Airflow vs Prefect vs Dagster: A 2026 Decision Guide for Engineering Leaders

Selecting between Airflow, Prefect, and Dagster is a critical architectural decision that defines your data platform’s trajectory. The choice comes down to a core philosophical difference: Airflow is the established standard for stable, predictable batch ETL at scale. Prefect excels at managing dynamic, failure-resistant Pythonic workflows. Dagster is built from the ground up for data-aware, asset-centric development and governance. This guide is a decision framework for engineering leaders to select an orchestrator that accelerates data strategy, not one that creates technical debt. This article belongs to the Data Pipeline Architecture hub.
The Orchestrator Decision Framework
Choosing a data orchestrator is a strategic choice that directly impacts team productivity, operational overhead, and data governance. The decision between Apache Airflow, Prefect, and Dagster hinges on your organization’s primary objective.
Are you standardizing mature, large-scale batch processes that must run reliably? Do you require a flexible engine for dynamic, event-driven applications where failure is an expected part of operation? Or is the main goal to build a clean, maintainable data platform with transparent asset lineage from day one?
Quick Comparison: Airflow vs. Prefect vs. Dagster
| Criterion | Apache Airflow | Prefect | Dagster |
|---|---|---|---|
| Core Model | Task-oriented, imperative | Flow-based, hybrid | Asset-centric, declarative |
| Ideal User | Enterprise teams with mature batch ETL | Teams needing dynamic, Python-native workflows | Data platform teams focused on lineage and testing |
| Primary Strength | Unmatched ecosystem and industry adoption | Developer experience and resilient execution | Integrated data lineage and local development |
This table provides the high-level view. Each model has profound implications for how your team will build, test, and maintain data pipelines.
This decision tree visualizes the selection process based on what you value most: raw throughput, handling complex logic, or maintaining a clear view of your data assets.
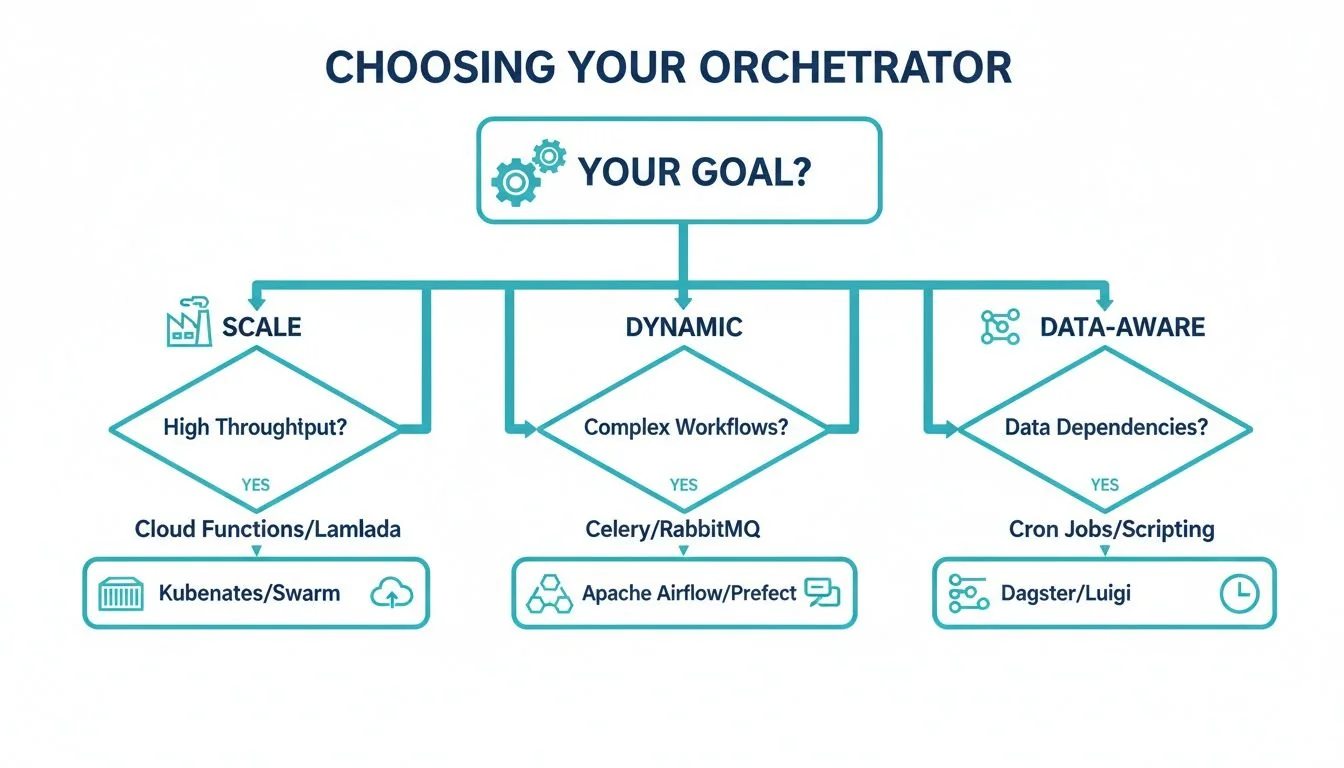
As the chart shows, the first question is about your primary driver. Airflow is the go-to for battle-tested scale, Prefect is built for dynamic and unpredictable workflows, and Dagster is designed for teams who think in terms of data assets and their dependencies.
