Actionable Playbook for Snowflake to Databricks Migration

A Snowflake to Databricks migration is a strategic decision to move from a cloud data warehouse to a unified platform for data analytics and AI. This shift is driven by the need to consolidate tools, reduce total cost of ownership (TCO), and unlock the advanced AI/ML capabilities inherent in the Databricks Lakehouse architecture. This is not a technology swap; it is a platform re-architecture.
Why Engineering Leaders Are Making the Switch
The decision to migrate from Snowflake to Databricks originates from a shift in how an organization intends to use its data—moving from siloed business intelligence toward an integrated ecosystem for data engineering, data science, and machine learning. This pivot occurs when the data warehouse becomes a bottleneck for modern data science workloads.
The primary business drivers for this migration are:
- Lower Total Cost of Ownership (TCO): Data stacks comprising Snowflake for warehousing, another tool for ETL, and a third for ML create redundant licensing and infrastructure fees. Consolidating on Databricks eliminates these costs.
- Unified Governance: Managing security, access, and compliance across multiple systems is operationally complex. Databricks Unity Catalog provides a single governance model for all data assets—from tables to ML models—simplifying administration.
- Integrated AI/ML Capabilities: Databricks, built on Apache Spark, is designed for large-scale data processing and machine learning. Teams no longer need to extract large datasets from the warehouse to train models, which accelerates development cycles.
This is not a niche trend. The global data lakehouse market is projected to grow from $14.2 billion in 2025 to $105.9 billion by 2034, a 25% compound annual growth rate (CAGR). This growth highlights the opportunity cost of remaining on a platform not optimized for integrated data and AI workloads.
The core difference is architectural philosophy. Snowflake perfected the cloud data warehouse. Databricks built a unified platform for data and AI. For a deeper dive into their architectural differences, read our complete Snowflake vs. Databricks comparison.
Building Your Pre-Migration Cost and Readiness Model
A successful Snowflake to Databricks migration is determined before a single line of code is translated. The critical first step is building a detailed model that assesses both organizational readiness and the true financial impact. Without this analysis, you are flying blind.

This process starts with a forensic audit of your current Snowflake environment. Inventory every asset: SQL queries, stored procedures, Snowpark jobs, UDFs, tasks, and data streams. This inventory forms the foundation of your migration plan.
Quantifying the Migration Effort
After inventorying assets, score their complexity. A simple SELECT statement is straightforward; a 2,000-line stored procedure with Snowflake-specific functions is not. Use a scoring system to quantify the work involved.
- Low Complexity: Standard ANSI SQL queries and basic views. These often migrate with near-zero-touch automation.
- Medium Complexity: Queries using proprietary Snowflake SQL functions, simple Snowpark dataframes, or Snowpipe ingestion. These require translation, but the patterns are well-understood and often automatable.
- High Complexity: Nested stored procedures, complex UDFs, streams, and tasks. This procedural logic cannot be directly translated; it must be manually re-architected into a Databricks notebook or a Delta Live Tables pipeline.
This scoring provides a quantifiable measure of technical debt, turning a vague “it’s complex” into an actionable plan for prioritization and realistic timeline setting.
Developing a Realistic TCO Model
Your Total Cost of Ownership (TCO) model must account for the fundamental differences in the economic models of Snowflake and Databricks. A simple license-to-license comparison is insufficient.
To perform a true apples-to-apples comparison, analyze how each platform structures key cost drivers. The following table provides a framework.
Snowflake vs. Databricks Cost Factor Comparison
| Cost Factor | Snowflake Approach | Databricks Approach | Migration Implication |
|---|---|---|---|
| Compute Model | Bundled compute (Virtual Warehouses) with per-second billing. Sized T-shirt models (XS, S, M, etc.). | Unbundled compute (Databricks Units or DBUs) billed per-second. Granular control over VM types. | Databricks is often cheaper for consistent workloads if tuned properly. Snowflake is more cost-effective for sporadic, ad-hoc queries due to its auto-suspend feature. |
| Storage | Storage costs are separate from compute, billed at pass-through rates from the cloud provider plus a markup. | Uses your own cloud storage account (BYOS). You pay the cloud provider directly for storage. | Databricks offers direct control and potential savings on storage but requires you to manage the cloud storage lifecycle. |
| Engineering Overhead | Designed for ease of use, often requiring less specialized platform engineering. | Requires more skilled engineering (Spark, Scala, Python) to optimize infrastructure for price/performance. | Your team’s existing skill set is a major cost factor. A Spark talent gap requires budgeting for training or consulting. |
| Workload Specialization | A single architecture for BI, analytics, and some data science. | Specialized runtimes and compute options for SQL, ML, and streaming, allowing for tailored optimization. | You must map Snowflake workloads to the correct Databricks cluster type to achieve cost-efficiency; a one-size-fits-all approach is expensive. |
A common and costly mistake is underestimating the cost of running parallel environments. During a phased migration, you will pay for both Snowflake and Databricks. This dual-cost period can last for months, and your budget must have a line item for it. Learn more about how these economic models differ at Invene.com.
