Supervised vs Unsupervised Learning for Data Engineering

Your leadership team probably isn’t arguing about algorithms. You’re arguing about what kind of data platform investment will pay off first.
One camp wants a high-precision fraud model, churn model, or forecast. The other wants to mine the lakehouse for patterns nobody has labeled yet. Both sound reasonable. Only one fits your current pipelines, governance maturity, and staffing reality.
That’s why supervised vs unsupervised learning is a data engineering decision first. The winning approach depends on whether your stack can support labeled training data, repeatable feature pipelines, and model monitoring, or whether you need fast discovery on raw data with less operational overhead. If your team is actively evaluating platforms or partners, start with the best AI data engineering solutions and judge them on implementation depth, not slideware.
The Strategic Choice Beyond the Algorithm

Your CFO wants a fraud model in production before the next planning cycle. Your data team says the customer data is incomplete, labels are inconsistent, and feature logic lives in five systems. That is the fundamental supervised versus unsupervised decision.
Choose based on operating model, not algorithm taxonomy.
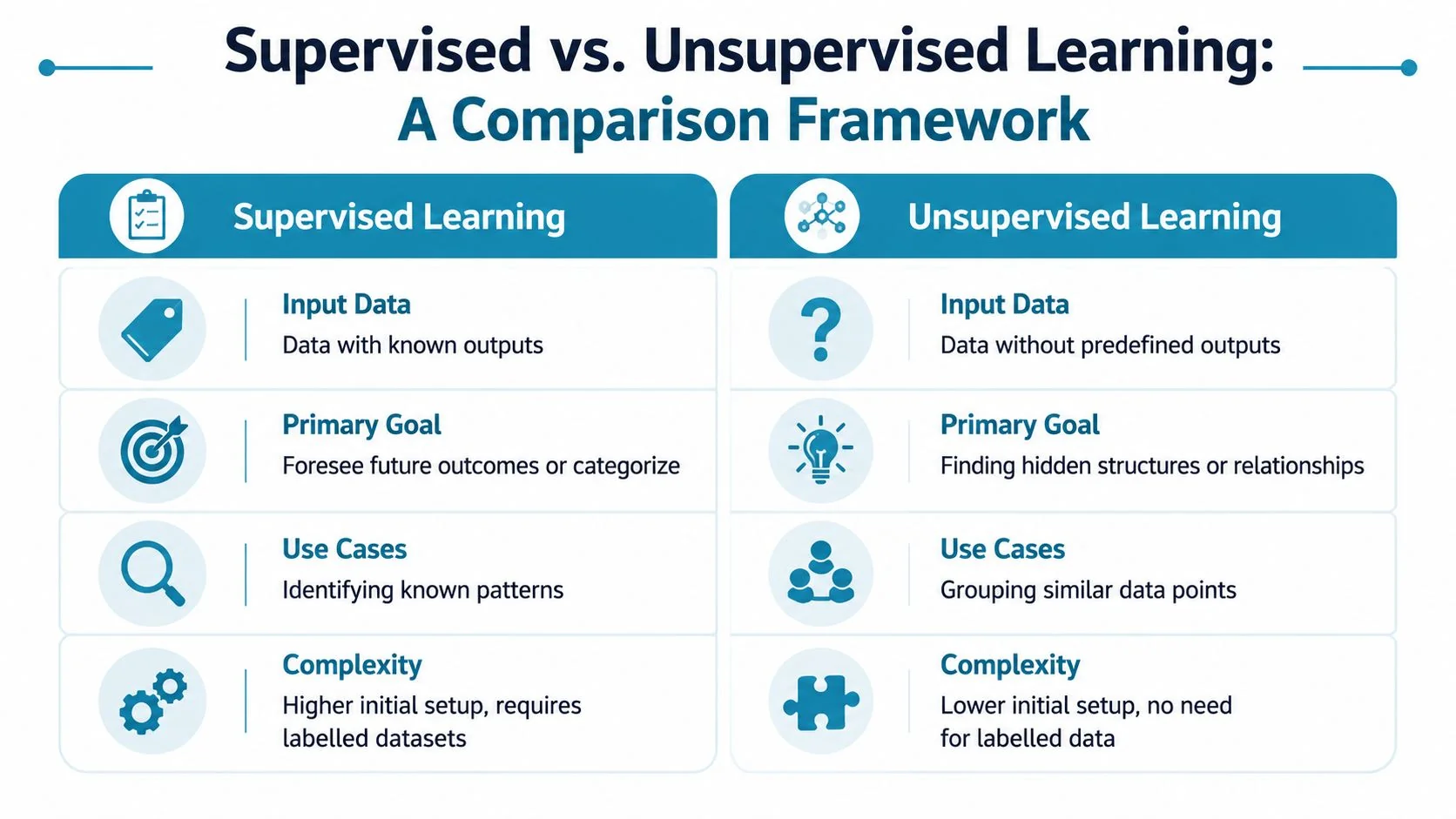
Supervised learning fits a business with a defined target, accountable owners, and the willingness to pay for labeled data, feature pipelines, monitoring, and retraining. TDWI notes that supervised learning trains on input-output pairs with known answers, the pattern that shaped classic benchmark-driven ML adoption, including MNIST in the late 1990s, according to TDWI’s overview of supervised and unsupervised learning. If you need a forecast, risk score, or classification tied to a KPI, supervised learning is usually the right funding decision.
Unsupervised learning fits a business that has plenty of raw data but no reliable labels, no agreed target variable, or no patience for a months-long labeling program. It is a discovery tool first. You use it to segment customers, surface anomalies, and expose structure in data your teams do not yet understand well enough to score.
The budget consequence is straightforward. Supervised learning pushes cost into data contracts, labeling workflows, feature consistency, and production monitoring. Unsupervised learning pushes cost into data quality, analyst review, interpretation, and repeated experimentation. One buys tighter business accountability. The other buys faster pattern discovery with weaker direct attribution.
