Extract Transform Load Python: Production Pipelines Guide

Python ETL stopped being a scripting exercise years ago. It’s now an operating model decision. Organizations report a 40% reduction in pipeline development time and a 35% decrease in operational costs compared to legacy systems, and one mid-market enterprise cut annual data engineering spend from $1.2 million to $780,000 after moving to Python-based ETL, according to Everest Group’s 2026 study cited in the verified data above.
That upside only materializes when leaders treat extract transform load Python as architecture, not automation glue. The teams that win standardize orchestration, enforce contracts at ingest, and design for retries, scale, and ownership. The teams that lose ship clever scripts that nobody wants to maintain six months later.
Beyond Scripts Architecting Python ETL for Business Impact
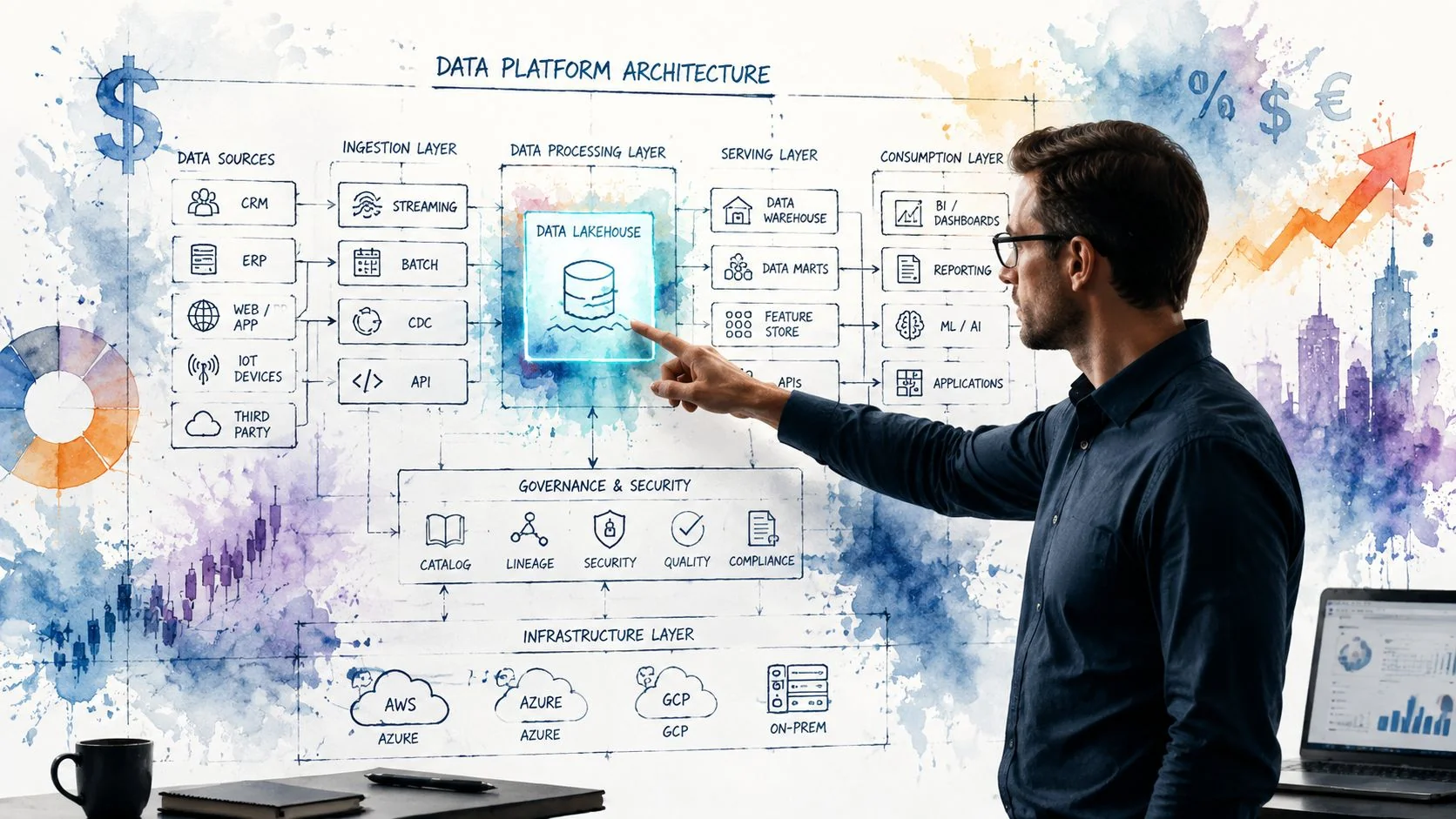
If your team still frames Python ETL as “we need a few scripts,” you’re under-scoping the problem. A production pipeline affects platform selection, cloud spend, governance, support coverage, and how quickly your analysts and ML teams trust the data.