Understanding where these tools fit within the broader landscape of AI workflow automation tools also informs your strategy. Now, let’s map these technical differences to real-world scenarios.
Head-to-Head on Architectural Philosophy
The real decision between Airflow, Prefect, and Dagster lies in their fundamentally different architectural philosophies. This distinction directly shapes how engineers build, test, and debug pipelines.
Apache Airflow operates on a traditional, imperative model where you define tasks and explicitly wire them into a Directed Acyclic Graph (DAG). It’s a task-centric world, battle-tested and effective for classic batch ETL where the sequence of operations is static.
For an engineering leader, Airflow offers a proven model for stable, high-volume workloads. Its rigidity is a double-edged sword. Local testing is cumbersome, and debugging is difficult because the focus is on what to run, not what data is being produced.
The Move Toward Dynamic and Data-Aware Orchestration
Prefect takes a different tack with its “code as workflows” model. Simple Python decorators turn any function into a workflow step. This unlocks dynamic DAGs that change at runtime, providing flexibility for complex application logic or event-driven pipelines. Prefect’s design prioritizes resilient execution.
Then there’s Dagster, which brings a declarative, data-aware philosophy. Instead of thinking in terms of tasks, your team defines software-defined assets—the tables, files, or ML models you want to produce. Dagster intelligently infers the steps needed to create them, building the DAG automatically from asset dependencies. This is a profound shift from a task-centric to an asset-centric mindset.
This difference has real-world consequences. Dagster’s asset-first approach makes data lineage a native part of the system, simplifying governance and observability. To achieve the same insight in Airflow, you must bolt on and manage other tools. Our detailed comparison of data orchestration platforms digs deeper into these ecosystem trade-offs.
Airflow holds its dominant position thanks to its massive community and enterprise track record. It is a reliable choice for large-scale, predictable jobs. However, its stability comes at a cost; its steep learning curve and operational complexity lead to 25% higher overhead in more dynamic environments compared to modern alternatives.
Picking between these tools is a strategic bet on a development philosophy. Do you want your team managing tasks, orchestrating flexible code, or declaring data assets? The answer defines the long-term scalability and maintainability of your data platform.
Analyzing Scalability, Deployment, and Operational Costs
For an enterprise architect, an orchestrator’s scalability, deployment model, and total cost of ownership (TCO) are critical. The architectural philosophy of each tool directly impacts operational overhead and infrastructure spend, so it’s crucial to see how they align with modern Data Engineering Best Practices for scalable systems.
Let’s break down how Airflow, Prefect, and Dagster stack up.
Running Airflow at scale reveals its monolithic scheduler as a potential bottleneck. While newer versions have a highly available scheduler, proper configuration requires significant operational expertise, often involving complex Celery or Kubernetes executor setups. This puts a heavy lift on your platform team to manage infrastructure and prevent the scheduler from becoming a single point of failure.
Decoupled Execution and Cloud-Native Design
Prefect and Dagster change the game with modern architectures that decouple orchestration from execution. Prefect’s agent-based model is a prime example: the control plane (Prefect Cloud or your server) dispatches work to agents running securely within your environment. This design means data and code never leave your VPC, and you can scale execution resources independently.
