Data Engineering for AI Companies: A Strategic Guide

Most AI roadmaps fail in the same place: leadership funds models before it funds the data platform that keeps those models alive.
That mistake is getting easier to make, not harder. Stanford HAI’s 2025 AI Index says 78% of organizations used AI in 2024, up from 55% in 2023, and McKinsey’s 2025 global survey found 88% of respondents said their organizations were using AI in at least one business function. In the same period, U.S. private AI investment reached $109.1 billion in 2024, and generative AI drew $33.9 billion globally in private investment according to the Stanford HAI 2025 AI Index. The implication for CTOs is simple: data engineering for AI companies is no longer a supporting function. It’s a core operating capability.
If you’re launching a serious AI initiative, the hard decisions aren’t about prompts or model benchmarks. They’re about pipeline architecture, platform fit, governance design, semantic readiness, and whether your team or consulting partner can ship a production-grade foundation fast enough.
The Hidden Drag on Your AI Initiatives
The most useful statistic in AI hiring has nothing to do with models. It’s the imbalance behind them.
One labor-market analysis found AI roles outnumber data infrastructure positions by 31%, creating a gap of nearly 35,000 jobs, and AI specialists command salaries about $15,680 higher on average. That’s why so many companies overhire visible AI talent while underfunding ingestion, transformation, quality, lineage, and platform engineering, as outlined in DoubleTrack’s analysis of AI hiring without data foundations.
What CTOs get wrong
Teams usually say they have an AI problem. They don’t. They have one of four data problems:
- Fragmented ingestion that leaves training and inference pipelines fed by different source logic
- Weak quality controls that let bad joins, null spikes, and schema drift hit downstream apps
- No governance path for sensitive data moving into RAG, feature pipelines, or model evaluation
- No ownership model for the platform itself, so every team improvises
You can’t fix that by adding another model engineer.
Practical rule: If your AI team is waiting on source mapping, schema cleanup, access policies, or observability, your bottleneck is data engineering, not ML.
The first leadership move is to stop treating data infrastructure as plumbing. For AI companies, it’s production infrastructure. The second move is to force a quality operating model early. A practical reference point is NineArchs’ data quality framework, which is useful because it pushes teams to define ownership, controls, and measurable checks before platform sprawl makes those decisions expensive.
The real leadership question
The question isn’t whether to invest in AI. Your board already answered that.
The question is whether you’ll fund the unglamorous systems that let AI survive contact with messy source systems, changing schemas, access controls, and real user traffic. If you don’t, your initiative becomes a demo factory. It produces pilots, not products.
That’s why the first procurement decision should sit with the CTO, Head of Data, and platform owner together. Don’t let this get scoped as a narrow BI modernization project. It’s a data platform program with AI delivery as the business outcome.
AI-Centric Data Architecture Patterns
A generic modern data stack won’t carry a serious AI program. AI workloads need architectures that handle structured analytics, unstructured retrieval, and governed operational reuse without turning the platform into a pile of disconnected services.
Deloitte makes the core issue plain: generative AI systems consume heterogeneous, multimodal data, and when data strategy, ontology, and governance are not aligned, retraining cost rises and accuracy degrades. The answer is to design for probabilistic workloads, apply governance at ingestion, and use RAG with human oversight, as discussed in Deloitte’s guidance on data integrity in AI engineering.