Factor in these real-world costs:
- Engineering Effort: Use complexity scores to estimate person-hours for code conversion, logic re-platforming, and testing.
- Talent & Training: Budget for hiring, training, or consultants if you lack Spark, Scala, or advanced Python skills.
- Migration Tooling: Include costs for any third-party automation tools for code translation or validation.
- Egress Fees: Snowflake charges data egress fees for the initial export of data to your cloud storage. This is a significant one-time cost.
The Technical Playbook for Translating Workloads
A Snowflake to Databricks migration is a translation project, not a “lift-and-shift.” The objective is to map Snowflake’s proprietary, SQL-first environment to the open standards of the Databricks Lakehouse Platform.
Mapping Data Structures and Schema
The first technical task is translating Snowflake DDL (Data Definition Language) to a format compatible with Delta Lake. This requires understanding the different data storage and management philosophies.
- Tables and Views: Standard ANSI SQL tables and views will migrate with minimal changes. Automated tools can handle this, but manual inspection of views using Snowflake-specific functions is required.
- VARIANT Type: Snowflake’s proprietary
VARIANTtype for semi-structured data must be mapped to aJSONstring or nativestructsandarraysin Delta tables. Queries must be rewritten to use Databricks’ JSON parsing functions (from_json,get_json_object). - Time Travel: Both platforms offer historical data querying. Snowflake’s Time Travel is equivalent to Delta Lake’s transaction log, which enables querying past table states via
VERSION AS OForTIMESTAMP AS OF. Scripts must be adapted to the new syntax.
Expert Tip: The
VARIANT-to-JSON conversion strategy is a common failure point. A migration plan must account for how this data will be stored, ingested, and queried in the new environment.
Converting Procedural Logic and Ingestion
Procedural code—business logic in stored procedures and UDFs—demands manual re-architecture.
Snowflake’s JavaScript Stored Procedures have no direct equivalent. This logic must be refactored into a Databricks Notebook using Python or Scala. While more work upfront, this yields improved testability, version control, and integration with the PySpark ecosystem.
Simple SQL UDFs can be converted to Databricks SQL UDFs. Complex UDFs are best rebuilt as part of a notebook or a Delta Live Tables (DLT) pipeline for better long-term manageability.
The table below maps common Snowflake features to their Databricks equivalents.
Snowflake to Databricks Feature Mapping Framework
| Snowflake Feature | Databricks Equivalent | Key Migration Consideration |
|---|---|---|
| Snowpipe | Auto Loader | Both offer automated file ingestion. Auto Loader provides superior schema inference and evolution, reducing manual DDL adjustments. |
| Tasks & Streams | Delta Live Tables (DLT) or Scheduled Jobs | Simple Snowflake Tasks can be replaced by Databricks Jobs. For CDC patterns using Streams and Tasks, re-architect them into a DLT pipeline for a more robust, declarative framework. |
| Stored Procedures | Notebooks (Python/Scala) or SQL UDFs | Simple, self-contained procedures may map to SQL UDFs. Logic with loops, error handling, or complex branching must be refactored into a notebook. This is a manual but necessary upgrade. |
The security model must be translated carefully. Snowflake’s Role-Based Access Control (RBAC) and data masking policies have a strong equivalent in Databricks Unity Catalog. Unity Catalog provides a unified governance layer for implementing fine-grained row- and column-level security across all data and AI assets.
Structuring the Migration: Phased Execution and Continuous Testing
A “big bang” migration from Snowflake to Databricks is a recipe for failure. The proven approach is a phased, iterative execution, broken down by business domain or data product. This de-risks the project and builds stakeholder momentum.
The process involves the parallel translation of three components: data schemas, business logic (SQL), and ingestion pipelines.
