Top Data Engineering Managed Services for 2026

Most CTOs buy data engineering managed services for speed. They should buy them for control over cost, execution, and operational risk.
The market is large and getting larger. The global big data engineering services market is valued at USD 88.85 billion in 2025 and projected to reach USD 325.01 billion by 2033, with cloud deployments holding 63.47% of revenue share, according to Market Data Forecast’s big data engineering services market report. That growth tells you one thing: vendors know demand is there. It does not tell you which engagement model protects your platform, your budget, or your internal advantage.
That’s the actual procurement problem. Most firms can pitch Snowflake, Databricks, dbt, Airflow, AWS, Azure, and BigQuery. Fewer can explain how they’ll prevent runaway change requests, preserve institutional knowledge, and hand you a platform your team can still govern a year later.
If you’re selecting a partner for an enterprise data platform initiative, don’t start with brand logos. Start with operating model, contractual guardrails, and technical proof.
Deconstructing Data Engineering Service Models
The wrong service model creates avoidable pain. You’ll either overpay for work your team could handle, or you’ll under-buy and end up with a vendor who can’t own outcomes.
Fully managed
A fully managed model means the provider owns platform operations, pipeline orchestration, monitoring, upgrades, incident response, and usually a chunk of roadmap delivery. This is the right model when your internal team is thin, your estate is fragmented, or you need fast stabilization after a failed migration.
It also gives you the cleanest budget story if the contract is written properly. One provider owns delivery. One provider owns support. One provider can’t blame your staff for every miss.
The downside is obvious. If the vendor owns architecture, orchestration, and runbooks without disciplined documentation and transition obligations, your data platform becomes a rented asset.
Practical rule: Use fully managed only if the contract includes mandatory documentation, named service boundaries, knowledge transfer, and exit support.
Co-managed
A co-managed structure is usually the best fit for enterprise data engineering. Your team keeps architectural authority, platform standards, access policy, and business logic ownership. The vendor handles agreed layers such as Airflow operations, dbt development capacity, Snowflake performance tuning, Databricks jobs, or cloud infrastructure automation.
This model preserves internal judgment. It also keeps your staff close enough to the platform to retain context on lineage, data contracts, and domain logic.
It’s harder to govern than fully managed because split ownership creates gray zones. If a pipeline fails, the vendor can point at source quality, while your team points at orchestration. Fix that in the SOW. Define ownership by layer, tool, and incident type.
Staff augmentation
Staff augmentation is not managed service. It’s rented labor. That distinction matters.
Use augmentation when you know the architecture, already have engineering management in place, and need targeted skills such as Spark optimization, dbt refactoring, or BigQuery migration support. Don’t use it when you need a partner to own service levels or platform outcomes. Augmented engineers follow your lead. If your internal operating model is weak, augmentation amplifies the weakness.
Which model fits your situation
| Model | Best when | Main strength | Main risk |
|---|---|---|---|
| Fully managed | Team lacks bandwidth or operational maturity | Clear accountability | Vendor dependency |
| Co-managed | You want outside execution but keep strategic control | Balance of control and speed | Blurred ownership |
| Staff augmentation | You need specialist capacity inside an existing program | Flexibility | No outcome ownership |
Use this decision lens:
- Choose fully managed if your priority is service continuity, migration recovery, or getting a cloud data platform under control fast.
- Choose co-managed if you want the vendor to accelerate delivery while your architects keep standards, platform direction, and governance.
- Choose staff augmentation if your roadmap is clear and you’re filling specific gaps in Snowflake, Databricks, dbt, Airflow, or cloud-native infrastructure.
The vendors that matter will tell you where their model doesn’t fit. The weak ones call everything “flexible.”
Core Capabilities Your Partner Must Deliver
A polished proposal means nothing if the partner can’t execute the core mechanics of data engineering managed services.
Providers using managed services like Amazon MWAA can reduce operational overhead by 50 to 70 percent, and Forrester notes 40 percent faster time-to-insights in managed setups, according to AWS prescriptive guidance on data engineering. That benefit only shows up when the provider is strong in the basics.

Ingestion that matches business reality
A serious partner doesn’t just say “batch and streaming.” They map ingestion patterns to business criticality, source volatility, and failure handling.
For example, SAP extracts, SaaS APIs, CDC pipelines, event streams, and file drops should not all be governed the same way. Ask how they handle schema drift, replay, late-arriving data, and source-side throttling. If they can’t explain the difference between operational ingestion design and analytics ingestion design, move on.