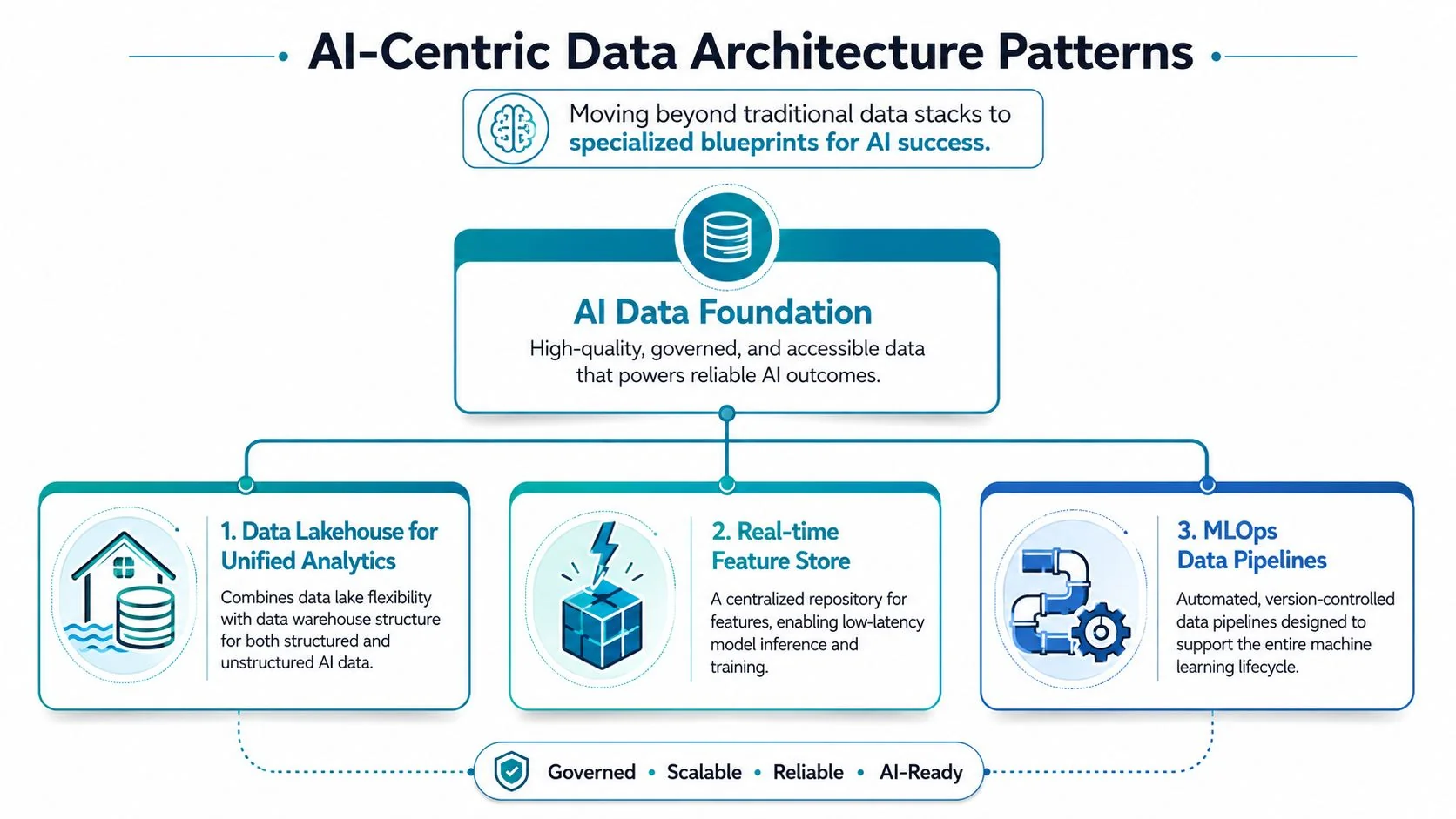
Pattern one, Lakehouse for governed core data
For most AI companies, the right base pattern is a lakehouse with clear raw, validated, and curated layers.
Use it when you need one governed platform for analytics, batch ML preparation, and selective support for unstructured assets. The point isn’t the medallion diagram itself. The point is enforcing where cleansing happens, where business logic lives, and which layer downstream AI consumers can trust.
This pattern works best when:
| Decision area | Recommendation |
|---|---|
| Source diversity | Centralize ingestion from product, app, event, and third-party systems |
| Team skill mix | Favor this when SQL analytics and platform engineering both matter |
| Governance need | Use it when auditability and lineage need to be consistent across teams |
| AI scope | Strong fit for mixed analytics, ML features, and light GenAI enrichment |
If your team skips layer discipline, the lakehouse becomes a dumping ground. That’s not architecture. That’s object storage with branding.
Pattern two, dedicated RAG pipelines for unstructured data
RAG should not piggyback casually on your BI pipeline. It needs its own ingestion, chunking, metadata enrichment, access control, and refresh logic.
Your RAG path should answer these questions clearly:
- Document handling: How do PDFs, transcripts, tickets, and knowledge assets get parsed and normalized?
- Chunking logic: Who owns chunk size, overlap, and re-index rules?
- Metadata design: Can the system explain source, freshness, owner, sensitivity, and domain context?
- Access control: Are retrieval permissions aligned with the source system?