That difference should drive platform choice. Snowflake-centered teams with mature warehouse governance often move faster on supervised use cases when labels already exist in operational systems. Databricks-centered teams often move faster on unsupervised work where wide data access, notebook-based exploration, and iterative feature discovery matter more than strict reporting alignment on day one.
Partner selection matters just as much. If your team is actively evaluating platforms or partners, start with the best AI data engineering solutions and judge them on implementation depth, not sales polish. Ask whether the firm has built label pipelines, feature stores, orchestration layers, and model monitoring in production. For teams that need external delivery support, Bridge Global’s AI development expertise is relevant only if they can show platform-specific execution on your stack, not generic ML capability.
Fund supervised learning when the business needs a measurable decision system. Fund unsupervised learning when the business still needs to define the problem.
A Framework for Comparing Learning Models
A CTO choosing between supervised and unsupervised learning is not choosing a model family first. The actual choice is where to spend engineering effort, how much pipeline discipline the team can sustain, and which platform will carry the operational load without inflating spend.
| Dimension | Supervised learning | Unsupervised learning |
|---|---|---|
| Primary goal | Predict a business outcome you already track | Surface patterns the business has not formalized yet |
| Data requirement | Stable labels tied to trusted entities and timestamps | Broad, clean, well-modeled data with enough context for interpretation |
| Typical methods | Classification, regression, ranking | Clustering, anomaly detection, dimensionality reduction |
| Evaluation style | Ground-truth testing against known results | Proxy metrics plus analyst review and business validation |
| Best enterprise fit | Claims triage, churn scoring, demand forecasting, credit risk | Customer segmentation, entity grouping, fraud exploration, operational anomaly scans |
| Data engineering burden | High, because labels, features, lineage, and retraining schedules must stay in sync | High in a different way, because discovery outputs need review workflows, metadata, and governance before anyone can act on them |
The table matters because each row maps to an architecture decision.