The financial argument is already settled. Python-based ETL has proven value when it replaces brittle proprietary tooling and spreadsheet-grade integration habits. What matters now is whether your architecture captures that value or leaks it through rework, outages, and hand-maintained exceptions.
What leaders get wrong
Most internal discussions focus on language choice. That’s shallow. Python isn’t the decision. The decision is the system around Python.
Common failure patterns show up fast:
- Script-first design: Engineers write extraction logic before defining contracts, run states, and ownership.
- No orchestration model: Jobs rely on cron, manual reruns, or ad hoc sequencing.
- Weak recovery design: A failed load leaves partial tables, duplicate records, or silent data loss.
- No cost guardrails: Teams pull full tables from operational systems because it’s easier than designing incremental logic.
Practical rule: If rerunning a job can create duplicates, overwrite valid history, or require an engineer to “clean it up later,” you don’t have a pipeline. You have scheduled risk.
This is why workflow design matters as much as code quality. If your team is tightening scheduling discipline and trying to align data jobs with cloud cost controls, Server Scheduler’s guide for FinOps is a useful companion read because it connects orchestration choices to operational governance instead of treating scheduling as a side issue.
The right framing
A CTO should evaluate Python ETL across four business questions:
| Decision area | What to ask |
|---|---|
| Platform fit | Should transforms run in Python, dbt, Spark, or a mix? |
| Operating model | Will your team own Airflow or Prefect, or should a partner implement and stabilize it? |
| Risk control | Where are schema enforcement, lineage, and rollback defined? |
| Economics | Is this reducing engineering effort and platform spend, or just moving complexity around? |
Treat Python as the control plane for data movement and transformation logic. Then design the rest of the system like it matters, because it does.
The Anatomy of a Production Python ETL Pipeline
