ownership map, and internal enablement sessions |
If a proposal talks about transformation but does not name deliverables like these, it is not specific enough to buy.
Decoding Engagement Models and Team Structures
The market is large enough now that buyers need to choose the engagement model deliberately. The global MLOps Consulting Service market was valued at USD 1.98 billion in 2025 and is projected to reach USD 2.10 billion in 2026. Services, including consulting and managed offerings, are the fastest-growing component, and large enterprises held 54.9% market share in 2025 (360iresearch.com/library/intelligence/mlops-consulting-service).
That matters because vendors are packaging the same core skills in very different commercial wrappers.
Project-based engagements
This is the right model when you need a platform build, migration, or remediation with a clear end state.
Use it for:
- Net-new platform setup: First production pipeline, first model registry, first observability layer.
- Specific migration work: Moving from ad hoc scripts to managed workflows on Databricks, SageMaker, or Vertex AI.
- Delivery with handoff: You want your team running the system after the engagement.
Avoid it when your scope is fuzzy or your internal owners are not named. A fixed-scope project without internal accountability turns into change-order theater.
Staff augmentation
This works when your architecture is mostly settled and you need execution capacity.
It fits situations like:
- Backfilling specialist skills: An ML platform engineer, data engineer, or cloud infra lead.
- Temporary acceleration: You have a roadmap and need more hands to implement it.
- Internal ownership stays strong: Your managers still direct architecture and priorities.
I like this model least when the company expects the consultants to supply strategy. Augmented staff can build. They rarely fix a broken decision process.
Managed services
This is the right choice when you want ongoing operational coverage for pipelines, deployments, monitoring, and incident response.
It makes sense when:
- Your team is lean: You do not want to run day-to-day model operations internally.
- You need continuity: Regular retraining, observability upkeep, compliance reporting, and support.
- Operational discipline matters more than bespoke engineering: Especially in stable, repeatable environments.
The downside is dependency. If the provider runs the system but never transfers knowledge, you rent capability instead of building it.
The team structure I trust
The strongest engagements usually use a small delivery pod:
| Role | What they should own |
|---|---|
| Lead MLOps architect | Target architecture, tool decisions, delivery governance |
| MLOps engineer | CI/CD, registry, deployment workflows, monitoring |
| Data engineer | Feature pipelines, orchestration, warehouse and lakehouse integration |
| Cloud or platform engineer | IAM, networking, environments, infrastructure controls |
If a vendor shows up with strategy consultants and no senior hands-on engineer, walk away. MLOps is won in implementation detail.
MLOps Consulting Pricing Benchmarks and Rate Bands
Most buyers ask the wrong pricing question. They ask, “What does MLOps consulting cost?” The useful question is, “What team, for what deliverables, over what time horizon?”

Here is the market context you should know. MLOps infrastructure investment reached $4.5 billion in 2024, North America held 30.87% of the global market in 2025, and 87% of large enterprises implemented AI solutions in 2025 (arcade.dev/blog/mlops-community-expansion-trends). High demand and concentrated talent push rates up, especially for principal-level architects who can bridge cloud infrastructure, data engineering, and ML operations.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, buyers should expect these broad rate bands for MLOps-adjacent consulting work:
| Role tier | Typical rate band |
|---|---|
| US/UK-based principals | $250 to $400 per hour |
| Senior engineers | $175 to $250 per hour |
| Nearshore or offshore resources | $70 to $150 per hour |
Those bands are useful, but they can mislead. Cheap hourly rates often hide slow delivery, weak architecture, or a team mix that overuses junior engineers. Expensive rates are justified only when the vendor shortens decision cycles and avoids rework.
What good pricing looks like
The cleanest proposals separate work into three buckets:
- Discovery and architecture: Current-state audit, target architecture, backlog, and acceptance criteria.
- Implementation: Pipeline build, infra setup, registry, deployment workflows, observability.
- Enablement and handoff: Runbooks, training, ownership transfer, and stabilization support.
If a vendor sends a single blended rate and no role mix, push back.
For broader benchmarks on how data engineering firms structure rates and thresholds, use this pricing reference: https://dataengineeringcompanies.com/insights/data-engineering-consulting-rates-2026/
Minimum project thresholds matter more than hourly rates
Buyers often encounter issues here. Many firms will happily start a small engagement that has no chance of producing a usable production capability.
My rule is simple. If the budget cannot fund architecture, one real production pipeline, monitoring, and handoff, do not start. A partial MLOps implementation creates more operational complexity than it removes.
A video overview can help align non-technical stakeholders on what they are funding and why:
Buy outcomes, not activity. A vendor that logs hours without leaving you with an operable system is expensive at any rate.