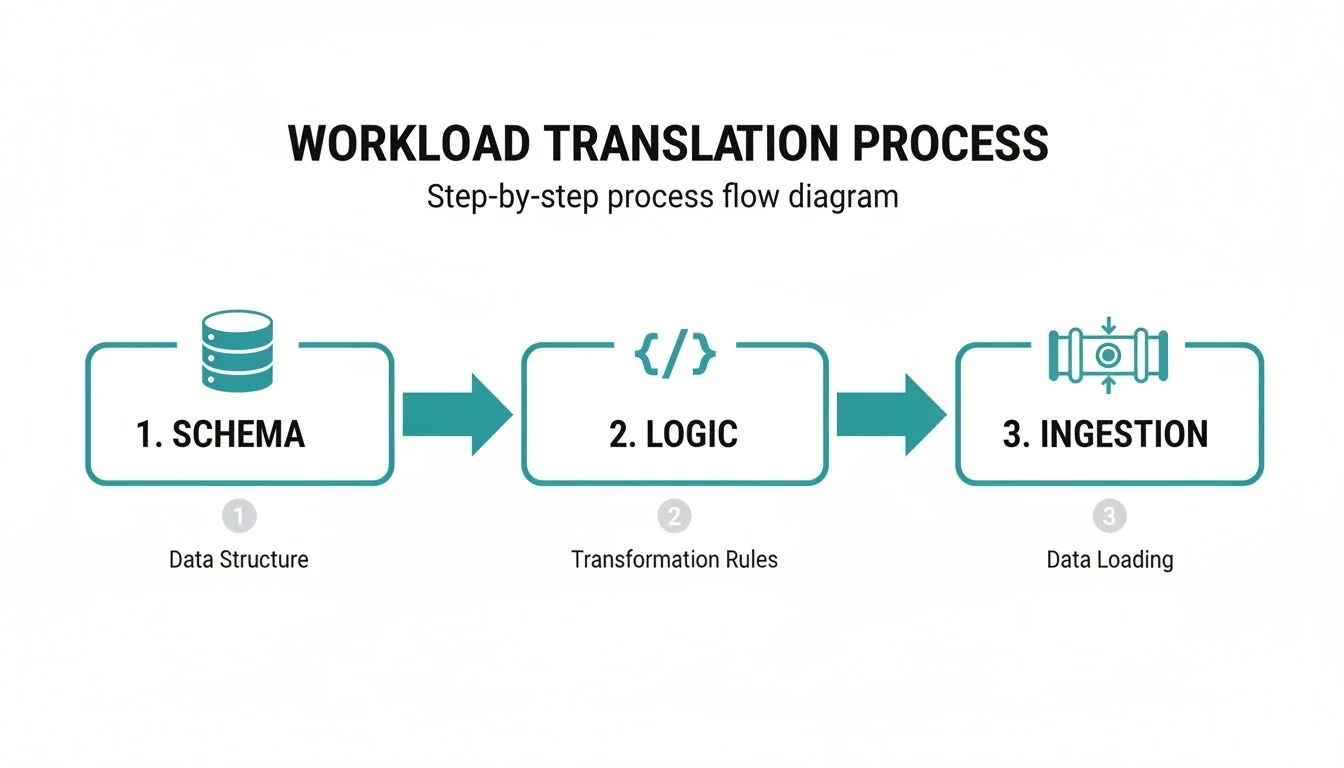
As the diagram illustrates, schema migration, logic conversion, and ingestion re-architecture are multi-threaded, not linear.
Selecting the Right Translation Tools
Automation can significantly accelerate the migration. There are three primary options:
- Databricks Lakebridge: Databricks’ free, open tool designed to automate profiling, SQL conversion, and validation. Databricks claims it can automate up to 80% of migration tasks. It is an effective starting point.
- Third-Party Tools: Specialized vendors offer code translation tools that excel with complex, non-standard SQL or proprietary Snowflake features.
- Custom Scripts: For teams with deep engineering expertise, building custom conversion scripts offers total control but requires a significant development investment. This is only viable in unique situations.
For most projects, a hybrid approach is best: use a tool like Databricks Lakebridge for bulk conversion and have experts manually refactor complex or critical components. Automate what you can; re-architect where it counts. Our guide on data migration best practices provides broader strategies.
Validation Is Not an Afterthought—It Is Everything
Testing must be a continuous, multi-layered process.
A migration without rigorous, parallel validation is just a data copy-and-paste exercise. You must prove functional equivalence, performance improvements, and financial accuracy before decommissioning Snowflake.