Python is already the market standard. Over 65% of data professionals use it for ETL, 89% of data engineering consultancies list Python as a core competency, and 78% of new enterprise ETL pipelines are Python-based, according to the verified data above.
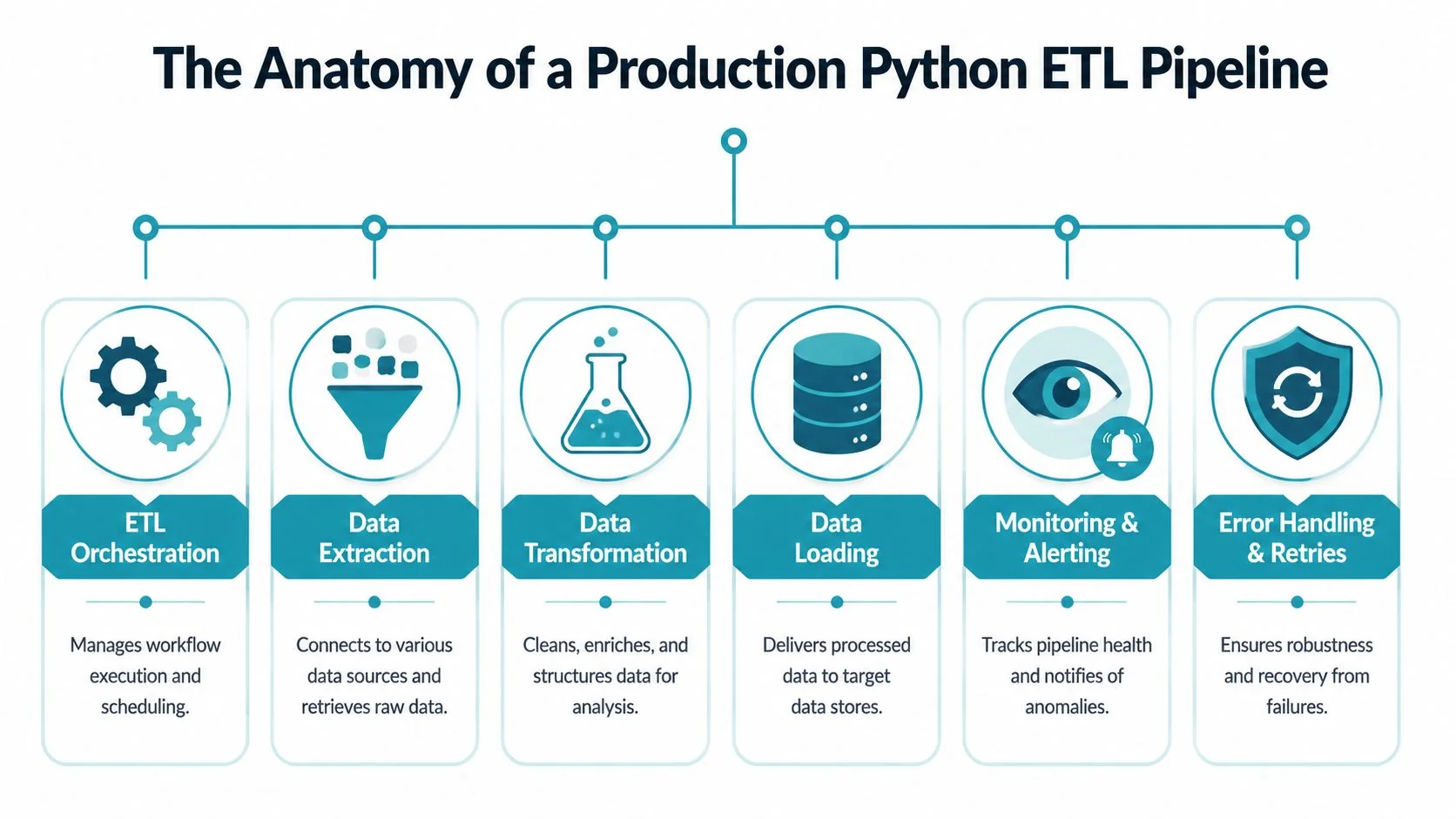
That doesn’t mean every Python ETL architecture is good. The production pattern is straightforward. Build around six components, not one monolithic script.
The six components that actually matter
-
Extraction
Pull data from APIs, SaaS platforms, event streams, object storage, and transactional databases. For OLTP systems, the default should be incremental extraction design, not recurring full pulls.
-
Transformation
Use Pandas for moderate workloads and highly targeted logic. Move heavier transformations toward distributed execution when volume and SLA pressure justify it. If you’re loading into Snowflake or BigQuery, keep warehouse-native transformation in play with dbt where SQL is the cleaner option.
-
Loading
Your target decides a lot. Snowflake favors warehouse-centric patterns. Databricks opens up lakehouse-oriented flows and Spark-native scaling. BigQuery changes both pricing behavior and optimization choices. Don’t abstract this away. Loading strategy is platform strategy.
Before locking the code structure, it helps to see how maintainability degrades over time in real projects. Teams refactoring inherited ingestion jobs usually benefit from a clean code review checklist, and improve code with Appjet.ai gives a practical lens for spotting where ETL codebases become fragile.
The control layer most teams underinvest in
Orchestration is where architecture stops being theoretical. Airflow remains the default choice for complex dependency graphs and multi-system scheduling. Prefect is often cleaner when teams want Python-native flow definitions with less platform overhead.
Your orchestrator should manage:
- Scheduling: Time-based, event-based, and dependency-aware execution
- Retries: Controlled reruns for transient failures
- State tracking: Clear visibility into what ran, what failed, and what produced data
- Operational ownership: Alerts routed to people who can fix the issue
Production ETL lives or dies in the orchestration layer. A good DAG prevents confusion before it prevents failure.