- Evaluation loop: Can you trace retrieval quality and bad answers back to source content?
RAG fails quietly when retrieval quality is weak. The model still answers. It just answers with confidence and the wrong context.
Treat vector search as the serving layer, not the whole system. The engineering work is upstream.
Pattern three, feature stores and reusable ML data products
If you’re building classical ML alongside GenAI, add a feature store pattern instead of rebuilding training logic in every team.
A feature store matters when multiple models need consistent business definitions, online and offline parity, or repeatable training sets. It also forces useful discipline. Teams have to name features properly, document lineage, and stop shipping one-off transformations inside notebooks.
Use this pattern when:
- Multiple models share business entities such as users, merchants, accounts, devices, or content items.
- Inference latency matters and feature serving needs to be predictable.
- Training reproducibility matters for regulated, revenue-linked, or customer-facing decisions.
What I’d standardize first
For data engineering for AI companies, I’d standardize four things before debating niche tools:
- One ingestion pattern for batch and event-fed core sources
- One transformation framework such as dbt for declarative warehouse logic
- One orchestration layer such as Airflow or the native orchestrator of your chosen platform
- One metadata and lineage model that serves both humans and AI systems
If those four are inconsistent, every later AI decision gets slower and more political.
Platform Showdown Snowflake vs Databricks for AI
Many teams don’t need a philosophical debate here. They need a decision rule.
Pick the platform that best matches your dominant workloads and your team’s real skills, not the one with the louder AI narrative. Snowflake and Databricks can both support AI programs. They just pull your operating model in different directions.
A useful visual summary is below.
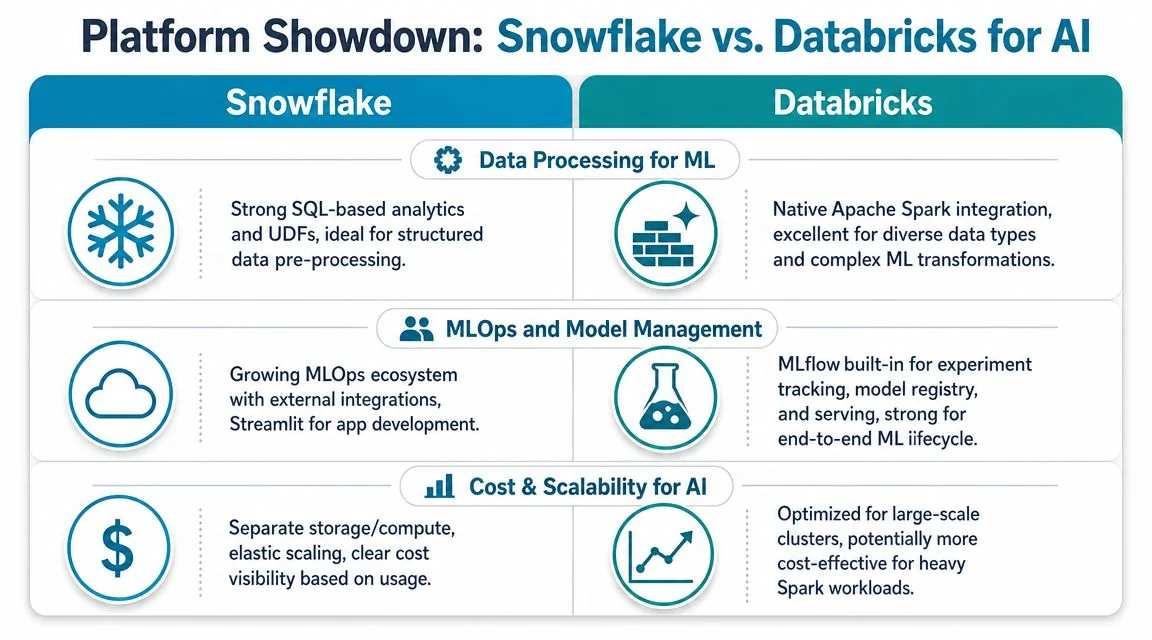
Where Snowflake wins
Snowflake is the cleaner choice when your center of gravity is still warehouse-led, SQL-heavy, and analytics-governed.
It fits best when your team already thinks in terms of governed datasets, dbt models, and tightly managed access. It’s often the more straightforward route for organizations that want broad analyst adoption, separated compute and storage economics, and a lower coordination burden between analytics engineering and platform administration.