Vendor Selection Criteria and Critical Red Flags
Tool choice matters. Partner choice matters more. I have seen average tooling succeed with a sharp consulting team, and excellent tooling fail under a vague, generalist vendor.
If you want a useful parallel process for judging consulting rigor, this guide on how to evaluate a DevOps consulting company is worth reading. The same discipline applies here. Delivery quality shows up in architecture depth, operating model clarity, and handoff quality.
Positive signals that predict a strong engagement
Look for evidence in five areas.
Platform depth
The vendor should have a strong point of view on your likely stack. If you run Azure and Databricks, I want to hear exactly how they handle MLflow, Delta Lake, orchestration, secrets, access boundaries, and deployment promotion. Generic “cloud-agnostic” talk is not enough.
Data engineering fluency
MLOps failures usually start upstream. The firm needs real strength in Airflow, dbt, Spark, warehouse-lakehouse integration, feature pipelines, and data quality controls. If they talk only about models, they are missing the hard part.
Delivery artifacts
Ask to see sample architecture diagrams, runbooks, release workflows, incident playbooks, and handover docs. Mature firms have these ready.
Internal enablement
The best vendors design for independence. They train your engineers, document the workflows, and leave behind systems your team can extend.
Industry fit
This matters most in regulated environments. A major market gap is MLOps consulting for regulated industries. Many firms do not address compliance-specific needs like HIPAA or FDA 21 CFR Part 11, which makes compliance-first architecture a decisive evaluation criterion in healthcare and finance (coherentsolutions.com/artificial-intelligence/mlops).
Red flags that should kill the deal
I would reject a vendor quickly for any of these.
- They sell “AI transformation” before they define delivery scope. Strategy language often hides weak implementation.
- They cannot explain ownership after go-live. If no one knows who runs retraining, rollback, alerting, and approvals, the platform will decay.
- They have no view on your existing data platform. MLOps has to fit Snowflake, Databricks, BigQuery, dbt, Airflow, and your cloud controls.
- They dodge compliance specifics. In healthcare and fintech, inability to discuss auditability, explainability, documentation, and regulated workflows is disqualifying.
- They promise tool agnosticism as a virtue. Breadth is useful. Lack of depth is expensive.
- They do not include knowledge transfer. That is how you end up dependent on the same firm for basic maintenance.
The right vendor makes your internal team stronger. The wrong vendor makes your environment more confusing and your roadmap slower.
The Abridged MLOps RFP Checklist
Most RFPs fail because they ask vendors to describe capabilities, not prove them. That produces polished prose and weak comparability.
A documented gap in the market is the lack of ROI guidance in MLOps consulting. Buyers often do not get a standardized scorecard, so vendors avoid proposing concrete KPIs unless forced to (mlopscrew.com/blog/top-mlops-consulting-companies-in-usa). Fix that in the RFP.
Ask questions that force architecture specificity, operational realism, and measurable success criteria.
MLOps Consulting RFP Evaluation Checklist
| Category | Key Question | Why It Matters |
|---|---|---|
| Technical architecture | Provide a reference architecture for an MLOps platform you have deployed on our target cloud and data stack. | Exposes whether the vendor has real implementation depth or generic diagrams. |
| Technical architecture | Show how training, feature computation, registry, batch inference, and real-time inference integrate with our warehouse or lakehouse. | Confirms they understand data engineering dependencies, not just model hosting. |
| Technical architecture | Which tools do you recommend for orchestration, registry, monitoring, and deployment, and why not the main alternatives? | Strong vendors can justify tradeoffs clearly. |
| Process and workflow | Describe the exact path from model training to production deployment. Include gates, approvals, and rollback triggers. | Forces operational detail instead of abstract “CI/CD” claims. |
| Process and workflow | What artifacts will be versioned across code, data, configurations, and models? | Reveals whether reproducibility is designed in. |
| Process and workflow | How will you onboard the first production model, and how will additional models reuse the same platform? | Distinguishes a one-off build from a scalable operating model. |
| Governance and security | Describe your approach to audit trails, access controls, lineage, and deployment approvals. | Necessary for enterprise controls and regulated use cases. |
| Governance and security | How do you detect data drift, model degradation, and upstream data quality failures? | Monitoring design is central to production reliability. |
| Governance and security | If we operate in healthcare or finance, how do you adapt the architecture for compliance-first deployment? | Exposes whether the vendor can handle regulated environments. |
| Commercials and ROI | Propose success metrics for the engagement, including time-to-production, deployment frequency, retraining automation, and pipeline failure reduction. | Prevents vague outcome claims and creates a scorecard. |
| Commercials and ROI | Break pricing out by role, workstream, and deliverable. | Lets buyers compare staffing models and challenge padding. |
| Commercials and ROI | What must our internal team provide for the project to succeed? | Serious vendors understand buyer-side responsibilities and dependencies. |
Questions that expose weak vendors fast
These are my favorites in a live review:
- Walk us through a failed production model deployment and how your architecture contained the issue.
