The Engineering Leader's Guide to Supply Chain Data Platforms

Your supply chain analytics are a liability. They were designed for a predictable world that no longer exists, leaving you to manage modern disruptions with stale, batch-processed data. Making decisions based on what happened yesterday is a direct path to stockouts, bloated inventory costs, and missed delivery targets.
The core problem is the disconnect between your operational speed and your data speed. When a container is delayed or demand spikes, last night’s data is useless. This forces expensive, reactive decisions. The only way to fix this is by building a modern data platform.
This guide provides an actionable framework for engineering leaders to design, build, and procure the necessary supply chain data engineering capabilities. We will cover pipeline architecture, platform selection between Snowflake and Databricks, data governance, and partner evaluation, using benchmarks from our proprietary dataset.
Why Legacy Supply Chain Analytics Fail
Legacy analytics setups, typically pulling from a monolithic ERP or Warehouse Management System (WMS), are fundamentally broken. They cannot keep up with the volatility of today’s supply chains. This structural failure manifests in three critical business areas:
- Increased Stockouts: Inability to detect real-time demand surges means you cannot adjust inventory levels fast enough, leading to empty shelves and lost revenue.
- Inflated Inventory Costs: To buffer against uncertainty from poor data, you hold excess “just in case” stock. This ties up working capital and erodes profit margins.
- Inaccurate Delivery ETAs: Without a live, end-to-end view of logistics, delivery estimates are guesswork. This damages customer trust and operational efficiency.
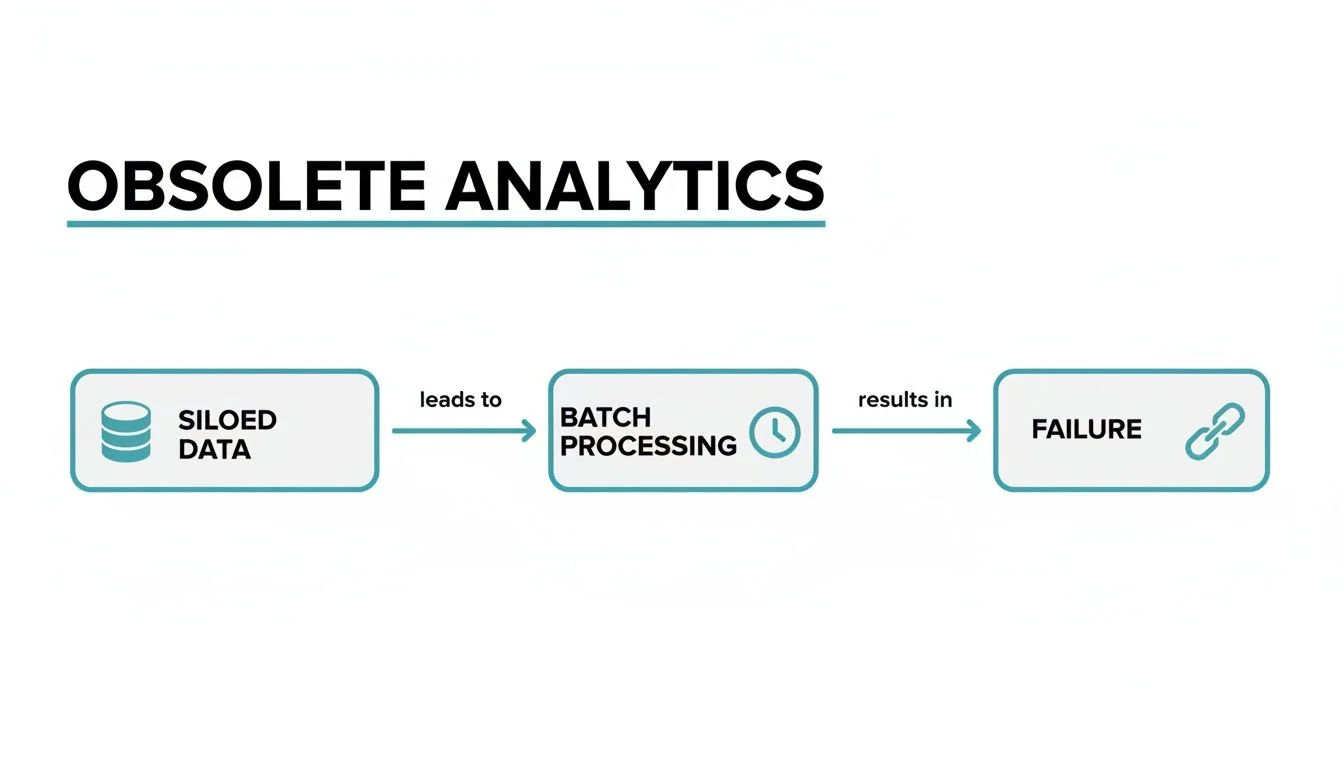
The outdated flow—where siloed data is trapped in slow, overnight batch jobs—creates the blind spots that lead to these costly failures. A modern data platform replaces it with a unified, near real-time engine. This is a strategic imperative for building a resilient, automated operation that shifts from firefighting to proactive, data-driven decisions.
