Redshift vs BigQuery: The 2026 Enterprise Decision Guide

You likely have two proposals in front of you right now. One puts your warehouse in AWS with Redshift. The other pushes a GCP-native BigQuery stack. Both look credible. Both promise scale, lower ops burden, and better analytics.
Treat this as an ecosystem decision, not a warehouse feature bake-off. The platform you choose will shape who you hire, which consulting firms can deliver well, how painful your migrations become, and whether finance trusts your cost model.
Most redshift vs bigquery comparisons stay shallow. They argue about speed in isolation. That is the wrong frame. A warehouse is not an isolated tool. It sits inside pipelines, governance, IAM, ML workflows, procurement, and partner delivery.
The Platform Choice That Defines Your Data Strategy
If your team thinks this is just Redshift versus BigQuery, step back. You are really choosing between control inside AWS and elasticity inside GCP. That choice will show up in architecture reviews, FinOps meetings, and every consulting statement of work you sign for years.

The common assumption is simple: serverless always wins because it removes admin work. That assumption breaks down fast in enterprise environments with stable BI, large joins, governed semantic layers, and hard requirements for repeatable dashboard performance. In those conditions, tuned infrastructure beats abstracted infrastructure more often than teams want to admit.
Use this quick filter first.
| Decision area | Redshift | BigQuery |
|---|---|---|
| Operating model | Provisioned cluster | Serverless |
| Best fit | Stable BI and predictable reporting | Ad-hoc analysis and bursty workloads |
| Admin burden | Higher | Lower |
| Cost model | Provisioned capacity | Pay per query plus storage |
| Real-time ingestion | Uses Amazon Kinesis Firehose | Native streaming |
| Hiring profile | AWS data platform and performance tuning | GCP analytics and cost governance |
The wrong decision creates a slow, expensive consulting program. The right one sharpens delivery. It aligns your warehouse with your cloud posture, operating model, and procurement realities.
Recommendation: If your core business depends on repeatable reporting for executives, finance, or operations, start by trying to disprove Redshift. If your business depends on wide, exploratory analysis with variable demand, start by trying to disprove BigQuery.
Architectural DNA and Deployment Models
Redshift and BigQuery behave differently because they are built on different assumptions. One assumes you want to provision and tune. The other assumes you want Google to abstract the machinery.
Redshift rewards teams that want control
Redshift is a cluster-based MPP system. That matters because performance is not just a product feature. It is a result of design choices your team or consultancy makes around distribution, sort keys, workload patterns, and maintenance.
That provides control. It also gives you responsibility.
Redshift works well when your team has clear workload patterns and is willing to tune the platform for them. Dashboards, recurring BI jobs, and large relational joins are the obvious examples. If your data engineering function already lives in AWS, Redshift fits naturally with the rest of the estate.
The trade-off is operational load. You do not get a zero-admin experience. The platform asks for competence in tuning and care around ongoing maintenance.
BigQuery removes infrastructure decisions
BigQuery is serverless. Storage and compute scale independently. Google assigns compute slots dynamically. That changes the staffing model as much as the technical model.
Teams can start fast. They can load data, query it, and avoid cluster planning. That is attractive in consulting-led modernization work because it reduces time spent on infrastructure setup and pushes effort into modeling, governance, and workload management.
BigQuery also fits variable demand better. It is designed for teams that do not want to pre-plan capacity for every spike.
A useful related comparison sits in this guide on BigQuery vs Snowflake, especially if your team is also evaluating a broader warehouse shortlist.
Ingestion and concurrency expose the key difference
Architecture stops being abstract here. According to Firebolt’s comparison of the two platforms, BigQuery supports native streaming and serverless autoscaling, while Redshift relies on Amazon Kinesis Firehose for streaming pipelines. The same comparison notes that Redshift caps at 50 concurrent queries and BigQuery defaults to 100 concurrent users, with BigQuery better suited to dynamic AI and ML pipelines and Redshift stronger in tuned dashboard environments with large joins (Firebolt comparison).
That maps directly to consulting scope:
- If you choose Redshift, your partner needs strong AWS delivery skills. Think Glue, IAM, VPC design, Kinesis Firehose integration, workload tuning, and operational runbooks.
- If you choose BigQuery, your partner needs strong GCP analytics skills. Think slot management, cost controls, streaming design, and governance for self-service usage.
- If you plan real-time analytics, BigQuery is cleaner out of the gate.
- If you plan controlled enterprise BI, Redshift gives you more knobs and more accountability.
Architect’s view: Control is only an advantage if your team or partner knows how to use it. Otherwise, it becomes paid complexity.
Performance Concurrency and Workload Suitability
Ignore vendor chest-thumping. Match the platform to the workload.