A key advantage of Prefect’s agent model is its ability to scale down to zero. This aligns perfectly with serverless paradigms, as resources are only provisioned when a flow run is active, dramatically reducing idle infrastructure costs—a common pain point in Airflow deployments.
Dagster was built from the ground up for containerized environments like Kubernetes. Its architecture uses gRPC to create a hard boundary between user code and core system components. This isolation is a huge win for stability—it prevents a bug in user code from crashing the entire scheduler—and simplifies deployments in a cloud-native world.
Managed Services vs. Self-Hosting TCO
The decision between self-hosting and a managed service (like Astronomer for Airflow, Prefect Cloud, or Dagster Cloud) is a major factor in TCO. Self-hosting avoids subscription fees but transfers the full operational cost of security, compliance, upgrades, and scaling to your team.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, a team managing a self-hosted Airflow instance for 500+ pipelines spends an average of 1.5 full-time engineers (FTEs) on platform maintenance. In contrast, managed services reduce that to less than 0.5 FTEs. That’s a potential savings of over $200,000 in annual engineering salary that can be redirected from maintenance to value creation.
All three vendors now offer compelling hybrid deployment models. These manage the control plane for you while data processing stays securely within your cloud, offering a balance between convenience and control.
Evaluating Developer Experience and Observability
For an engineering leader, developer velocity is a bottom-line metric. The right orchestrator empowers engineers to build, test, and debug at speed; the wrong one creates friction. The differences in developer experience and built-in observability between Airflow, Prefect, and Dagster are stark.

Dagster and Prefect deliver a superior local development and testing experience. They were built for the modern developer loop: code, test, and iterate on a local machine before deployment.
Local Development and Testing Speed
With its asset-based model and integrated UI (Dagit), Dagster lets you materialize assets and see dependencies on your laptop. This provides instant feedback that dramatically cuts debugging time. Prefect’s “code as workflows” approach is just as natural, allowing engineers to test flows like any other Python function, free from cumbersome boilerplate.
Airflow’s local development is clunky. Its architecture often requires a full-stack environment, meaning you wrestle with complex Docker Compose files to test a single DAG. This friction slows onboarding and iteration, as developers often push code to a shared dev environment just to see if it works.
Out-of-the-Box Observability
True observability is not just about logs; it’s about understanding the health and lineage of your data. Dagster’s design philosophy shines here.
- Dagster: Out of the box, you get an integrated data catalog and a visual asset lineage graph. Because every run is tied to an asset, Dagster automatically tracks metadata, upstream dependencies, and data freshness with no extra work.
- Prefect: Its event-based logging system provides a detailed, real-time view of every flow run. The UI is clean and offers deep insights into task states and execution history.
- Airflow: Airflow uses a traditional task-logging system. It works, but it lacks the built-in data context of Dagster. To get real data lineage, you must integrate and manage a third-party tool like OpenLineage.
The ability to trace data dependencies and check pipeline health without third-party tools is a massive advantage. We dive deeper into this in our guide on what data observability is and why it is critical for modern data platforms.
Dagster and Prefect offer a much more integrated and insightful experience, which translates directly into a more productive and effective data team.
Which Orchestrator Is Right for Your Use Case?
The Airflow vs. Prefect vs. Dagster debate has no single “best” tool. Each was built to solve a specific problem, and choosing one is a major commitment to a particular way of building data pipelines.
The real question is not which tool has the longest feature list, but which one aligns with your team’s experience, pipeline complexity, and corporate data governance strategy.
When to Choose Apache Airflow
Apache Airflow is the industry heavyweight. For large organizations with mature data teams running predictable, massive-scale batch jobs, it remains the standard. Its stability and vast ecosystem are undeniable.
Lean toward Airflow if your world looks like this:
- Predictable, High-Volume Batch Processing: You run thousands of time-based ETL jobs that must work. Your pipelines are well-defined and do not change frequently.
- A Mature Ecosystem is Non-Negotiable: You need to connect to everything. Airflow’s 2,000+ community providers give it unmatched connectivity.
- A Deep Talent Pool is Critical: You need to hire people who can be productive immediately. Airflow’s market dominance means experienced engineers are readily available.
Airflow is the safe harbor for enterprise ETL. Its reliability has been proven at a scale its competitors are still aiming for. For any CTO focused on managing operational risk, that is a huge plus.
