Data Engineering for Startups: A 2026 Strategy Guide

Most advice on data engineering for startups is wrong because it copies enterprise patterns into companies that are still searching for repeatability. A seed-stage startup does not need a sprawling lakehouse roadmap, six governance councils, or a full-time platform team. It needs answers, fast, without painting itself into a corner.
I’ll be blunt. The expensive mistakes are predictable. Teams scale pipelines before they validate the business questions. They hire the wrong first data engineer. They sign a consultancy that sells a platform migration when the actual need is two reliable pipelines, dbt models, and basic access control. Then they wonder why the stack feels heavy and nobody trusts the dashboards.
The right approach is narrower. Build only the data capability your current stage can use. Choose tools that your team can operate without heroics. Treat vendor selection like capital allocation, because that’s what it is.
The Startup Data Maturity Model From Seed to Scale
Start with stage, not tools. Funding stage isn’t perfect, but it maps well to the actual constraints that matter: team size, reporting pressure, customer complexity, and tolerance for rework.
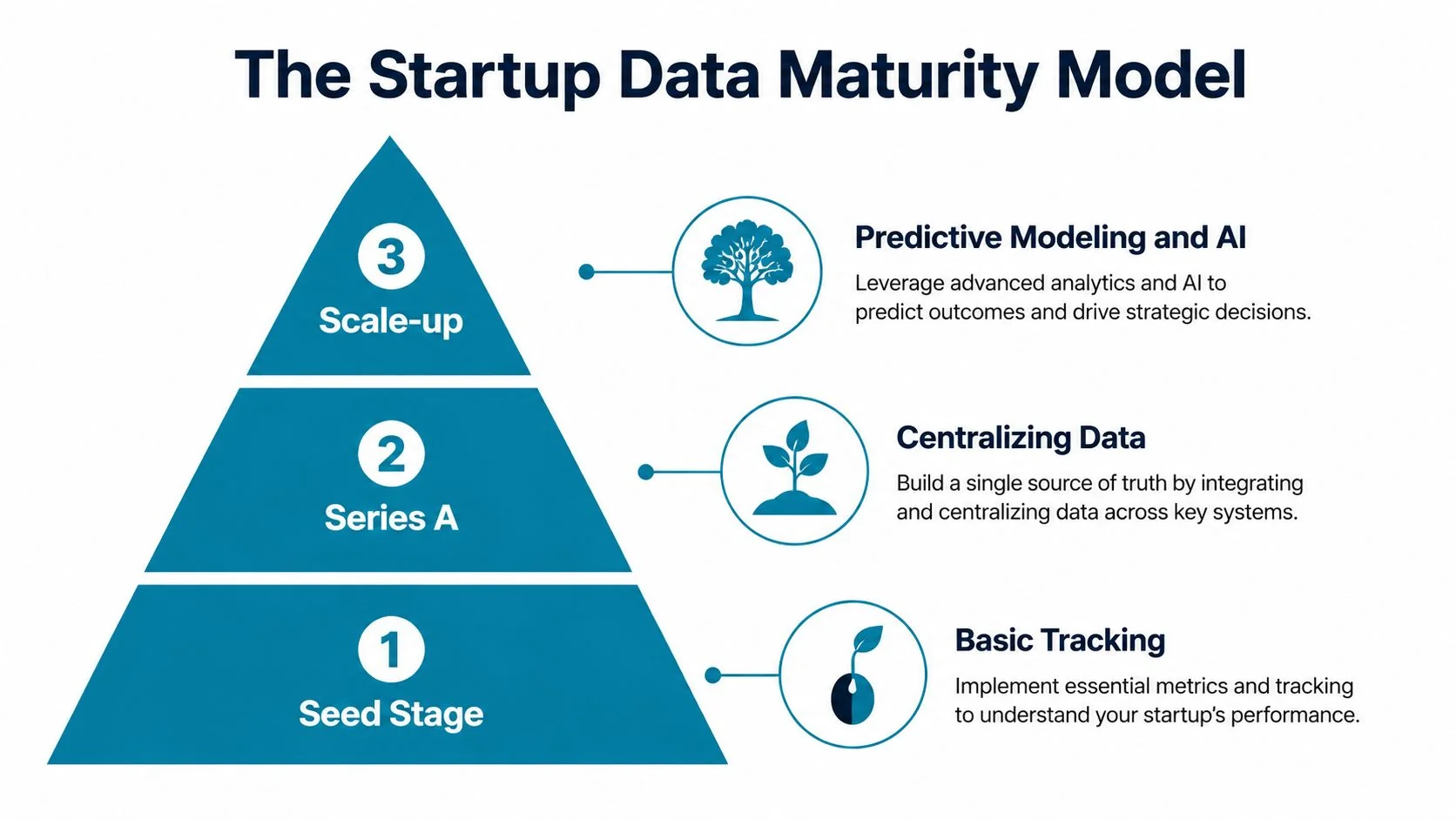
Seed stage
At seed, your job is simple. Prove demand, understand behavior, and stop debating metrics in Slack.