What to verify:
- Source coverage: They should name the systems they’ve integrated, not just say “many connectors.”
- Recovery design: Ask for their retry, backfill, and replay approach.
- Platform fit: On AWS, they should speak comfortably about S3, Glue, MWAA, and orchestration boundaries.
ETL and ELT that your team can maintain
Good ETL and ELT work is boring in the right way. It’s modular, version-controlled, testable, and easy to hand over. In Snowflake and BigQuery estates, that usually means clean ELT patterns and disciplined SQL transformations. In Databricks estates, it often means Spark jobs where they’re justified, not because the vendor likes PySpark.
If the provider wants to bury core business logic inside proprietary accelerators or opaque notebooks, push back. Your future operating cost lives inside those choices.
Ask every vendor to walk through one representative pipeline from ingestion to consumption, including code ownership, testing, rollback, and handoff.
Data modeling that serves the business
A vendor should be able to defend when to use dimensional models, when to use wide tables, and when to expose curated domain layers for self-service. If they answer every question with “lakehouse,” you’re listening to product marketing, not architecture.
Look for clarity on semantic consistency. Revenue, customer, order, claim, policy, account. These aren’t just columns. They’re business definitions with downstream political consequences.
Governance built into delivery
Governance isn’t a later workstream. It belongs in access design, lineage, PII handling, data contracts, and release controls from the start.
You also want operational observability, not just platform uptime dashboards. A useful reference on ensuring data health for analytics is data observability guidance that treats freshness, schema drift, and trust as engineering concerns, not reporting concerns.
What to verify in governance reviews:
- Access model: Role design across engineers, analysts, and service accounts
- Lineage discipline: How they track dependencies across ingestion, transformation, and reporting
- Policy enforcement: How masking, retention, and audit expectations are implemented in pipelines
Observability that goes beyond failed jobs
Average vendors alert on failed runs. Strong vendors detect silent data failures, freshness issues, quality regressions, and cost anomalies.
That means they should instrument checks for null spikes, duplicate loads, schema changes, unexpected volume shifts, and warehouse or cluster consumption jumps. If they don’t monitor spend behavior on Snowflake virtual warehouses, Databricks compute, or BigQuery query patterns, they’re not managing the platform. They’re babysitting it.
Here’s the short test. Ask the vendor what happens when a pipeline technically succeeds but loads bad data. Their answer will tell you whether they operate a data service or just maintain jobs.
The Business Case Benefits and Real Risks
Data engineering is already central to enterprise operations. 77 percent of organizations now consider it critical or very important, rising to 92 percent in large enterprises, while 56 percent use data engineering capabilities constantly or frequently, according to Matillion’s data engineering trends analysis. The strategic argument is settled. The procurement argument is not.
Managed services make sense when they remove bottlenecks your internal team can’t clear quickly. Recruiting takes time. Platform mistakes are expensive. Cloud migrations stall when nobody owns the ugly middle between architecture diagrams and operating pipelines.
The upside worth paying for
The best managed service engagements do three things well.
- They compress delivery time. A capable partner brings reference architecture, implementation muscle, and people who’ve already handled Snowflake migrations, Databricks workspace design, dbt project structure, or Airflow orchestration patterns.
- They give you specialist coverage without building a full bench. That matters when you need one strong platform architect, one pipeline lead, and one governance-heavy engineer, not a permanent team in every niche.
- They let your internal team focus on product and domain logic. Your staff should define business rules, domain ownership, and platform standards. They shouldn’t spend their week firefighting brittle infrastructure.
A similar principle shows up in software delivery. Teams that streamline product shipping by standardizing release practices move faster because engineers spend less time on avoidable operational drag. Data platforms benefit from the same discipline.
The risks vendors downplay
The genuine hazards are contractual and organizational.
Vendor lock-in starts when the provider bakes critical transformation logic into proprietary frameworks, controls your deployment pipelines, and withholds the runbooks your team needs to operate independently.
Cost sprawl starts when the MSA looks simple but the SOW leaves room for overages, after-hours fees, premium support charges, and endless “out of scope” change requests.
Capability erosion happens when your internal team becomes an approval layer instead of a technical owner. Six months later, nobody on your side understands the DAGs, job dependencies, or warehouse tuning choices.
If the vendor owns every hard decision, your team won’t be stronger at the end of the engagement. It will be weaker.