Blueprint for a Modern Supply Chain Data Platform
Designing a modern supply chain data platform is about building an architecture that can ingest, process, and serve data at scale. The goal is a single source of truth that transforms chaotic data from your ERP, WMS, TMS, and IoT sensors into a reliable asset. This requires a layered approach to architecture. Your team’s ability to execute on this, including hands-on skills like building an ETL with Python, is critical.
Core Architectural Layers
Your platform’s architecture must handle the variety and velocity of supply chain data, selecting the right tool for each data source.
-
Ingestion: This layer acquires the data. For structured data from SaaS platforms and databases, automated tools like Fivetran provide efficiency. For high-volume, real-time streams from IoT devices or logistics feeds, a streaming platform like Apache Kafka or a cloud-native service like AWS Kinesis is necessary.
-
Storage and Transformation: Ingested data requires a flexible and powerful storage layer. A lakehouse architecture on a platform like Snowflake or Databricks is the current standard. It combines the raw storage capability of a data lake with the structured query performance of a data warehouse. Transformation is handled by tools like dbt (data build tool), which is essential for turning raw data into clean, analytics-ready models.
-
Serving: This is the final layer where clean data drives decisions. It powers dashboards in BI tools like Tableau, feeds predictive demand forecasting models, or pushes insights back into operational systems to trigger automated actions.
This modern, layered stack provides the foundation to move beyond reactive reporting and build a genuinely intelligent supply chain.
Architecture and Platform Evaluation: Snowflake vs. Databricks
The choice of a data platform is one of the most consequential decisions in your data strategy. It dictates your capabilities, cost structure, and the skills required of your team. For enterprise supply chains, the decision frequently narrows to two platforms: Snowflake and Databricks. The choice is not about which is “better,” but which is architecturally aligned with your primary business objectives.
Platform Comparison for Supply Chain Use Cases
Snowflake and Databricks were built with different philosophies. Snowflake excels at SQL-based analytics and multi-enterprise data sharing. Databricks, born from Apache Spark, unifies data engineering and large-scale machine learning.
The following table provides an evaluation framework tailored for supply chain data engineering leaders.
| Criterion | Snowflake | Databricks | Leadership Recommendation |
|---|---|---|---|
| Primary Use Case | BI & Analytics: SQL-native, optimized for structured/semi-structured data analysis, reporting, and dashboarding. | AI/ML & Data Science: A unified platform for the entire machine learning lifecycle, from data prep to model deployment. | Choose Snowflake for a BI-centric strategy focused on enterprise-wide visibility. Choose Databricks for an AI-first strategy centered on custom modeling. |
| Multi-Party Data Sharing | Best-in-Class: Native Secure Data Sharing allows seamless, secure data collaboration with suppliers, 3PLs, and retailers without data copies or ETL. | Good (Open Standard): Delta Sharing is an open protocol for sharing data, but lacks the integrated governance, marketplace, and ease-of-use of Snowflake’s feature. | For building a collaborative data ecosystem with external partners, Snowflake holds a significant architectural advantage. |
| Ease of Use & Adoption | Very High: Its fully managed service and familiar SQL interface reduce the barrier to entry for analysts and data-savvy business users. | Moderate to High: Requires specialized engineering skills (Spark, Python/Scala). The learning curve for non-engineers is steeper. | Snowflake enables faster time-to-value for teams with strong existing SQL skills. |
| Unstructured Data & ML | Improving: Snowpark and native unstructured data support are advancing but are not the platform’s core strength. Best for consuming ML outputs. | Excellent: The Lakehouse architecture is purpose-built to handle raw, unstructured data (images, text, sensor data) at scale for training ML models. | For advanced ML on diverse data types (e.g., computer vision for warehouse automation), Databricks is the superior choice. |
| Cost Model & Governance | Usage-Based: Separates storage and compute costs. This offers flexibility but requires diligent cost management to avoid unexpected bills. | Usage-Based (DBUs): Priced on Databricks Units (DBUs), which can be complex to forecast and optimize without deep expertise. | Both require strong governance. Snowflake’s model is generally easier for finance and operations teams to understand initially. |
The decision hinges on your strategic center of gravity. For organizations prioritizing a collaborative data hub for reporting and visibility across a partner network, Snowflake is the path of least resistance. Its data sharing capability is a game-changer for supply chain ecosystems.