A structured validation process matters here because startups still die from building the wrong thing. A phased approach helps address the 34% failure rate from lack of product-market fit, while 22% fail during validation because they scale too early. When teams skip data quality gates at this stage, they create 40-60% downstream analytics errors, according to DesignRush coverage of startup failure benchmarks.
Good enough at seed looks like this:
- One warehouse or queryable core store: BigQuery, Snowflake, or a lightweight managed pattern on AWS.
- A few critical sources only: Billing, product analytics, CRM.
- One shared metrics layer: Even if it’s just dbt models and documented SQL.
- A narrow dashboard set: Revenue, activation, retention, pipeline.
If you’re ingesting every event under the sun before you know which product questions matter, you’re wasting cash.
Practical rule: If a source doesn’t change a product, growth, or revenue decision this quarter, don’t prioritize it.
Series A stage
Series A changes the mandate. You’re not proving the market anymore. You’re trying to centralize reporting, remove manual joins, and make teams self-sufficient.
Many startups overcorrect at this stage. They jump from spreadsheet chaos to platform maximalism. Don’t. What you need is a stable transformation layer, scheduled pipelines, and clear ownership.
Use these questions to gauge maturity:
| Focus area | What leadership needs answered |
|---|---|
| Growth | Which channels produce retained users, not just signups |
| Sales | Which segments convert fastest and expand cleanly |
| Product | Which behaviors predict activation and churn |
| Finance | Which metrics match board reporting without manual reconciliation |
At this stage, “good enough” means Airflow or managed orchestration, dbt for transformations, warehouse-level role-based access, and basic data tests on core models.
Series B and beyond
Now the company earns the right to invest in harder infrastructure. The questions shift from “what happened?” to “what’s driving efficiency, risk, and forecast quality?”
You should expect pressure for cleaner lineage, stronger governance, and ML-ready datasets. That still doesn’t justify random complexity. It just means the stack must hold up under more users, more domains, and more scrutiny.
A useful self-check:
- Do teams share metric definitions?
- Can you trace a board metric back to source data?
- Can a new data source land without breaking downstream models?
- Can engineering explain platform cost drivers in plain English?
If the answer is no to most of these, you don’t need more tools. You need tighter operating discipline.
Choosing Your Minimal Viable Data Stack
The best minimal stack is the one your team can run next month, not the one that looks impressive in an architecture diagram.
For small teams, hiring mistakes are brutal. Teams with fewer than 10 engineers face a 3x higher failure risk from bad first data engineering hires, and 60% of startups hire generalist software engineers internally over specialists. The same benchmark set also notes that many of Y Combinator’s data engineering startups bootstrap in-house before scaling, and some early teams use $10K pilots to validate outside help first, as summarized by Seedtable’s data engineering startup analysis.