For supervised learning, the hard part is not training code. It is preserving label integrity across ingestion, entity resolution, transformation, feature generation, and retraining. If your CRM IDs drift, event timestamps arrive late, or dbt logic changes without version control, model performance drops and nobody trusts the output. That is why supervised programs belong in environments with strong warehouse governance, reproducible transformations, and explicit ownership for data contracts.
Unsupervised learning shifts the burden. You can start faster because you do not need a labeling program, but you will spend more time on data profiling, feature exploration, and review loops with domain experts. Clusters, embeddings, and anomaly scores do not create value on their own. They need business interpretation, thresholds, escalation paths, and a place in the operating model. Without that, the team produces interesting notebooks instead of a usable system.
Platform fit should follow that reality. Snowflake usually favors supervised programs when labeled records already sit in operational tables and finance wants a clear chain from source data to model output. Databricks often fits unsupervised work better when teams need iterative experimentation across large volumes of semi-structured or high-dimensional data. If you are weighing those tradeoffs, DataEngineeringCompanies.com’s analysis gives a practical comparison tied to implementation choices, not vendor slogans.
Use a simple funding test. Pay for supervised learning when the business owner can name the decision, the target variable, and the system that records outcomes. Pay for unsupervised learning when the data is rich, the problem definition is still forming, and the business is ready to fund analyst review after the model runs.
Vendor selection should be just as strict. Do not hire a partner that talks about algorithms before asking about source system quality, orchestration, feature lineage, and model ownership. Bridge Global’s AI development expertise is relevant only if the engagement includes pipeline design, platform-specific delivery, and production controls, not slideware about generic ML capability.
A good partner connects model choice to storage design, orchestration, governance, and cost control. Anything less creates technical debt disguised as innovation.
Platform Implementation on Snowflake and Databricks
You are about to fund one of two very different engineering programs.
In one, your team builds labeled training tables, versioned features, retraining schedules, and model monitoring tied to known outcomes. In the other, your team builds high-volume ingestion, flexible experimentation environments, analyst review loops, and downstream systems that can absorb segments, anomalies, or clusters that are not stable on day one. The algorithm matters less than the platform behavior it forces.
For supervised learning, Snowflake usually carries the operational load. It is the better home for governed training data, repeatable SQL transformations, and audit-friendly feature pipelines. Databricks enters the picture when training jobs outgrow warehouse-native patterns or when the team needs distributed feature computation, notebook-based experimentation, or tighter Spark workflows.
Supervised implementation pattern
A supervised stack should be boring in production. That is a strength.
Use Snowflake as the system of record for labeled data. Use dbt to build reproducible feature tables with clear lineage back to source systems. Use Airflow or your existing orchestrator to schedule refreshes, training runs, validation checks, and deployment tasks. Add Databricks only when model training or feature generation needs compute elasticity that would be expensive or awkward to run inside the warehouse.
That architecture keeps ownership clear. Data engineers own ingestion, transformation, and feature quality. ML engineers own training code, evaluation logic, and deployment controls. Finance gets a cleaner cost model because storage, transformation, and compute are easier to attribute to a defined business use case.
Unsupervised implementation pattern
Unsupervised programs shift more complexity upstream.
Teams new to MLOps often underestimate this. The absence of labels does not remove engineering work. It moves the burden into ingestion quality, event standardization, feature exploration, embedding pipelines, experiment tracking, and human review after the model produces clusters or anomaly scores.
Databricks is usually the stronger center of gravity here because unsupervised work starts closer to raw data. You can process semi-structured logs, clickstreams, documents, and high-dimensional behavioral data without forcing everything into warehouse-shaped tables too early. Snowflake still matters, but in a different role. It is where you publish approved outputs, control access, and serve segments into BI, activation, or reverse ETL workflows.