A practical architecture blueprint
| Layer | Preferred role |
|---|---|
| Python services | Connectors, validations, transformation logic, and control flow |
| Airflow or Prefect | Scheduling, retries, dependency management, run visibility |
| dbt | Warehouse-native transformations, testing, documentation |
| Snowflake or BigQuery | Structured analytical serving layer |
| Databricks | Large-scale transformation and lakehouse workloads |
| Cloud storage on AWS, Azure, or GCP | Landing zone, staged files, recovery paths |
If a consulting partner shows you a single repo with a few Python files and vague talk about “automation,” reject it. Real pipeline architecture has layers, boundaries, and operational controls.
Ensuring Data Integrity and Pipeline Resilience

Most ETL failures aren’t dramatic. They’re quiet. A source team renames a column, changes a type, or ships malformed records, and your downstream tables keep loading bad assumptions until someone notices a broken dashboard or model.
That’s why resilience in extract transform load Python starts at ingest, not at the exception handler.
Schema drift is the first problem to solve
Schema Drift causes pipeline crashes in 30% to 40% of unmonitored deployments, and Strict Schema Assertions at Ingest reduce those failure rates by 75% according to the verified data above.
Use published contracts. Enforce them before transformation starts. In practice, that means validating column names, required fields, types, and accepted formats with tools such as Pydantic or strict Pandas validation routines.
What this changes operationally:
- Bad data gets stopped early
- Root cause is visible
- Upstream teams get a concrete contract violation
- Downstream consumers don’t inherit corrupted assumptions
Operator advice: Reject unknown shape changes at the boundary. Don’t “handle it downstream.” Downstream is where trust dies.
CDC and idempotency are not optional
Change Data Capture can cut resource consumption by up to 70% compared with full-table scans, according to the verified data above. That’s a performance win, but the bigger gain is operational discipline. CDC forces your team to think in deltas, watermarks, and reconciliation instead of brute-force reloads.
Idempotency belongs beside CDC. If a retry creates duplicates or conflicting state, your pipeline isn’t safe to operate. Design each load so that rerunning the same unit of work produces the same result set in the target. That usually means stable keys, deduplication logic, and controlled merge behavior.
Resilience checklist for technical due diligence
When reviewing an internal design or a consultancy proposal, look for these controls:
- Contract enforcement: Explicit schema validation at ingest
- Retry strategy: Automated retries with backoff for transient failures
- Deduplication controls: Load logic that remains correct after reruns
- Auditability: Run metadata, rejected-record tracking, and clear lineage
- Recovery path: Rollback or replay procedures for partial loads
A pipeline that only works under perfect source conditions doesn’t belong in production. Reliability is a design choice.
Scaling Your Python ETL for Performance and Cost

Python ETL performance problems usually come from one source. Engineers write data processing code like application code. That’s how teams end up with row-by-row loops, memory blowups, and batch windows that keep expanding until cloud bills become the escalation path.
The mistakes that drive cost
The verified data is blunt. For large datasets, replacing row-by-row loops in Pandas with vectorized operations yields 10x to 20x speedups. For massive datasets, parallelization with tools like Dask reduces execution time by 50% to 80%, and memory overflow occurs in 25% of unoptimized pipelines unless teams use chunking techniques.
That translates into clear architectural guidance:
| Bad habit | Better pattern | Why it matters |
|---|---|---|
| Iterating rows in Pandas | Vectorized operations | Faster runs and lower compute waste |
| Single-thread processing for large jobs | Dask or multiprocessing | Better SLA adherence |
| Reading full files into memory | Chunked or streamed reads | Prevents memory failures |
| Loading without optimization | Indexed, staged, and planned writes | Faster warehouse ingestion |
When to move beyond Pandas
Pandas is fine until it isn’t. If data volume is growing, SLA pressure is rising, or your team is already running on Databricks, don’t force a single-machine pattern to do distributed work.
That’s where platform choice becomes inseparable from ETL design. If your roadmap includes larger-scale transformations, ML-adjacent processing, or lakehouse consolidation, it’s smart to evaluate Databricks consulting companies before you overbuild custom scaling logic in Python alone.
Fast code isn’t the goal. Predictable runtime at acceptable cost is the goal.
Cost control comes from architecture, not cleanup
The best-performing teams use a layered strategy:
- Vectorize first: Fix the obvious inefficiencies before adding infrastructure.