Pattern one for pre-PMF speed
This is the stitched-SaaS stack. It’s ugly, fast, and often correct for very early companies.
Typical shape:
- Ingestion: Managed connectors
- Storage: BigQuery or Snowflake
- Transformation: SQL in warehouse, maybe a little dbt later
- Orchestration: Native schedules or lightweight managed jobs
- BI: One tool, one semantic owner
This pattern works when the business needs visibility fast and the engineering team can’t babysit infrastructure.
Pattern two for a scalable foundation
This is the default recommendation for most Series A startups.
A practical setup looks like this:
| Layer | Recommended approach |
|---|---|
| Warehouse | Snowflake for strong managed experience, BigQuery for GCP-native teams |
| Pipelines | Airflow or managed orchestration for repeatability |
| Transformations | dbt for versioned models and testable logic |
| Cloud | AWS, Azure, or GCP based on existing engineering footprint |
| Documentation | Inline model docs plus a shared data dictionary |
Pick the cloud that matches your product and team. Don’t create cross-cloud complexity because a consultant likes one vendor more than another.
If you want a grounded view of how the modern stack fits together, this guide to the modern data stack is worth reviewing before you lock in platform choices.
Pattern three for the modern core
Databricks starts to make sense in this context. It is not necessary at the seed stage simply because it is fashionable, but rather when you need broader data engineering and ML workflows within a single operating model.
Choose this pattern when:
- You need mixed workloads: Analytics, feature pipelines, heavier transformation.
- You have real platform ownership: Someone can manage standards, jobs, and spend.
- Your data mix is widening: Structured product data plus logs, event streams, or ML artifacts.
Don’t buy Databricks because you expect to need AI later. Buy it when your current workload already justifies the operational model.
My blunt build-buy-outsource view
Build in-house when data logic is part of product advantage. Buy managed components whenever they remove commodity work. Outsource narrowly, for design, migration, and acceleration, not as a permanent substitute for ownership.
The wrong move is hiring a senior “unicorn” before you know the shape of the problem. The second wrong move is outsourcing the entire stack and learning nothing.
Running a Lean Vendor and Consultant Selection Process
Most startup procurement fails because founders and engineering leaders buy reassurance instead of outcomes. They sit through polished demos, nod at reference architectures, and skip the hard questions about scope control, handoff quality, and operating cost.
That’s how startups end up with 30-50% budget overruns from scope creep and cloud misconfigurations. It’s also why 40% of projects are delayed by poor vendor alignment, and why practical checklists matter if you want to avoid the 25% abandonment rate in early-stage engagements, based on Dataforest’s summary of Clutch and G2 startup outsourcing benchmarks.

The decision matrix that actually helps
Use a three-way decision instead of pretending every project belongs in-house.
| Criteria | Build In-House | Buy (SaaS/Managed Service) | Outsource (Consultancy) |
|---|---|---|---|
| Best use case | Core data models tied to product advantage | Commodity ingestion, hosting, and routine ops | Migrations, stack design, platform bootstrap |
| Leadership burden | Highest | Lowest | Medium |
| Speed to initial value | Slower | Fastest | Fast if scope is tight |
| Knowledge retention | Highest | Low for internals, high for usage | Varies by handoff quality |
| Cost control | Strong long term, weak early | Predictable if usage is simple | Risky without milestone discipline |
| Best for | Teams with clear ownership and roadmap | Teams optimizing for simplicity | Teams needing expertise they don’t yet have |
What to ask before you shortlist anyone
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, the best buyers don’t start with rate cards. They start with delivery shape, minimum project thresholds, and proof that the consultancy has implemented the exact stack they’re recommending.
Use this checklist in first-round conversations:
- Architecture fit: Ask which parts of the proposed stack the vendor would avoid for your current stage.
- Implementation ownership: Ask who writes dbt models, who owns Airflow DAGs, and who documents lineage.