Where each platform earns budget
| Platform pattern | Better fit for supervised learning | Better fit for unsupervised learning |
|---|---|---|
| Snowflake-centric | Best for labeled datasets, feature lineage, SQL-first transformations, and governed retraining workflows | Best for publishing scored outputs, approved segments, and analyst-reviewed results into business systems |
| Databricks-centric | Best when training volume, feature computation, or custom ML workflows exceed warehouse-native limits | Best for experimentation on raw data, clustering, anomaly detection, embeddings, and iterative analyst collaboration |
The practical question is cost of change. Supervised systems cost more to maintain when labels drift, business definitions change, or source systems break lineage. Unsupervised systems cost more to interpret and operationalize because the pipeline does not end when the model runs. It ends when a business team can trust and use the output.
If your team is still debating platform direction, review DataEngineeringCompanies.com’s analysis before you approve architecture. Use it to test whether your planned stack matches the data shape, governance model, and operating pattern you require.
For a broader tooling view tied to infrastructure decisions, this guide to AI solutions for enterprise data is useful because it treats ML as a platform investment, not a notebook exercise.
Comparing Model ROI and Technical Debt
A CTO approves a six-figure ML budget, the model ships, and finance still cannot see the payoff. That failure usually starts upstream. The team picked a learning approach before it priced the pipeline, assigned ownership, and defined how the output would change a business process.
Supervised and unsupervised learning create different ROI profiles because they create different engineering obligations. Treat them as operating models, not just model types.

Where supervised earns budget faster
Supervised learning usually produces a shorter path from model output to business action. That matters because ROI survives budget review only when leaders can trace it to a queue reduction, approval decision, forecast improvement, or retention intervention.
The engineering reason is straightforward. Supervised systems give you a cleaner evaluation loop because you can compare predictions to known outcomes. That makes it easier to justify spend on feature stores, retraining jobs, lineage tracking, and model monitoring in Snowflake or Databricks. You can build a controlled pipeline, assign SLOs, and prove whether the system is improving.
The tradeoff is label infrastructure. You need collection rules, QA workflows, versioned training sets, and someone accountable for changes in business definitions. If your labels come from expert review, costs can rise quickly. Exact rates vary widely by domain and skill level, so budget for annotation as an ongoing operating expense rather than assuming a one-time setup cost.
Where unsupervised creates value, and where it creates drag
Unsupervised learning makes sense when the business needs discovery first and automation second. It is useful for anomaly detection, segmentation, and pattern finding across data that has no stable target column.
That does not make it cheaper. It shifts the cost.
The model may run quickly, but the hard part starts after scoring. Someone has to validate whether a cluster matters, define thresholds for action, publish results into downstream systems, and keep those definitions stable enough for reporting and audit. Without that work, the output stays in a notebook or dashboard and never reaches operations.
That creates three predictable forms of technical debt:
- Interpretation debt. Analysts and business owners disagree on what a segment or anomaly means.
- Activation debt. Discovered patterns never become alerts, case queues, pricing rules, or product features.
- Governance debt. Segment logic changes over time without versioning, lineage, or review.
Fund an unsupervised project only if an operating team can name the action tied to each class of output and accept responsibility for reviewing it.
My recommendation on ROI
Choose supervised learning if you need a system that finance can audit and operations can use immediately. It is the better investment when the decision is known, the target is explicit, and your platform team can support label creation and retraining discipline.
Choose unsupervised learning if you are trying to find structure in messy data and you already have a plan to convert findings into workflows. If that activation layer is missing, the project will accumulate technical debt faster than it creates value.
For enterprise teams deciding where to place budget, the test is simple. Fund supervised learning when you want predictable operational ROI. Fund unsupervised learning when you are prepared to pay for interpretation, governance, and productization after the model runs.
Vendor and Staffing Evaluation Checklist
Most consulting firms can talk about models. Far fewer can build the pipelines that keep them alive.
This serves as the filter for supervised vs unsupervised learning. You’re not buying notebooks. You’re buying data contracts, orchestration, access control, monitoring, and handoffs between engineering and business teams.