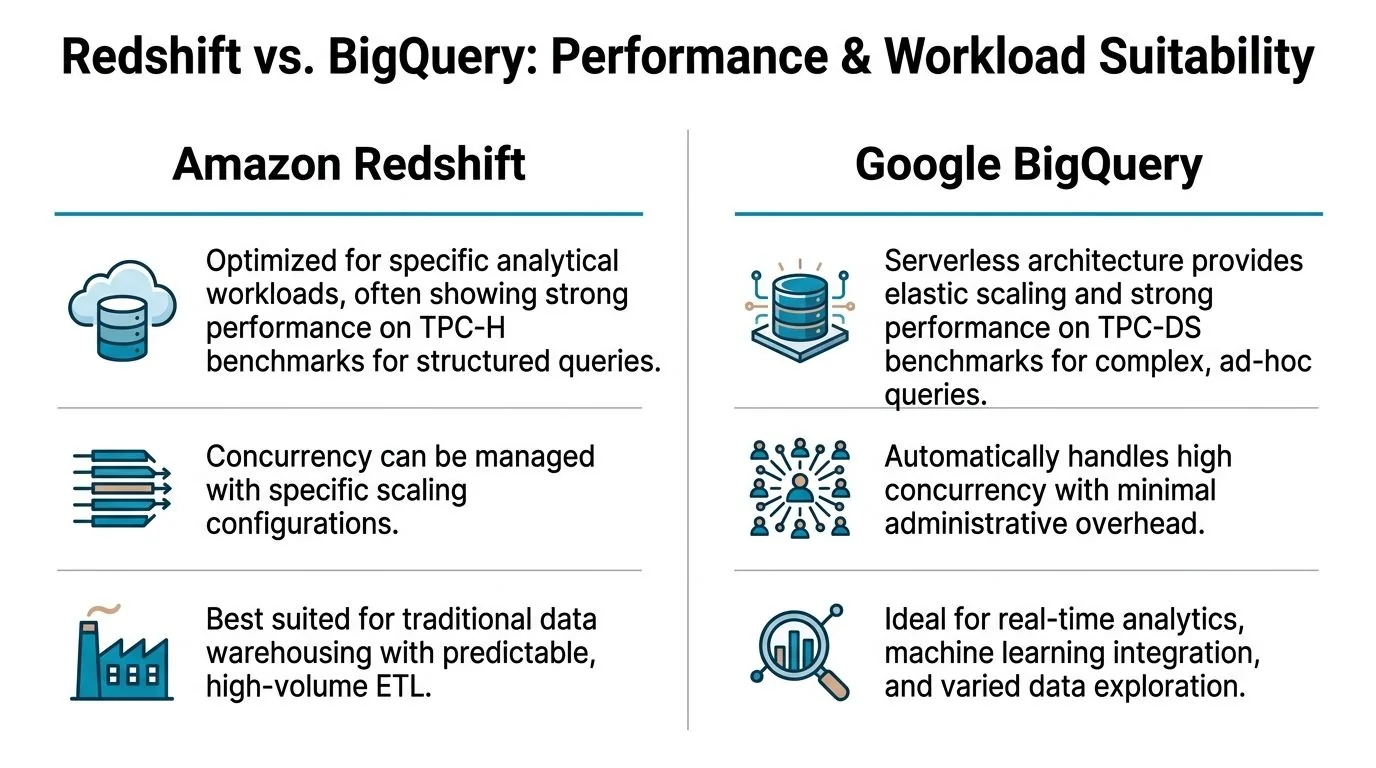
For enterprise BI, Redshift has the stronger benchmark story
AWS published benchmark results that are hard to dismiss for classic enterprise reporting. In AWS’s TPC-H benchmark at scale factor 1000, Redshift completed 18 of 22 queries with an average 3.6X faster performance than BigQuery. In TPC-DS at 3TB scale, Redshift outperformed BigQuery on 94 of 99 queries by an average 6X faster elapsed time (AWS benchmark details).
That matters because TPC-style tests are not perfect, but they are directionally useful for the workloads many enterprises commonly run:
- repeated BI queries
- large joins
- governed dashboards
- scheduled reporting
- concurrency from business users hitting the same semantic layer
If your warehouse is feeding Tableau, QuickSight, or a dbt-driven reporting stack all day, Redshift deserves the default position.
For exploratory analysis, BigQuery is easier to unleash
BigQuery wins a different argument. It is better for teams that do not know what they will query tomorrow. Data science, broad scans, experimental segmentation, feature prep, and bursty analysis fit its design.
That is not just because it is serverless. It is because the system tolerates variability better than a cluster you have to shape in advance. When a team wants to hit a massive dataset with irregular patterns, BigQuery is usually the less painful platform to operate.