Snowflake is usually the stronger fit if:
- Your data team is SQL-first
- Your AI use cases depend on curated structured data before model layers
- You want governance to feel warehouse-native rather than Spark-native
- You expect many downstream business users, not just data scientists
If you’re hiring around this stack, the shape of the talent market matters. Reviewing high-quality Snowflake roles is a practical way to gauge how mature the ecosystem is and what skills you’ll need to retain internally.
Where Databricks wins
Databricks is the better choice when your AI agenda is engineering-heavy, Python-heavy, and closely tied to large-scale data processing.
It’s stronger when your teams work across structured and unstructured data, need native Spark patterns, or want a tighter path from data prep to ML lifecycle management. If your data scientists and ML engineers already live in notebooks and code-first workflows, Databricks reduces friction.
It’s usually the better fit if:
- Your transformation logic is complex and compute-intensive
- Your teams are comfortable with Spark and Python
- You need closer integration between data engineering and model experimentation
- Your GenAI roadmap involves more unstructured processing and custom pipelines
The wrong reason to choose Databricks is that it sounds more “AI-native.” The right reason is that your organization already operates like an engineering-led ML shop.
Here’s the comparison I use with clients:
| Decision factor | Snowflake | Databricks |
|---|---|---|
| Team profile | SQL analysts, analytics engineers, governed BI teams | Data engineers, ML engineers, Python-heavy data science teams |
| Core strength | Structured analytics and managed warehouse operations | Large-scale transformation and ML-centric engineering |
| Governance posture | Warehouse-centric controls and curated data sharing | Lakehouse-centric controls with engineering flexibility |
| Best AI fit | Structured data prep, governed AI consumption, enterprise analytics | Complex ML pipelines, multimodal prep, experimentation-heavy AI |
For a deeper side-by-side framework, this Snowflake vs Databricks comparison is a useful procurement reference because it frames the decision around workloads and delivery needs rather than brand preference.
Later in the decision cycle, watch this overview with your platform owner and lead architect, not just procurement.
Don’t buy a platform and then ask your team to reinvent itself around it. Buy the platform your team can run well in production.
Structuring Your Data Team for AI Scale
Most companies don’t need a pure in-house team or a pure consultancy model. They need a blended structure with clear ownership boundaries.
The labor market supports that conclusion. ElectroIQ estimates the global big data engineering services market at $91.54 billion, with a projection to $187.19 billion by 2030 at a 15.38% CAGR. The same source says outsourcing data engineering is projected to grow at a 10.2% CAGR from 2023 to 2028, reflecting how companies increasingly buy external expertise for platform modernization and AI enablement, according to ElectroIQ’s 2025 data engineering statistics.
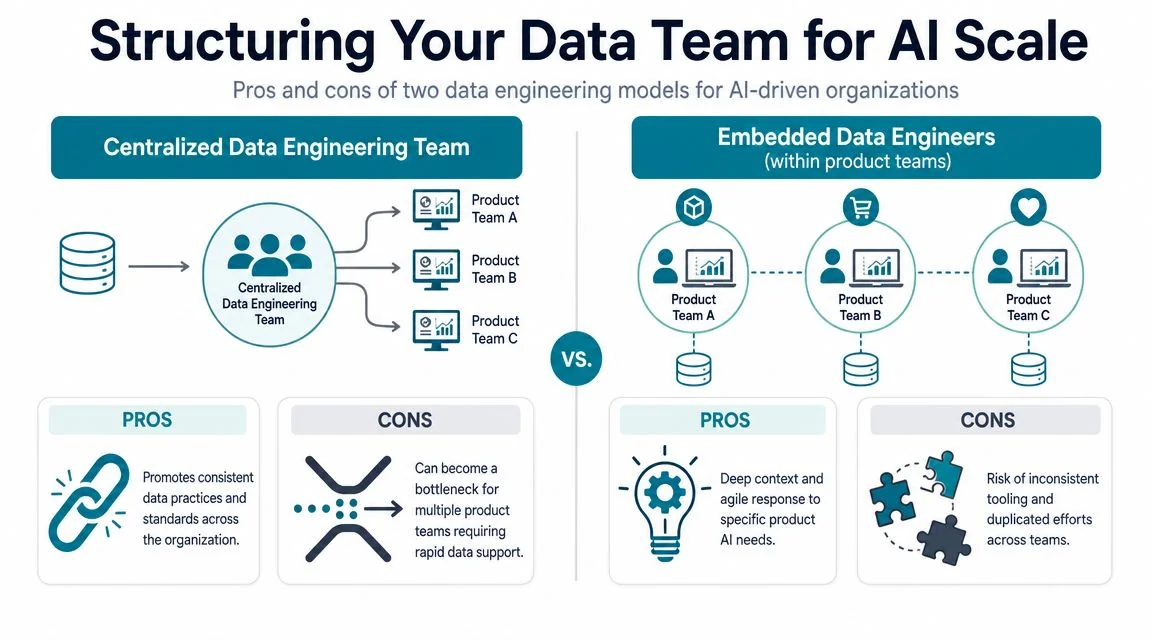
Build in house for control
Build internally when the data platform is part of your product moat or regulatory posture.