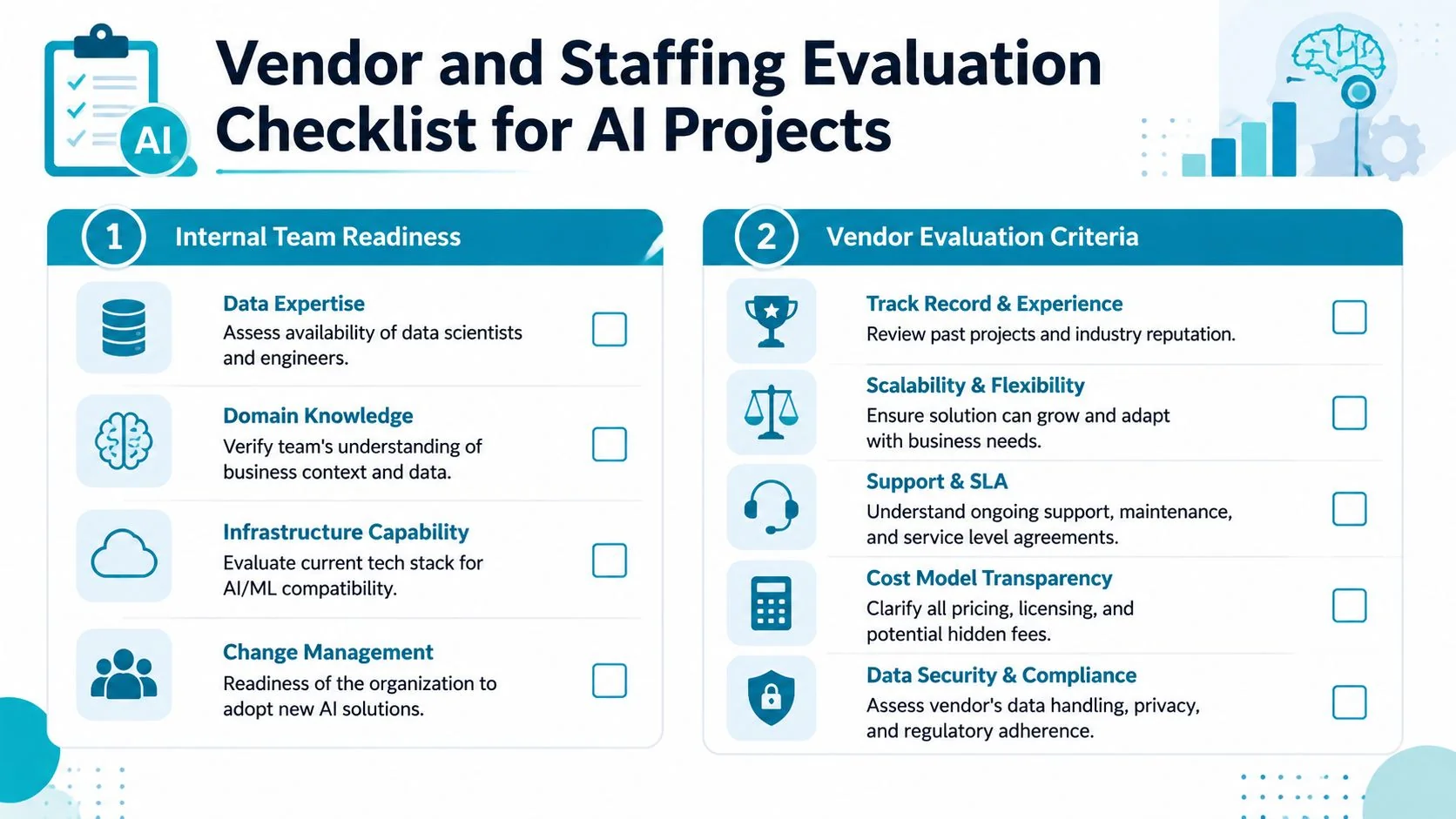
Internal team readiness
Use this checklist before you even issue an RFP.
- Ownership clarity. Name one executive owner for the business outcome and one engineering owner for the pipeline.