Guardrails that change the outcome
Insist on these from day one:
- Architecture ownership stays with you. Even in a managed model, your team approves standards, core platform choices, and major design changes.
- Documentation is a deliverable, not a courtesy. Runbooks, lineage artifacts, data model decisions, and environment diagrams belong in the contract.
- Exit support is priced and defined up front. If transition terms are vague, dependency is the business model.
- Knowledge transfer is scheduled, not optional. Monthly walkthroughs beat last-minute handovers.
Managed services work. Blind dependency doesn’t.
Pricing Contracts and Avoiding Hidden Costs
Most vendor quotes are designed to look simple. The actual cost sits in exclusions, assumptions, and cloud consumption that nobody wants to discuss in the first meeting.
According to DataEngineeringCompanies.com’s analysis and Everest Group 2025 surveys, benchmark rates range from $150 to $300 per hour, with 20 to 40 percent cost savings post-migration to a managed service, as cited in USDSI’s overview of data engineering economics. Useful benchmark. Incomplete buying model.
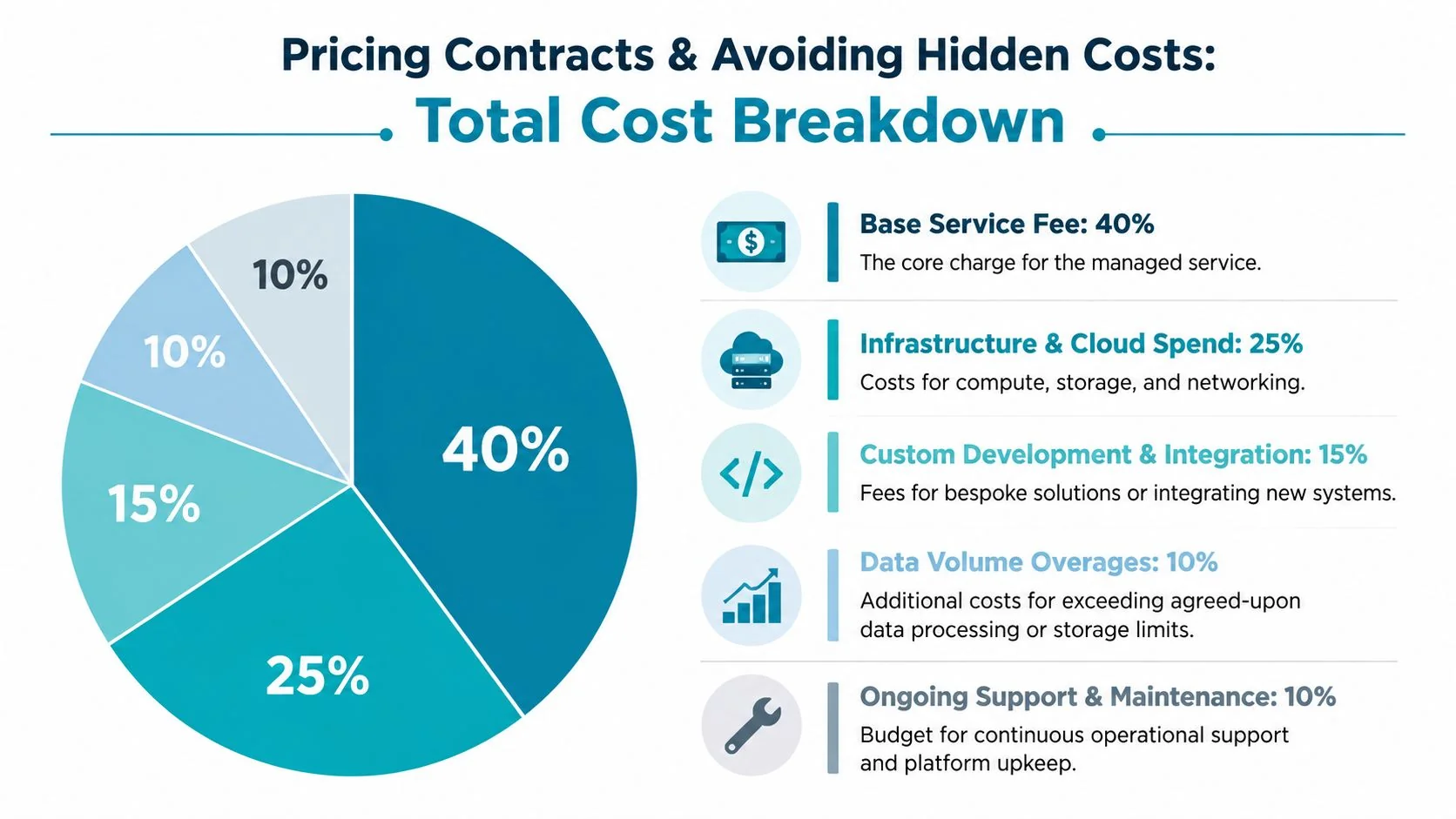
Price the engagement, not the line item
You’re not buying “managed data engineering.” You’re buying some combination of platform operations, development capacity, support response, governance work, and cloud cost management.