That means platform ownership, governance design, data contracts, and core transformation standards should usually stay with your team. These are operating decisions, not just delivery tasks. If a partner owns them too long, you inherit a black box.
Internal ownership should cover:
- Platform roadmap and cloud alignment
- Canonical data models for core entities
- Access policy design and governance decisions
- Acceptance criteria for reliability, lineage, and observability
Use a consultancy for speed and specialization
Bring in a consulting partner when you need acceleration, migration experience, or a skill set your team doesn’t have yet.
That’s especially true for first-time Snowflake or Databricks implementations, cross-cloud migrations, RAG pipeline architecture, or standing up orchestration and CI/CD patterns fast. Good partners compress decision time because they’ve already seen the failure modes.
The model I recommend most often is simple:
- Internal leaders own architecture and standards
- The consultancy owns implementation velocity in defined workstreams
- Knowledge transfer is scheduled from day one, not the end
Centralized versus embedded
Within your internal team, don’t choose an extreme.
A centralized data engineering team enforces consistency across ingestion, transformation, and governance. Embedded data engineers inside product teams move faster on specific AI use cases. The practical answer is a platform core with selective embedding for teams building revenue-critical or customer-facing AI products.
If every team builds its own pipelines, governance breaks. If all work queues through one central team, delivery stalls. Balance it deliberately.
Integrating Data Governance with MLOps
Governance and MLOps are the same delivery system viewed from different angles.
Governance asks whether data is trusted, controlled, and explainable. MLOps asks whether model inputs, outputs, and retraining cycles are reproducible and observable. If those are managed separately, your AI stack gets brittle fast.
What mature teams automate
A practical pattern for AI platforms is automating repetitive operations such as schema updates, data-quality checks, and observability. LakeFS and Lumenalta emphasize write-audit-publish controls, automated schema generation, and real-time monitoring because these practices reduce manual transformation work and surface anomalies earlier, as described in lakeFS’s overview of AI data engineering patterns.
That’s exactly where data governance becomes useful instead of bureaucratic.
Use automation to enforce:
- Versioned training and serving datasets
- Lineage from source tables to model inputs
- Contract checks on critical schemas
- Monitoring for freshness, null spikes, and drift signals
- Controlled publication of approved datasets for downstream AI use
A useful companion principle comes from compliance training outside engineering. Even an essential guide for aspiring accounting professionals reinforces the same foundational point: sensitive data handling fails when teams rely on informal habits instead of defined controls. In AI systems, that problem gets magnified.
Data contracts are the bridge
If you want governance that doesn’t block shipping, use data contracts between producers and consumers.
That means product teams, event owners, and source-system teams commit to schema, freshness, ownership, and change processes. Then your orchestration and testing layers enforce those commitments automatically. This is one of the most practical ways to connect upstream engineering discipline with downstream model reliability. A concise framework is this guide on data contracts in data engineering.
The cleanest MLOps stack in the world won’t save you if upstream data changes without warning.
What to insist on in production
Ask your team one hard question: if a model answer is challenged by a customer, regulator, or internal stakeholder, can you trace the answer back to the exact governed data state that produced it?
If the answer is no, you don’t have production AI. You have a probabilistic application sitting on undocumented assumptions.
The RFP Checklist for Data Engineering Partners
Most vendor evaluations fail because the buyer asks broad questions and gets polished broad answers. Force specificity.