- Platform fit. Confirm whether your current Snowflake, Databricks, dbt, and Airflow stack already supports the required workflow.
- Data governance maturity. Check whether your team can trace training data lineage, access rules, and transformation logic.
- Operational discipline. Decide who handles retraining, drift review, segmentation refreshes, and exception handling after go-live.
Questions to ask supervised-learning vendors
- How do you build auditable label pipelines?
- How do you version features and training sets across dbt, warehouse tables, and model jobs?
- How do you detect label drift or schema breakage before retraining starts?
- What handoff artifacts do you leave behind for internal platform teams?
A weak answer focuses on model selection. A strong answer describes table design, orchestration logic, validation checks, and rollback procedures.
Questions to ask unsupervised-learning vendors
- How do you prove a discovered segment or anomaly pattern is operationally useful?
- How do you productionize outputs into BI, customer systems, or alerting pipelines?
- How do you govern changes in cluster definitions over time?
- What process do you use for human validation and business sign-off?
A vendor that can’t explain activation shouldn’t lead an unsupervised engagement.
What to avoid
| Red flag | Why it matters |
|---|---|
| “We’ll figure out the labels later” | Supervised projects fail when labeling is treated as an afterthought |
| “The platform doesn’t matter” | Architecture choices drive cost, latency, and maintainability |
| “Our data scientists can manage the pipelines” | Production ML needs data engineering ownership, not notebook heroics |
| “We’ll start with exploration and define use cases later” | Unsupervised work drifts fast without a named business action |
Your Decision Flowchart and Next Steps
Start with one question: Is the business trying to predict a known outcome or discover structure in unlabeled data?
If the answer is prediction, check whether you already have labeled data. If yes, proceed with supervised learning. If no, decide whether your organization can create labels efficiently enough to justify the effort. If not, stop pretending this is a straightforward supervised project.
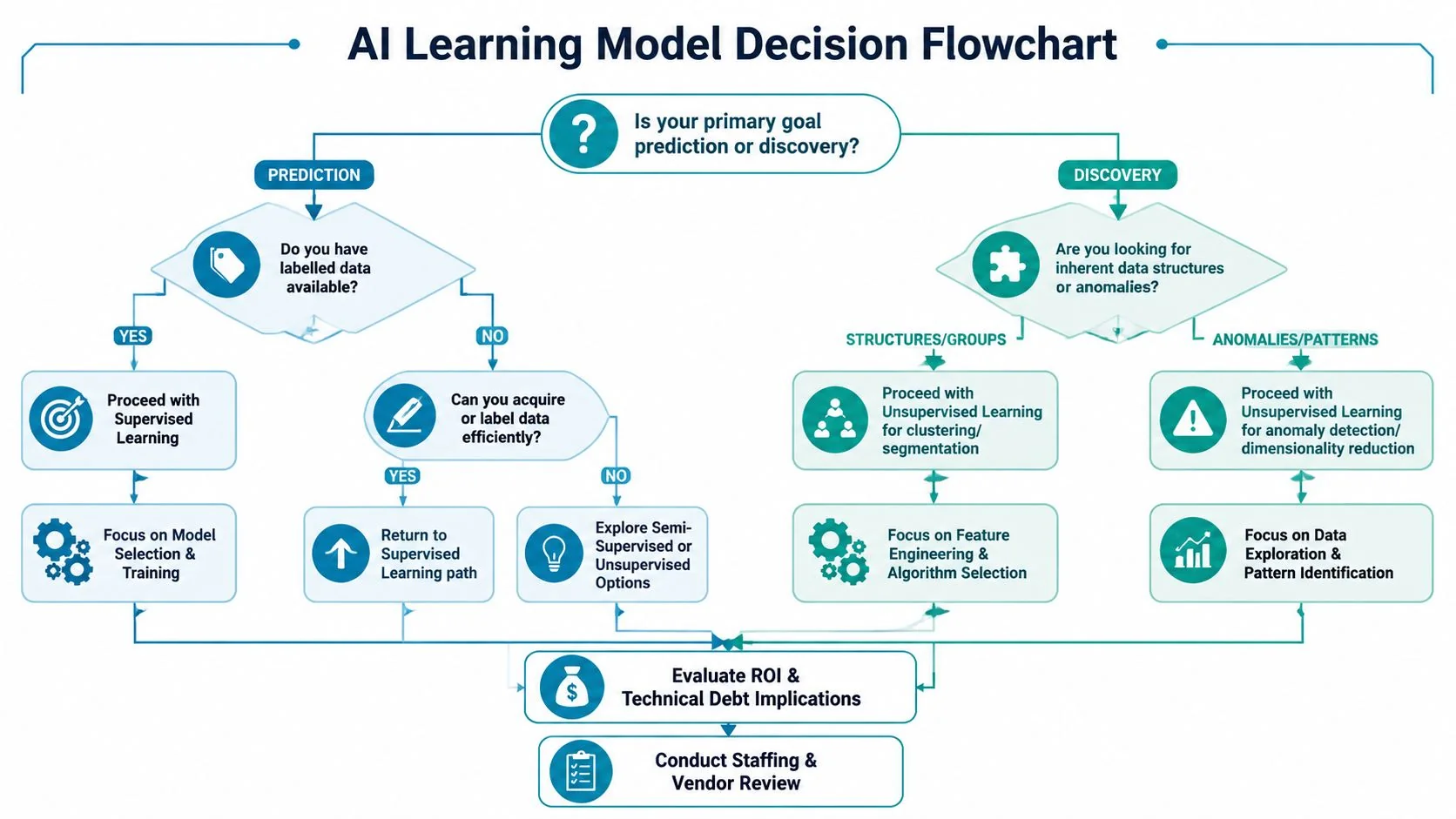
If the answer is discovery, unsupervised learning is the correct starting point. Use it for segmentation, anomaly detection, and structure discovery in large unlabeled datasets. Then force a second decision: what operational workflow will consume the output?