A vendor with a lower hourly rate can still be more expensive if they require larger team minimums, bundle senior review inefficiently, or trigger constant change requests. That’s why rate cards alone are weak procurement tools.
If you want current market context, this review of data engineering consulting rates for 2026 is useful as a comparison point for engagement structures and role pricing.
The three pricing models you’ll see
| Pricing model | Good for | Procurement risk |
|---|---|---|
| Fixed retainer | Stable support, recurring operations | Hidden exclusions and low flexibility |
| Time and materials | Ambiguous discovery or changing scope | Weak budget predictability |
| Consumption-linked | Elastic workloads and cloud-heavy estates | Harder attribution of overruns |
The right choice depends on maturity.
A stable Snowflake or BigQuery platform with known support boundaries fits a retainer. A messy modernization effort involving Airflow, dbt, cloud infrastructure, and migration unknowns usually needs time and materials during discovery, then a controlled retainer or milestone model later. Consumption-linked contracts need especially hard governance because the vendor has little natural incentive to reduce billable usage unless the contract forces it.
Hidden cost traps to surface in the RFP
Use direct questions. Don’t ask whether pricing is transparent. Ask where invoices increase.
- Change request fees: What triggers them, who approves them, and how fast can they stack up?
- Minimum commitments: Is there a monthly floor regardless of actual ticket or sprint volume?
- After-hours support: What counts as standard coverage versus premium coverage?
- Environment charges: Are non-production support, testing, and release management included?
- Cloud accountability: Who owns warehouse tuning, cluster right-sizing, and storage lifecycle discipline?
For adjacent services, it helps to compare AI service fees because the same pattern shows up there too. Buyers get seduced by entry pricing and miss the integration, maintenance, and support layers that drive the long-term bill.
Commercial test: If a vendor cannot model your total monthly cost under low, expected, and high workload scenarios, they are not ready for enterprise procurement.
Contract clauses worth insisting on
Your MSA and SOW should include:
- Named roles and blended rates
- A cap or approval gate for overages
- Defined inclusions for support, monitoring, and incident response
- Clear ownership of code, documentation, and configuration artifacts
- Exit assistance terms with timelines and deliverables
- A cloud cost governance obligation, not just a usage disclaimer
The biggest mistake is treating data engineering managed services like generic IT support. They aren’t. The architecture evolves while the meter is running.
The Vendor Evaluation Scorecard
If your selection process depends on demos and chemistry, expect expensive surprises later. Use a weighted scorecard and force evidence into the room.
Managed services can ensure 95%+ data quality, unclean data causes an estimated 25% model accuracy loss in ML, and Everest Group data indicates 35% cost savings over in-house teams, with typical managed rates of $100 to $180 per hour versus $150 to $250 per hour for direct hires, according to DAS42’s review of managed data analytics services. Those economics justify rigor, not shortcuts.
Use weighted scoring, not gut feel
Below is a practical scorecard you can use in an RFP or final-round vendor review.
| Category (Weight) | Evaluation Criterion | What to Look For | Score (1-5) |
|---|---|---|---|
| Technical expertise (30) | Platform depth | Proven delivery in Snowflake, Databricks, dbt, Airflow, AWS, Azure, or BigQuery relevant to your stack | |
| Technical expertise (30) | Architecture quality | Clear reference architecture, environment separation, orchestration design, and recovery patterns | |
| Delivery methodology (20) | Execution discipline | Sprint cadence, release process, testing standards, incident handling, and documentation routines | |
| Governance and security (20) | Control maturity | Access model, lineage, masking, retention controls, and auditability | |
| Commercial viability (15) | Pricing transparency | Clear rates, service boundaries, overage rules, and support terms | |
| Commercial viability (15) | Partnership durability | Named team continuity, escalation path, transition support, and knowledge transfer plan |
If you want a ready-made procurement artifact, this data engineering vendor scorecard template gives a structured version you can adapt.