When to Choose Prefect
Prefect was designed to handle the messy, unpredictable workflows where Airflow’s rigid structure cracks. It’s built for teams that need to react to real-world events in real time and want a truly Python-native development experience.
Consider Prefect for these challenges:
- Dynamic and Event-Driven Workflows: Your pipelines respond to incoming files, API calls, or other events, not just a clock. Prefect’s ability to generate DAGs at runtime is a huge advantage.
- Resilient Execution is a Must: Your workflows are complex and fail for reasons outside your control. Prefect’s sophisticated state management and retry logic are best-in-class for handling this.
- Cost-Efficient Scaling Matters: Your workloads come in bursts, with long periods of inactivity. Prefect’s agent-based model can scale resources to zero, eliminating payment for idle infrastructure.
When to Choose Dagster
Dagster represents a fundamentally different way of thinking. It’s the choice for organizations building a modern data platform and treating data as a product. Its core philosophy is built around data assets, not tasks.
Dagster is the right fit if your priorities are:
- Building a Data Mesh or “Data as a Product” Culture: You are moving toward a decentralized model where domain teams own their data products and clear accountability is essential.
- Integrated Governance and Lineage: You need a single source of truth for understanding how data is created and where it goes, without bolting on extra tools for lineage and observability.
- Developer Productivity and Local Testing: You want data engineers to work like software engineers, with fast local development cycles and robust testing. Dagster’s native
pytestintegration makes it a clear winner for testability.
Answering Key Questions on Orchestration Tools
When engineering leaders compare Airflow vs. Prefect vs. Dagster, the same tough questions arise. It is never just about features. You must consider the real cost of migration, what a managed service means for security, and how it all fits into your existing data stack.
Let’s get straight to the answers.
Estimating Migration Costs
Migrating from a tool as established as Airflow is a serious project, and the cost boils down to developer hours. What’s the real number?
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, a typical migration of 100-150 Airflow DAGs to Prefect or Dagster takes two engineers 3-4 months. This puts the price tag between $120,000 and $200,000.
The biggest variable is custom Airflow operators and macros. Those always require a complete rewrite. While that is a hefty upfront cost, many teams justify it. The improved workflows in Prefect or Dagster’s asset-centric model reduce long-term maintenance so much that they see a positive ROI within 18-24 months.
Security and Managed Services
Moving to a managed service like Astronomer, Prefect Cloud, or Dagster Cloud naturally brings up security concerns about vendor lock-in and data control.
All three providers have solved this with a hybrid deployment model. Your code, your data, and the execution environments stay inside your own VPC. The vendor’s cloud service only manages the control plane—it sends instructions but never touches the data itself.
This separation of concerns satisfies the strictest enterprise compliance standards, including SOC 2 and HIPAA. Your team’s job shifts from managing infrastructure to fine-tuning IAM roles and network policies that define how the vendor’s control plane can interact with your execution plane.
Integration with dbt and the Modern Stack
Seamless integration with tools like dbt, Snowflake, and Databricks is a dealbreaker. All three orchestrators get the job done, but in different ways.
- Dagster has the most seamless integration through its
dagster-dbtlibrary. It understands your dbt project, treating dbt models as first-class software assets. It automatically parses metadata and builds a complete lineage graph that traces data from source to final dashboard. - Prefect delivers a similarly polished experience with its
prefect-dbtcollection. Orchestrating dbt jobs feels native, with excellent observability out of the box. - Airflow’s integration works, but feels less native. You rely on community-built providers or custom Python code, which provides less built-in visibility compared to what Dagster and Prefect offer.
Picking the right data engineering partner is as important as choosing the right orchestrator. DataEngineeringCompanies.com uses data-driven rankings and reviews to help you vet top firms with confidence. Find your ideal data engineering consultancy and get your platform modernization on the fast track.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

The Engineering Leader's Guide to Supply Chain Data Platforms
Explore expert supply chain data engineering strategies for resilient pipelines, modern architecture, and data platform selection for Snowflake and Databricks.

A CTO's Guide to Ecommerce Data Engineering
Build a high-performance ecommerce data engineering architecture. Compare platforms, integration patterns, and vendor selection criteria for maximum ROI.

How to Hire an Apache Kafka Consulting Firm That Delivers
A guide for engineering leaders on scoping, vetting, and hiring the right Apache Kafka consulting partner. Learn to avoid pitfalls and maximize your ROI.