The third path most teams actually need
The binary framing breaks down in production. Major cloud providers position semi-supervised learning as the practical bridge when labeled data is scarce but predictive outputs are still required, as outlined by Google Cloud.
That matters because many enterprises sit in the middle. They have a small amount of trusted labeled data, a much larger body of unlabeled records, and pressure to deliver prediction quality without funding a full annotation factory.
Here’s a useful walkthrough before you build your business case:
Next steps for a CTO
-
Write a one-page decision memo
State the target outcome, data condition, platform assumption, and operational owner. -
Define a pilot with one narrow workflow
For supervised learning, pick a single prediction use case. For unsupervised learning, pick one discovery use case with a named downstream action. -
Scope the pipeline before the model
Lock down source systems, data contracts, transformations, orchestration, and governance controls. -
Run partner evaluation against engineering criteria
Ask for implementation plans in Snowflake, Databricks, dbt, and Airflow. Ignore vendors who stay abstract. -
Choose the model strategy that fits your data maturity
Don’t fund supervised learning without labels. Don’t fund unsupervised learning without an activation plan. Use semi-supervised learning when reality sits between those two poles.
If you’re shortlisting partners for ML-enabled data platform work, use DataEngineeringCompanies.com to compare consultancies by platform expertise, delivery model, industry fit, and evaluation criteria before you commit to a pilot.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Featured Data Engineering Partners
Vetted firms whose specialty matches this article.
Related Analysis

Top Data Engineering Managed Services for 2026
Compare leading data engineering managed services. Find models, pricing, & vendors. Use our RFP checklist to select your ideal Snowflake or Databricks partner.

The 10-Point Data Engineering Due Diligence Checklist for 2026
Don't hire a consultant without this data engineering due diligence checklist. Vet firms on architecture, cost, governance, and team skills before you sign.

Actionable Playbook for Snowflake to Databricks Migration
Actionable playbook for engineering leaders: Snowflake to Databricks migration. Strategies for cost, execution & AI/ML value.