Here is the practical rule:
| Primary workload | Better fit |
|---|---|
| Finance reporting | Redshift |
| Executive dashboards | Redshift |
| High-volume recurring BI | Redshift |
| Ad-hoc exploration | BigQuery |
| Variable data science workloads | BigQuery |
| Real-time streaming analytics pipelines | BigQuery |
The benchmark discussion is worth visualizing before you commit to a procurement direction.
Concurrency is not the same as predictability
A lot of teams ask the wrong concurrency question. They ask, “How many users can it handle?” The better question is, “How predictably does it handle the workload mix we have?”
Redshift is stronger when the pattern is known and tuneable. BigQuery is stronger when the pattern is volatile. Those are different operational promises.
Use this test in your architecture review:
- List your top ten warehouse queries by business importance.
- Separate recurring queries from exploratory ones.
- Measure who runs them and when.
- Decide whether you value repeatability or elasticity more.
- Choose the platform that fits the dominant pattern, not the aspirational one.
Many teams over-index on future experimentation and underweight current reporting obligations. That is a mistake. If your board pack, finance close, and ops dashboards drive daily decisions, optimize for that reality first.
Decision rule: Stable, business-critical SQL belongs on the platform built for repeatable performance. Unpredictable analytical spikes belong on the platform built for elastic compute.
Pricing Models and Total Cost of Ownership
Redshift and BigQuery charge you in different ways. That is obvious. What matters is how those pricing models behave under your workload and governance model.
BigQuery is often cheaper when usage is intermittent
According to Integrate.io’s comparison, BigQuery charges $5 per TB queried plus storage, and a 300GB daily query workload costs about $1.50 plus storage. The same source says this model suits sporadic use, while Redshift’s reserved capacity favors predictable workloads. It also states that Redshift often shows a 20% lower TCO for steady BI use cases, while BigQuery can be 25% cheaper for ad-hoc analysis (Integrate.io guide).
That maps cleanly to enterprise scenarios.
Scenario one with stable BI demand
If your teams run recurring dashboards every day, on provisioned infrastructure, Redshift is usually the financially cleaner choice. You can reserve capacity and know what you are paying for. Finance likes that. Procurement likes that. Platform teams like that.
Scenario two with bursty exploration
If analysts and data scientists query large datasets irregularly, BigQuery often wins. Paying by query is efficient when you are not keeping compute warm all day.
TCO depends on people, not just compute
The headline price is not the bill. Your TCO also includes the talent and consulting profile needed to operate the platform well.
Consider the hidden line items:
- Redshift hidden cost is specialist effort. You need people who can tune performance and manage the cluster well.
- BigQuery hidden cost is query sprawl. You need governance so teams do not run expensive scans without discipline.
- Redshift procurement upside is reserved instance savings and a more forecastable run rate.
- BigQuery operating upside is lower admin burden and faster setup for new workloads.
A direct way to frame redshift vs bigquery with finance is this:
| Cost lens | Redshift | BigQuery |
|---|---|---|
| Budget predictability | Stronger | Weaker without controls |
| Elasticity | Weaker | Stronger |
| Admin overhead | Higher | Lower |
| Ad-hoc cost efficiency | Lower | Higher |
| Stable BI cost efficiency | Higher | Lower |
Your consulting partner should not just quote implementation cost. They should show how they will control warehouse spend after go-live.
Ecosystem Migration and Consultancy Selection
This is the part most technical articles skip. They should not. Platform choice changes your partner market.
Redshift binds you more tightly to AWS
Redshift sits inside AWS. It works naturally with Glue, SageMaker, and IAM. That is an advantage if your company already runs there. Security reviews are easier. Procurement is cleaner. Delivery is usually faster because the surrounding services are already approved and familiar.
The downside is strategic rigidity. If multi-cloud flexibility matters, Redshift is the stickier choice.
BigQuery is stronger in mixed analytics and AI workflows
BigQuery fits organizations leaning into Google’s analytics and AI stack. It also handles direct external storage queries well, which can simplify some modernization patterns. For teams building variable analytics products and ML-adjacent workflows, this is a distinct advantage.
But migrations into and out of BigQuery are not frictionless. According to Polestar Analytics, BigQuery’s nested data handling requires flattening in Redshift, which complicates migration projects. The same source notes that consultancies are charging premiums for Redshift-to-BigQuery ports as part of broader modernization efforts (Polestar Analytics comparison).
That should influence your partner selection process immediately.
If you need help structuring that search, this guide to choosing a cloud data warehouse consultant is a practical starting point.
What to demand from consulting partners
Do not hire a generic “modern data stack” firm and hope they can fake depth. Force platform-specific proof.