A strong RFP for data engineering for AI companies should test architecture judgment, platform depth, governance maturity, and delivery discipline. It should also expose whether the partner has built AI-enabling data platforms or just renamed standard BI work.
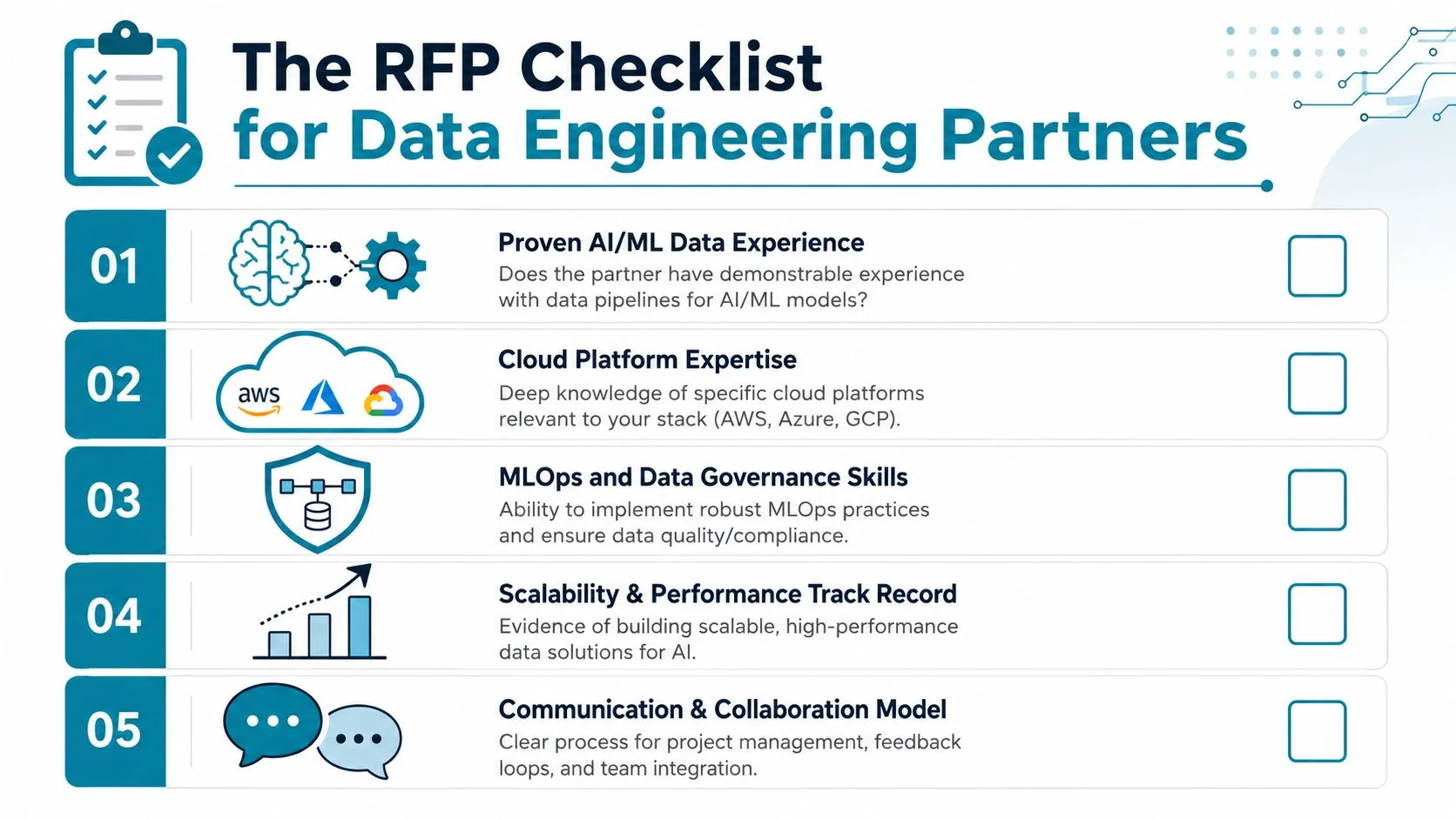
Technical fit questions
Ask these in writing:
- Platform depth: Which of Snowflake, Databricks, dbt, Airflow, AWS, Azure, and BigQuery does your proposed team implement directly, and which do you partner out?