- Parallelize second: Introduce Dask or platform-native distributed execution where the workload justifies it.
- Control memory deliberately: Chunk reads, stream large inputs, and avoid loading oversized datasets into one process.
- Align transforms to platform economics: Some work belongs in Python. Some belongs in Snowflake, Databricks, or BigQuery.
If your cloud bill keeps climbing, the issue usually isn’t Python. It’s undisciplined pipeline design.
Evaluating Partners for Your Python ETL Project

Most failed consulting engagements don’t fail because the partner can’t write Python. They fail because the partner can’t translate business requirements into an operating data platform.
According to DataEngineeringCompanies.com, the average minimum project threshold for data engineering consulting is $75,000, with typical 3 to 6 month timelines. Top-tier Snowflake and Databricks specialists charge $185 to $265 per hour, while Airflow/dbt experts average $140 to $190 per hour.
What to ask before you sign
Use this checklist in every discovery call.
Technical depth
- Ask for architecture examples: You want to hear how they handle orchestration, retries, schema enforcement, and incremental loads.
- Probe platform judgment: Can they explain when work belongs in Python versus dbt, Snowflake, Databricks, or BigQuery?
- Test for production thinking: If they only talk about connectors and dashboards, they’re not leading the right layer.
Delivery discipline
- Request their testing model: Unit tests, contract tests, and deployment controls should be standard.
- Ask who owns cutover and stabilization: Implementation isn’t done at first load.
- Clarify post-launch support: Hypercare, bug response, and operational handoff must be explicit.
Compare firms on decision quality, not pitch quality
A simple scoring model works better than generic impressions:
| Criterion | What strong partners show |
|---|---|
| Architecture quality | Clear opinion on Snowflake, Databricks, dbt, Airflow, and cloud fit |
| Resilience design | Specific controls for drift, retries, lineage, and reruns |
| Scalability | Experience with both moderate and large-volume processing patterns |
| Governance | Role-based access, data contracts, auditability, and ownership clarity |
| Commercial fit | Transparent rates, realistic scope, and honest timeline assumptions |
If your ETL initiative supports AI delivery as well as analytics, pair the vendor conversation with an internal capability review. Understand your AI capability gaps before you assume a pipeline project alone will solve readiness issues.
Good partners narrow scope before they expand it. Weak partners sell flexibility because they haven’t made the hard design decisions yet.
For a more structured procurement process, use this data engineering vendor assessment framework to pressure-test proposals, references, and implementation plans.
Your Next Steps in Python ETL Strategy
Start with an internal reality check. Separate teams that can write Python from teams that can run production data systems. Those are different capabilities. If you lack orchestration ownership, contract enforcement, warehouse design judgment, or support readiness, document that gap now.
Then define a pilot with business gravity. Keep it to one page. Name the business owner, source systems, target platform, transformation scope, governance requirements, and success criteria. A real pilot has bounded scope and operational expectations. It isn’t a proof of concept that ignores monitoring and recovery.
Finally, run two partner conversations in parallel, even if you expect to build mostly in-house. That forces sharper decisions on timeline, platform fit, and staffing. Use your evaluation criteria, not vendor decks.
Your three-step plan is simple:
- Audit capability
- Scope one production-relevant pilot
- Benchmark build-versus-partner options
If you’re comparing firms, rates, and platform specialists, use DataEngineeringCompanies.com to build a shortlist grounded in delivery capability instead of marketing claims. That shortens vendor evaluation and helps you avoid paying enterprise consulting rates for script-level work.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Featured Data Engineering Partners
Vetted firms whose specialty matches this article.
Related Analysis

Understanding What Is Materialised View: A Guide for Leaders
Understand what is materialised view and its impact on data platform cost & performance. Essential guide for engineering leaders evaluating strategies in 2026.

A CTO's Guide to Ecommerce Data Engineering
Build a high-performance ecommerce data engineering architecture. Compare platforms, integration patterns, and vendor selection criteria for maximum ROI.

How to Hire an Apache Kafka Consulting Firm That Delivers
A guide for engineering leaders on scoping, vetting, and hiring the right Apache Kafka consulting partner. Learn to avoid pitfalls and maximize your ROI.