Ask Redshift consultancies for:
- Performance tuning examples involving sort keys, distribution decisions, and workload management
- AWS integration depth across Glue, IAM, networking, and ingestion services
- Operational runbooks for maintenance and scaling
- Dashboard workload references using BI tools such as Tableau or QuickSight
Ask BigQuery consultancies for:
- Cost governance methods for pay-per-query environments
- Streaming architecture experience for real-time ingestion
- Data modeling approaches for semi-structured and nested data
- GCP integration depth across analytics and AI services
Procurement rule: Buy ecosystem competence, not slide-deck confidence. The warehouse is only one component of the delivery risk.
The Decision Framework A Practical Guide for CTOs
You do not need a philosophical debate. You need a decision tool your leadership team can use this week.
Redshift vs BigQuery decision matrix
| Evaluation Criterion | Key Questions for Your Team | Favors Redshift If… | Favors BigQuery If… |
|---|---|---|---|
| Primary workload profile | Are most queries recurring, governed, and business-critical? | Reporting, BI, dashboards, repeatable joins dominate | Exploration, experimentation, and irregular scans dominate |
| Cost model | Do you need fixed budgets or elastic consumption? | You want predictable spend and reserved capacity economics | You want pay-for-use economics tied to real query demand |
| Team skills | Do you have platform engineers and tuning expertise? | Your team can manage tuning and ongoing optimization | Your team wants minimal infrastructure management |
| Concurrency pattern | Are workloads stable or bursty? | Business users hit known dashboards repeatedly | Users run varied analytical workloads at unpredictable times |
| Ingestion design | Is real-time streaming central? | Batch-heavy pipelines are acceptable | Native streaming is a core requirement |
| Ecosystem fit | Which cloud stack is strategically dominant? | AWS is the operational center of gravity | GCP is the analytics and AI center of gravity |
| Migration risk | Will data model translation be painful? | You are staying inside structured relational patterns | You benefit from nested or external-query-friendly designs |
| Consulting market fit | What partner profile do you need? | You want AWS-heavy delivery partners | You want GCP-heavy analytics specialists |
Use these three executive recommendations
Choose Redshift when reporting pays the bills
Pick Redshift if your company runs on recurring BI, executive reporting, and governed analytics. That is especially true when your stack already centers on AWS and your data team can handle tuning discipline.
This is the right choice for finance-heavy, operations-heavy, and dashboard-heavy environments.
Choose BigQuery when variability is the business model
Pick BigQuery if your demand profile is irregular, your teams need fast experimentation, and you want to minimize infrastructure ownership. This is the better fit for analytics groups that live in wide scans, AI and ML prep, and evolving data products.
This is also the better fit if you want a consulting program that starts fast with less platform engineering upfront.
Do not choose either in isolation
Your warehouse does not live alone. Review it with dbt, Airflow, ingestion, governance, IAM, BI tools, and ML plans in the same room. If a consultancy cannot discuss the whole platform, remove them from the process.
RFP checklist for consultancy selection
Use this in your next vendor review.
-
Platform depth Ask for recent delivery examples specific to Redshift or BigQuery, not generic cloud data work.
-
Architecture stance Require a clear opinion on batch versus streaming, semantic layer design, and governance boundaries.
-
Cost control plan For Redshift, ask how they tune and right-size. For BigQuery, ask how they prevent query cost drift.
-
Migration method Require a written approach for schema translation, testing, rollback, and cutover.
-
Operations handoff Ask what your internal team will own after launch and what specialist skills you still need to hire.
-
Business workload mapping Make the partner map platform choices to actual workloads such as finance reports, product analytics, or ML prep.
Best engagement pattern by starting point
| Your situation | Best consulting engagement |
|---|---|
| Existing Redshift environment with rising cost or latency | Fixed-scope performance and cost audit |
| New AWS warehouse for governed BI | Foundation build with tuning, IAM, and BI workload validation |
| New BigQuery adoption for analytics modernization | Foundation build with FinOps guardrails and streaming design |
| Redshift to BigQuery migration | Discovery-first migration assessment before any full build commitment |
| Unclear choice between both | Paid architecture assessment with workload replay and operating model review |
The strongest CTOs make this decision with discipline. They do not ask which platform is “best.” They ask which platform best matches the company’s workload, cloud strategy, partner market, and tolerance for operational complexity.
If your core workloads are stable, choose Redshift. If your workloads are variable and exploratory, choose BigQuery. If your partner cannot explain the trade-offs in those terms, find another partner.
If you are shortlisting implementation partners, DataEngineeringCompanies.com helps buyers compare specialist consultancies by platform, delivery focus, and project fit, with practical tools for RFP planning and vendor evaluation.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