How to score without fooling yourself
Don’t accept self-reported maturity at face value. Require proof.
- For technical depth: Ask for one architecture review with the delivery lead, not just sales.
- For delivery quality: Request sample runbooks, backlog examples, and testing conventions with sensitive details removed.
- For governance: Ask how they track lineage, role design, and policy enforcement inside actual projects.
- For commercial fit: Make them walk through a mock invoice against your expected scope.
Questions that expose weak vendors
Use pointed questions in final-stage diligence.
- Who owns business logic when source systems change unexpectedly?
- How do you separate urgent incident work from roadmap delivery so both don’t collapse?
- What artifacts do you deliver monthly besides tickets closed?
- How do you transition the service to an internal team or replacement partner?
- Which parts of the stack depend on your proprietary assets?
Score low if the vendor answers with process language but no artifacts, no examples, and no named owners.
Minimum passing standard
Set a floor before review starts. For enterprise work, I’d reject any vendor that scores poorly in governance or commercial transparency, even if they’re technically strong. You can coach a good engineering team into your workflow. You can’t fix a contract that rewards opacity.
Red Flags for Snowflake Databricks and AI Projects
The fastest way to waste budget is to hire a vendor that speaks fluently in platform marketing and vaguely in implementation detail.
Emerging data mesh implementations show a 35 percent failure rate in pilots due to skill gaps, and 60 percent of mid-market firms experience governance breakdowns in mesh setups, according to Prescience’s review of data engineering transformation patterns. That matters because many vendors now use “mesh,” “AI-ready,” and “lakehouse” as cover for thin delivery discipline.

Snowflake red flags
A weak Snowflake partner usually reveals itself in one of three ways:
- They ignore cost governance. If they don’t talk about warehouse sizing, query discipline, and workload isolation, they’ll spend your budget casually.
- They overuse proprietary features without portability logic. That increases lock-in and complicates future platform choices.
- They treat dbt as optional structure. For many teams, maintainable transformation logic depends on disciplined model organization and testing.
Databricks red flags
Databricks projects fail when vendors oversell “unified analytics” and underspecify operations.
Watch for these signals:
- No clear workspace and environment strategy
- Weak story on job orchestration and dependency management
- No serious MLOps plan for feature pipelines, model inputs, or handoff between data engineering and ML teams
If they can demo notebooks but not explain production controls, they’re not ready.
AI project red flags
The most dangerous phrase in vendor meetings is “AI readiness.” It usually means nothing.
Reject vendors that promise AI outcomes without a concrete plan for data quality, feature engineering, lineage, access control, and curated training datasets. Also reject any partner pushing data mesh or federated ownership models without evidence they can support domain accountability and governance in your operating environment.
AI programs don’t fail because the model was too small. They fail because the underlying data platform was unmanaged, undocumented, and politically ownerless.
Your First 90 Days An Action Plan
Weeks one and two, lock internal alignment. Name an executive owner, a technical owner, and a procurement owner. Define target platforms, essential controls, migration scope, support boundaries, and what stays in-house.
Weeks three through six, run a disciplined shortlist. Use the scorecard. Force every vendor to respond to the same architecture, governance, pricing, and transition questions. Reject any proposal that hides assumptions or turns documentation into optional work.
Weeks seven through ten, do technical and commercial diligence in parallel. Meet the actual delivery lead. Review a sample runbook. Review invoice logic. Negotiate service boundaries, overage approvals, exit support, and code ownership before legal redlines stall progress.
Weeks eleven and twelve, onboard deliberately. Set architecture approval cadence, ticket severity definitions, monthly operating reviews, and knowledge transfer sessions from the start. Don’t wait until the platform is live to discover who owns lineage, cloud spend, or failed releases.
Start with the operating model. Then force proof on technical delivery. Then close the commercial traps. That sequence gives you a partner you can manage, not just a vendor you can hire.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

The 10-Point Data Engineering Due Diligence Checklist for 2026
Don't hire a consultant without this data engineering due diligence checklist. Vet firms on architecture, cost, governance, and team skills before you sign.

Actionable Playbook for Snowflake to Databricks Migration
Actionable playbook for engineering leaders: Snowflake to Databricks migration. Strategies for cost, execution & AI/ML value.

A CTO's Guide to Databricks Unity Catalog Implementation
A proven guide for CTOs on Databricks Unity Catalog implementation. Get actionable frameworks for architecture, governance, migration, and CI/CD.