Conversely, for organizations whose strategy relies on building proprietary, large-scale ML models using diverse data sets (e.g., predicting port congestion from satellite imagery), Databricks is the purpose-built platform. It provides a unified workspace for data engineers and data scientists to collaborate on complex AI applications.
To dive deeper into the technical nuances, our comprehensive feature-by-feature breakdown provides further clarity: learn more about Snowflake vs Databricks in our article.
Data Modeling, Governance, and Master Data Management (MDM)
A powerful data platform with poor data quality is an expensive failure. The value of supply chain data engineering is realized through intentional data modeling and disciplined governance. This ensures the insights generated by the platform are trustworthy.
Data Modeling and MDM
For supply chain analytics, dimensional modeling remains the most effective structure. It organizes data into “fact” tables (the numbers: order quantities, shipping costs) and “dimension” tables (the context: product, customer, location, time). This structure is highly optimized for fast querying by BI tools.
Master Data Management (MDM) is non-negotiable. Core business entities like Product, Customer, Supplier, and Location exist in dozens of disconnected systems. MDM’s objective is to create a single, authoritative “golden record” for each. Without MDM, you cannot answer a basic question like, “What was our total spend with Supplier X?” because “Supplier X, Inc.” in one system and “SuppX” in another are treated as different entities. MDM establishes a single source of truth, the prerequisite for an enterprise-wide view.
A Phased Framework for Data Governance
Implementing a massive, top-down governance plan is a recipe for failure. A pragmatic, phased approach delivers value quickly and builds organizational momentum.
- Phase 1: Assign Ownership & Establish Baselines. Assign clear owners for critical data domains (e.g.,
Product,Logistics). Implement automated data quality checks within your pipelines to measure completeness, accuracy, and timeliness. You cannot improve what you do not measure. - Phase 2: Implement Access Controls. Define and implement role-based access controls (RBAC) to ensure users only access data relevant to their function. This is critical for securing sensitive commercial data and ensuring regulatory compliance.
- Phase 3: Automate & Scale. Embed governance rules directly into your data pipelines using tools like dbt. This transitions governance from manual spot-checks to automated, preventative enforcement, ensuring all new data conforms to standards from the moment of ingestion.
High-Impact Analytics and ML Use Cases
The return on investment for a data platform comes from applying its power to solve high-value business problems. Data engineering enables a shift from descriptive analytics (what happened) to predictive and prescriptive analytics (what will happen and what we should do).
Predictive Demand Forecasting
Traditional forecasting based on historical sales is insufficient. A modern approach integrates external signals—weather data, economic indicators, social media trends, competitor promotions—to create a more accurate picture of future demand.
- Engineering Requirement: Building robust, reliable pipelines to ingest, clean, and integrate messy, diverse external data sources. The engineering team must also build a feature store to make these signals (e.g., a specific weather pattern) reusable across multiple ML models. Platforms like Databricks are a natural fit due to their strength in handling unstructured data and integrated ML tooling.
Real-Time ETA Prediction and Inventory Visibility
This use case provides live answers to two critical questions: “Where is my inventory?” and “When will it arrive?” It fuses real-time GPS data from Transportation Management Systems (TMS) and IoT sensors with external data on traffic, weather, and port congestion to calculate an accurate Estimated Time of Arrival (ETA).
- Engineering Requirement: The platform must support low-latency stream processing to analyze data as it arrives. This requires expertise in streaming technologies like Apache Kafka or Amazon Kinesis.
Network Optimization with a Digital Twin
A digital twin is a virtual simulation model of your entire supply chain network. It allows you to run “what-if” scenarios to stress-test your network’s resilience against disruptions—a supplier shutdown, a blocked shipping lane, a labor strike—before they occur.
- Engineering Requirement: The primary challenge is not the simulation itself, but the creation and maintenance of the complex, interconnected data model that mirrors physical reality. This is where Master Data Management (MDM) is absolutely critical. An inaccurate data foundation renders the digital twin useless.