- Architecture judgment: When do you recommend warehouse-first, lakehouse-first, or hybrid patterns for AI workloads?
- Unstructured data: How do you design ingestion and metadata pipelines for RAG systems?
- Semantic layer readiness: How do you make tables, columns, and business entities understandable to LLMs and agents?
Don’t accept capability lists. Ask for implementation patterns.
Delivery model questions
Use these to expose execution risk:
| Area | Ask this |
|---|---|
| Discovery | What artifacts do you produce before recommending a target architecture? |
| Governance | How do you implement lineage, access controls, and quality gates from the start? |
| Orchestration | Which scheduler or native orchestration pattern do you standardize on, and why? |
| Handover | What knowledge transfer happens during the build, not after it? |
Team composition questions
Insist on named roles, not generic pods.
Ask for the actual blend of data architect, platform engineer, analytics engineer, governance lead, and ML-adjacent expertise. If the team is all generalists, expect slower decisions and more rework.
Good partners don’t hide behind “full-stack data engineers.” They tell you exactly who handles architecture, pipelines, governance, and release management.
Commercial and operating questions
These usually reveal more than the technical pitch.
- Pricing model: Is this fixed scope, time and materials, or milestone-based?
- Change process: How are architecture shifts priced after discovery?
- Support model: Who owns incidents and platform stabilization after go-live?
- Exit plan: What happens if you need to internalize the function after the first phase?
If you want a structured shortlist tool, DataEngineeringCompanies.com is one factual option because it aggregates firm profiles, capabilities, project thresholds, and evaluation tools for data engineering buyers.
Sizing Costs and Spotting Red Flags
Most AI data programs are underbudgeted because the spreadsheet includes platform licenses and ignores the operational layer.
Budget for five buckets: cloud infrastructure, platform services, implementation effort, governance and observability, and ongoing operating ownership. If one of those is missing, the plan isn’t real.
What smart buyers size early
Don’t ask only what Snowflake or Databricks costs. Ask what your chosen operating model costs.
That includes:
- Initial implementation work across ingestion, modeling, orchestration, governance, and CI/CD
- Migration effort if legacy pipelines or warehouses must be retired
- Support overhead for incidents, performance tuning, and schema change management
- Semantic enablement so AI systems can understand and use the data you publish
The last item is where many teams still miss the shift. Industry discussion is moving beyond tooling toward semantic readiness for LLMs and agents, meaning data must be discoverable, explainable, and usable by AI systems through metadata, semantic layers, table and column explanations, and similar interfaces, as discussed in this industry conversation on LLM-friendly data products.
Red flags that should stop the deal
If a vendor or internal plan shows any of these, slow down:
- They prescribe the platform before discovery. That usually means they’re selling inventory, not solving your problem.
- They treat AI data engineering as a migration only. Moving data isn’t enough. You need governance, observability, and semantic design.
- They can’t explain RAG data controls. If they talk only about vector databases, they don’t understand retrieval systems.
- They have no stance on dbt, Airflow, or native orchestration trade-offs. That signals weak operating judgment.
- They leave knowledge transfer until the end. That’s how dependency gets locked in.
- They don’t define ownership after launch. Production systems decay without named owners.
The next move
Run your initiative like a platform procurement, not a model experiment.
Write the target architecture. Decide whether your operating center is Snowflake, Databricks, or BigQuery. Define governance at ingestion. Separate RAG pipelines from standard BI flows. Then test every consulting partner against a hard RFP that forces proof, named roles, and delivery specifics.
If you’re making one decision this quarter, make it this one: fund the data foundation before you fund more AI surface area. That’s how AI programs reach production and stay there.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Featured Data Engineering Partners
Vetted firms whose specialty matches this article.
Related Analysis

Top Data Engineering Managed Services for 2026
Compare leading data engineering managed services. Find models, pricing, & vendors. Use our RFP checklist to select your ideal Snowflake or Databricks partner.

Data Engineering Vendor Scorecard Template (Free Download)
Download our free Data Engineering Vendor Scorecard Template. This guide explains our 8-factor methodology to help you evaluate and select the best consultancy.

Data Engineering Staff Augmentation: A 2026 Playbook
Your authoritative guide to data engineering staff augmentation. Learn when to use it, how to vet vendors, benchmark rates, and manage engagements for max ROI.