- Data Integrity Validation: Perform cell-by-cell comparisons on data subsets to ensure perfect data transfer from source to target.
- Performance Benchmarking: Run critical queries in both Snowflake and Databricks to prove that Databricks meets or exceeds performance SLAs.
- Financial Validation: Monitor Databricks Unit (DBU) consumption against your TCO model to confirm projected cost savings.
This three-pronged validation approach is your defense against post-cutover surprises.
How to Select the Right Migration Partner
Selecting the right partner is a critical decision. This is not a job for a generalist IT firm. You need a team with deep, hands-on experience in both ecosystems. According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, only 35% had certified experts across both Snowflake and Databricks along with a repeatable migration process.
Core Evaluation Criteria Checklist
Be wary of partners skewed toward one platform. A Snowflake-heavy team may try to force a Snowflake architecture onto Databricks, creating a more expensive, less efficient system.
Use this checklist when vetting partners:
- Dual-Platform Experience: Do they have certified experts and specific project references for both Snowflake and Databricks? Demand case studies detailing a warehouse-to-lakehouse migration.
- Unity Catalog Mastery: Can they explain how they will map your Snowflake security and RBAC into a unified governance model on Unity Catalog? A fumbled answer is a major red flag.
- Automation Strategy: Which tools do they use for code migration? Do they have a realistic commitment to an automation percentage and a proven method for combining automation with manual refactoring?
Run a Structured Selection Process
Conduct a formal Request for Proposal (RFP) process. An RFP forces potential partners to provide detailed proof of their skills and transparent pricing, enabling a true apples-to-apples comparison.
A structured framework ensures you find a partner who will achieve the strategic goals of your migration, not just tick a technical box.
Answering Your Snowflake to Databricks Migration Questions
Here are direct answers to the most common questions from engineering leaders.
How Long Does a Typical Migration Take?
For a mid-sized company, a full migration takes 9 to 18 months. The timeline depends on data volume, the complexity of custom logic, and the number of connected reports and dashboards.
Start with a pilot project on a single business unit or data product. This can be completed in 8 to 12 weeks and provides a quick win. Timelines are most often derailed by a shallow pre-migration assessment and underestimating the time required for testing and validation.
What Is the Biggest Technical Hurdle?
The biggest hurdle is untangling procedural logic from complex stored procedures and UDFs. While tools can automate standard SQL, this embedded business logic requires manual analysis, re-architecture, and rebuilding, typically in Python notebooks. This manual effort is a common source of budget overruns. Another challenge is transitioning from Snowflake’s proprietary data sharing to the open Delta Sharing standard, which requires careful planning with external partners.
Can We Run Snowflake and Databricks in Parallel?
Yes, and you must. Running both platforms side-by-side during a phased migration is the only safe approach. This dual-platform strategy acts as a safety net, ensuring business continuity.
Set up a data sync from Snowflake to your cloud storage (S3, ADLS Gen2). Databricks can then ingest this data using tools like Auto Loader. This keeps the new Databricks environment fresh for side-by-side validation of migrated pipelines.
A dual-platform strategy is non-negotiable for a smooth transition. It allows for meticulous testing and a controlled cutover, but remember to explicitly budget for these overlapping costs, as you will be paying for both services during this period.
The objective of parallel operation is to migrate and validate workloads one by one, ensuring each performs correctly before decommissioning the original. This systematic cutover prevents post-migration failures.
Navigating a Snowflake to Databricks migration requires specialized expertise. The next step is to identify a qualified partner. DataEngineeringCompanies.com provides data-backed firm profiles and a free RFP checklist to help you select a vetted firm with a proven migration methodology. Find your partner at https://dataengineeringcompanies.com.
Part of our guide
Data Migration →
Part of our guide
Snowflake Consulting →
Part of our guide
Databricks Consulting →
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Top Data Migration Partners
Vetted firms whose specialty matches this article.
More in Data Migration

How to Hire the Right Cloud data warehouse consultant
A practical guide to hiring a cloud data warehouse consultant. Learn how to define your needs, evaluate candidates, and avoid common hiring mistakes.

What is a semantic layer? A Practical Guide for AI and BI Data Unification
Discover what is a semantic layer and how it unifies data for AI and BI, including Snowflake and Databricks.

Snowflake vs Databricks: An Objective Data Platform Comparison
Explore a definitive Snowflake vs Databricks comparison. This guide analyzes architecture, performance, AI/ML use cases, and TCO to inform your data strategy.