Framework for Evaluating Data Engineering Consulting Partners
Selecting the right data engineering consulting firm is a critical decision that will accelerate or derail your roadmap. The evaluation must go beyond marketing claims and focus on verifiable evidence of capability and delivery.
Use this four-part checklist to assess potential partners.
1. Technical Depth and Platform Expertise
A qualified partner must have demonstrable experience across both streaming (e.g., Apache Kafka, Amazon Kinesis) and batch processing architectures. According to analysis by DataEngineeringCompanies.com of 86 data engineering firms, top-tier consultancies provide architectural blueprints from past projects on platforms like Snowflake or Databricks. Ask for them.
Vetting Question: “Show us an anonymized architecture diagram for a supply chain client where you integrated real-time logistics data with batch ERP data. Explain your choice of ingestion tools and transformation logic.”
2. Verifiable Supply Chain Domain Experience
Pure technical skill is insufficient. The partner must understand the nuances of supply chain data—the complexities of EDI feeds, TMS and WMS schemas, and metrics like inventory turns and landed cost.
Vetting Question: “Describe a project where you had to build a master data model for ‘Product’ using data from a client’s ERP, PIM, and WMS. What were the biggest data quality challenges and how did you resolve them?“
3. Delivery Discipline and Methodology
A vague project plan is a major red flag. The firm must operate with an agile methodology, clear sprint definitions, and transparent progress reporting.
Vetting Question: “Walk us through your process for managing a two-week sprint. What artifacts do you produce? How do you handle scope change or unforeseen technical debt discovered mid-sprint?“
4. Cost-Effectiveness and Rate Benchmarks
Focus on total cost of ownership and value, not the lowest hourly rate. An inexperienced, low-rate team often costs more in the long run due to rework and delays. A reputable partner provides transparent rate cards and realistic project cost forecasts tied to business value delivery.
Vetting Question: “Provide your rate card for the roles you propose for this project (e.g., Principal Data Engineer, Senior Consultant). What is your estimated timeline and cost for a 12-week MVP to establish a foundational data pipeline and two key BI dashboards?”
Actionable Next Steps for Engineering Leaders
Move from strategy to execution. Building a modern supply chain data platform is an iterative process, not a monolithic project.
1. Conduct a Rapid Data Maturity Assessment
Before charting a course, establish your baseline. This is not a formal audit but a rapid, honest assessment. Convene your team and answer these questions:
- Data Silos: What is our “integration” between the ERP, WMS, and TMS? Is it an API or a manual CSV export?
- Data Latency: Is the data used for critical operational decisions hours, days, or weeks old? What is the business impact of that delay?
- Source of Truth: If we ask three different teams for “on-time delivery performance,” do we get three different numbers from three different reports?
- Analytics Capability: Are our analytics limited to historical reporting, or do we have any predictive capabilities in production?
The answers will define your problem statement and form the basis of your business case.
2. Build the Business Case and Assemble the Team
Frame the initiative in terms of business outcomes, not technical tasks. Connect platform investment directly to P&L impact. For example: “A 10% reduction in inventory carrying costs through improved forecasting,” or “A 15% reduction in expedited freight spend through real-time shipment tracking.”
The most powerful question to answer for the C-suite is: “What is the cost of doing nothing?” Quantify the financial impact of stockouts, excess safety stock, and manual reporting that your current state is already costing the business.
Simultaneously, prepare your organization for the required talent. Equip hiring managers with crucial data engineer interview questions that specifically test for the skills needed to build these systems. When vetting partners, challenge them on their direct experience with messy supply chain data. Their answers will quickly distinguish true experts from generalists.
Finding a partner with verified expertise is the critical next step. DataEngineeringCompanies.com provides transparent, data-driven rankings and reviews of top firms, including validated case studies and cost benchmarks, to help you select a partner with confidence.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A Practical Guide to Hiring Data Governance Consultants
Hiring data governance consultants? This guide unpacks their roles, costs, and selection criteria to help you find the right partner for your modern data stack.

Data Contracts in Data Engineering: A Guide for Engineering Leaders
Explore data contracts in data engineering to enforce agreements, prevent pipeline failures, and boost data reliability across Snowflake and Databricks.

A CTO's Guide to Ecommerce Data Engineering
Build a high-performance ecommerce data engineering architecture. Compare platforms, integration patterns, and vendor selection criteria for maximum ROI.