- Show us a sample runbook for a drift alert.
- Explain what your team will hand over in week one, midpoint, and final transition.
- Name the decisions you expect us to make in the first two weeks.
Weak firms answer with process theater. Strong firms answer with examples, documents, and tradeoffs.
If the vendor cannot define success metrics before kickoff, they are not ready to be measured after kickoff.
How to Shortlist Providers Using DataEngineeringCompanies.com
Once you know what you are buying, provider research gets simpler.
Start with budget realism. Use the cost benchmarks and your likely team mix to narrow the field before calls begin. Then build a longlist based on platform and industry fit, not brand awareness. If your environment is Azure plus Databricks in financial services, shortlist firms that already speak that language fluently.
The fastest way to do that is to review specialist firm profiles and shortlists rather than broad agency directories. A practical place to start is this guide to https://dataengineeringcompanies.com/insights/machine-learning-consulting-firms/
Then run a disciplined funnel:
- Filter by stack fit: Snowflake, Databricks, AWS, Azure, GCP, Airflow, dbt, MLflow, Kubeflow.
- Filter by industry exposure: Healthcare, fintech, retail, or enterprise platform work.
- Check minimum engagement fit: Do not waste time on firms that only want much larger programs than yours.
- Use the RFP checklist in screening calls: Ask architecture and handoff questions early.
- Cut to two or three finalists: Then do a working session, not just a sales demo.
Many buyers make the process too democratic at this stage. Procurement, data science, platform engineering, and security all deserve input. One executive still needs final decision rights. Without that, every vendor gets scored as “promising” and nobody gets selected.
If you are actively shortlisting providers, use DataEngineeringCompanies.com to compare platform fit, rate bands, industry focus, and minimum engagement thresholds before you issue an RFP. It is one of the few resources built for buyers making data engineering and ML platform decisions rather than browsing generic agency listings.
Frequently Asked Questions about MLOps Consulting
Should we build an in-house team or hire consultants
Do both, in sequence.
Use consultants to design and implement the first production-ready platform, then transfer ownership to your internal team. That is the best pattern if you already have strong data engineering and platform talent. If you do not, the consultants should still build with handoff in mind.
Do not outsource core operational knowledge indefinitely unless you intentionally want a managed service model.
What is a realistic timeline for an MVP MLOps platform
A realistic answer is “long enough to support one real production model safely.”
I do not trust vendors who promise instant platform builds. A credible MVP includes architecture decisions, one productionized model path, environment setup, deployment workflow, monitoring, and handoff. If the proposal skips any of those, it is not an MVP. It is a demo.
What is the difference between MLOps and general DevOps consulting
DevOps consulting focuses on software delivery pipelines, infrastructure automation, and runtime operations for deterministic applications.
MLOps adds data dependencies, model versioning, retraining logic, drift detection, experiment tracking, and non-deterministic behavior. That changes the architecture. It also changes the failure modes. A model can degrade without a code change. That is why general DevOps shops often miss critical ML-specific controls.
How do we measure the ROI of an MLOps engagement
Start with operational metrics, not boardroom slogans.
Track:
- Time from model-ready to production deployment
- Frequency of successful model releases
- Amount of manual intervention in retraining and deployment
- Pipeline failure frequency and recovery process
- Auditability of data, model, and deployment lineage
The key is to baseline those before the engagement begins. If the vendor does not insist on that, insist on it yourself.
What is the biggest mistake buyers make
They buy broad capability claims instead of narrow production outcomes.
The winning engagement usually starts with one model, one team, one cloud stack, and one clear set of deliverables. The losing engagement starts with vision decks, generic roadmaps, and “future-state AI operating models” disconnected from your actual data platform.
What should the final handoff include
At minimum, I expect:
- Architecture documentation
- Infrastructure and pipeline code in your repos
- Runbooks for deployment, rollback, and drift response
- Ownership mapping
- Training sessions for engineering and operations
- A stabilization period with explicit exit criteria
If those are missing, the consultants did not finish the job.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Top AI & ML Partners
Vetted firms whose specialty matches this article.
More in AI & ML Data Engineering

Where to Find and Vet Machine Learning Consulting Firms
A practical guide to seven resources for finding and evaluating machine learning consulting firms - organized by resource type, not ranked by quality.

Actionable Playbook for Snowflake to Databricks Migration
Actionable playbook for engineering leaders: Snowflake to Databricks migration. Strategies for cost, execution & AI/ML value.

A CTO's Guide to Databricks Unity Catalog Implementation
A proven guide for CTOs on Databricks Unity Catalog implementation. Get actionable frameworks for architecture, governance, migration, and CI/CD.