- Cost exposure: Ask what specifically increases warehouse and orchestration spend after launch.
- Handoff quality: Ask what your internal engineer should be able to run independently by project end.
- Milestone discipline: Ask for fixed deliverables tied to business outcomes, not just sprint burn.
- Platform bias: Ask how many active Snowflake, Databricks, BigQuery, and AWS implementations they maintain.
If you need a stronger screening process, this checklist for how to evaluate data engineering vendors is a useful companion.
A consultant who refuses to narrow scope in the first meeting is already telling you how the engagement will go.
My vendor selection rule
Never hire a firm to “build your data platform.” Hire a firm to deliver a defined operating capability. For example: centralize revenue and product data in Snowflake, implement dbt models for board reporting, train one internal owner, and leave documented runbooks.
That language protects you from architecture theater.
Your First 90 Days A Practical Implementation Roadmap
A startup data project should show business value inside the first month. If it doesn’t, the team loses confidence, leadership changes priorities, and the work drifts into backlog purgatory.
Use three 30-day sprints. Keep scope tight. Avoid the big-bang rollout that creates technical debt before anyone gets value.

Days 1 to 30
Stand up the core warehouse and land the fewest sources that answer the most important questions. For most startups, that means billing, CRM, and product analytics.
Deliver one dashboard that leadership already argues about. Usually revenue, activation, or funnel conversion. Not five dashboards. One.
Days 31 to 60
Introduce dbt. Move business logic out of ad hoc SQL and into versioned models with tests on critical fields.
Then train your first non-engineering users. Don’t wait for perfection. A good self-service motion starts when someone in finance or growth can answer a common question without filing a ticket.
Here’s the hiring angle most teams ignore: once the first sprint proves value, you can define the permanent owner role far better. If you’re drafting that role after the stack starts taking shape, this guide on crafting data engineer job roles helps tighten expectations around ownership, platform work, and collaboration.
Days 61 to 90
Add the controls that keep the whole thing from collapsing under growth.
Use a lightweight hardening checklist:
- Data quality tests on core dbt models.
- Access controls at warehouse level for finance, product, and exec views.
- Documentation for source freshness, model definitions, and dashboard owners.
- Runbooks for failed pipelines and common support issues.
The first 90 days are for proving reliability and usefulness, not for collecting every possible data source.
This phased approach is what keeps a startup from scaling noise.
Data Governance That Isnt a Buzzkill
Most startup teams hate governance because they’ve only seen the enterprise version. Endless approvals, vague ownership, and policies nobody reads. That isn’t governance. That’s theater.
Real governance in data engineering for startups is practical. It answers painful questions fast. Why does finance count customers one way and product another? Who can see compensation data? Which table should anyone trust?
What lightweight governance actually includes
Start with these four controls:
- Shared definitions: One documented definition for customer, active user, churn, revenue.
- Role-based access: Finance sees payroll. Product doesn’t.
- Data quality checks: dbt tests on keys, freshness, and accepted values for business-critical models.
- Owner tags: Every dashboard and model has a named person responsible for it.
That’s enough to eliminate a surprising amount of chaos.
The anti-bureaucracy operating model
Use governance where mistrust is expensive. Don’t wrap every table in process. Your highest-value datasets deserve standards. Your experimental sandbox does not.
A simple split works well:
| Data type | Governance level |
|---|---|
| Board and finance metrics | Strict definitions, access control, testing |
| Operational dashboards | Shared definitions, moderate testing |
| Exploration and prototypes | Minimal controls, expiration expectations |
This keeps speed where speed matters and discipline where mistakes are costly.
For a broader operating checklist, this summary of 8 data governance best practice essentials is a useful reference to adapt, not copy wholesale.
The rule I push with founders
If a metric appears in a board deck, funding memo, or customer-facing SLA, govern it. If it’s a scratchpad analysis, don’t turn it into a policy artifact.
Governance should remove recurring arguments. If it adds new ones, you designed it badly.
Planning for Hypergrowth and AI Enablement
AI plans fail for the same reason startup analytics stacks fail. Teams want outcomes before they build the operating substrate.
That’s not a philosophical point. 90% of AI and machine learning projects directly depend on resilient data engineering pipelines, and AI project failure can exceed 80% without a reliable data foundation. The same benchmark set notes that over 80% of startups use cloud-managed data engineering tools for faster deployment and predictable costs, according to Folio3’s data engineering market and startup benchmark roundup.

Signals that your stack needs to evolve
You don’t upgrade because a board member asked about AI. You upgrade when the workload changes.
Look for these triggers:
- Batch is too slow: Product or operations need fresher decisions than scheduled warehouse loads can support.
- The warehouse is carrying too much logic: Transformations, feature prep, and analytics all compete for the same operational envelope.
- Data domains are multiplying: New product lines, regions, or business units require lineage and ownership standards.
- ML use cases are real: Forecasting, personalization, risk scoring, or support automation now have a committed business owner.
That’s when more advanced architecture earns its keep.
What AI-ready actually means
An AI-ready startup stack isn’t defined by a vector database slide or a flashy orchestration layer. It means you can produce trusted datasets consistently, document where they came from, and reproduce them when models drift or auditors ask hard questions.
That usually means:
| Capability | Why it matters |
|---|---|
| Reliable ingestion | Models fail when source data shifts silently |
| Versioned transformations | Training and inference need reproducible logic |
| Lineage | Teams must trace predictions back to source data |
| Access control | Sensitive data can’t leak into model pipelines |
If you’re planning the next layer of AI capability, this primer on building an effective AI stack is a useful external read because it frames AI as a systems decision, not just a model decision.
My opinionated recommendation
For most startups, the shortest path to AI value is boring work done well: clean warehouse tables, tested dbt models, disciplined metadata, and cloud-managed services your team can operate.
That is what enables experimentation without wrecking reliability.
Your Next Three Actions to Build a Data-Driven Startup
Stop researching and make three decisions this week.
1. Place your company in the right maturity stage
Use the model above and write down your current stage, your next stage, and the one business question that matters most before the next fundraise or planning cycle.
If you can’t name that question, your data roadmap is already too abstract.
2. Pick the stack you can run with current ownership
Choose one of the three patterns. Then list the exact owner for warehouse administration, pipeline monitoring, dbt review, and dashboard definitions.
If those owners don’t exist, don’t pretend you have an in-house strategy. You have a procurement decision.
3. Run a disciplined vendor screen before you buy help
If you need outside support, use a shortlist process with milestone-based scope, handoff requirements, and explicit questions about platform bias, documentation, and operating cost. Then compare firms with actual data instead of polished pitch decks.
DataEngineeringCompanies.com is useful at this point because it gives buyers practical tools instead of generic vendor hype. Start with the firm profiles, cost calculator, and match quiz at DataEngineeringCompanies.com if you want to benchmark partners before you commit budget.
The startups that win with data engineering aren’t the ones with the fanciest architecture. They’re the ones that build only what the business can absorb, insist on operational ownership, and refuse to let vendors define the roadmap for them.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Top Enterprise Partners
Vetted firms whose specialty matches this article.
More in Enterprise Data Engineering

Strategic Data Engineering ROI Measurement for CTOs
Master data engineering ROI measurement with our 2026 guide. Get frameworks, KPIs, and templates to justify investments and evaluate partners.

Build vs Buy Data Platform: An Engineering Leader's Decision Framework in 2026
Deciding on a build vs buy data platform? This guide provides a TCO model, performance benchmarks, and a decision framework for engineering leaders.

A Pragmatic Guide to Data Engineering Project Management
Master data engineering project management with this playbook. Learn proven strategies for on-time delivery of complex data pipelines and cloud platforms.