Directed Acyclic Graphs: A CTO's Data Engineering Guide

Your team already has the symptoms. A revenue dashboard misses its morning SLA because an upstream dbt run waited on a file drop nobody tracked in Airflow. A Databricks job reruns and writes duplicate records because the task wasn’t idempotent. A Snowflake migration stalls because nobody can explain which transformations must finish before finance models refresh.
That isn’t a tooling problem first. It’s a dependency problem.
For CTOs and Heads of Data buying data engineering services, directed acyclic graphs belong in the same category as SQL depth, cloud architecture judgment, and governance discipline. If a consultancy can’t design, test, and operate DAG-driven pipelines across Airflow, dbt, Spark, Snowflake, Databricks, and BigQuery, you’re not buying modernization. You’re buying a nicer version of the same fragility.
Why Your Data Pipelines Are Failing
Most broken pipelines don’t fail because extraction is hard or because your warehouse picked the wrong compression setting. They fail because dependency logic lives in too many places at once. Some of it sits in Airflow. Some sits in dbt model references. Some sits in ad hoc scripts, cron jobs, Slack instructions, and assumptions that only one senior engineer understands.
That creates three operational failures.
- Invisible dependencies: Teams trigger downstream jobs before upstream data is ready.
- Untraceable failures: An incident starts in one task, but the blast radius only shows up hours later in reports or ML features.
- Unsafe reruns: Recovery creates duplicates, stale outputs, or partial loads because the workflow wasn’t designed as a coherent graph.
The business stakes are high because data engineering demand keeps climbing. The global big data engineering services market reached $91.54 billion in 2025 and is projected to more than double by the end of the decade, which signals sustained demand for pipeline architecture and cloud platform modernization services, according to TalentMsh’s market overview.
What brittle architecture looks like
You don’t need another maturity model to spot it. Look for these patterns in your current estate:
- Orchestration drift: Airflow schedules one thing, dbt lineage implies another, and cloud-native jobs run on separate timers.
- Manual gates: Engineers wait for messages, tickets, or file appearances instead of machine-enforced task dependencies.
- Monolithic recovery: One failed task forces a full pipeline rerun because the workflow can’t isolate state cleanly.
Practical rule: If your team can’t draw the execution path for a critical pipeline in one session, the architecture already has more coupling than your operating model can support.
DAGs matter because they turn pipeline logic into an explicit structure instead of tribal knowledge. That structure is what lets teams automate safely, observe failures clearly, and scale delivery across AWS, Azure, and GCP without multiplying operational chaos.
The Core Anatomy of a DAG in Data Engineering
A DAG is simple in concept and unforgiving in practice. Each node is a task. Each directed edge says one task depends on another. The acyclic part means the graph can’t loop back on itself.
In data engineering, that matters because execution needs a finish line. If task C depends on B, and B depends on A, the system can schedule the work. If A somehow also depends on C, you’ve built a deadlock in diagram form.
Think like a production line
A useful analogy is a staged manufacturing line. You can’t quality-check a product before assembly. You can’t package it before quality check. Some steps run in sequence. Others can run in parallel. The graph captures that truth directly.
That is why DAGs are the right mental model for ETL, ELT, feature pipelines, and reporting refreshes. In data engineering, directed acyclic graphs serve as the foundational topological structure for orchestrating complex data pipelines, where each node represents a specific computational task and directed edges define dependency order. The absence of cycles guarantees that a topological sort exists, allowing orchestrators to schedule tasks in a linear, non-repeating sequence, as described in GigaSpaces’ explanation of DAGs in data engineering.
Why topological sort matters to a CTO
Topological sort sounds academic. In practice, it’s the reason an orchestrator like Airflow can produce a deterministic execution plan instead of guessing.
That gives you concrete operating benefits:
- Predictable scheduling: The platform knows what can run now versus what must wait.
- Parallelism with control: Independent nodes run concurrently without violating dependencies.
- Cleaner failure handling: A failed upstream task blocks the right downstream tasks instead of corrupting the entire run.
For architecture reviews, I like one test: ask the team to represent a key workflow visually before they touch code. If they struggle, implementation will be worse than design. Teams that want a lightweight way to build Mermaid flowcharts often get faster alignment between platform engineers, analytics engineers, and stakeholders before orchestration logic lands in production.
A good DAG removes ambiguity. A bad one documents confusion after the fact.
DAGs in Action Across Your Data Stack
DAGs aren’t confined to one orchestration layer. They show up across your stack, often under different names and abstractions. If you’re running Snowflake with dbt and Airflow, or Databricks with Spark jobs and ML pipelines, you’re already relying on DAG logic whether your team says it out loud or not.
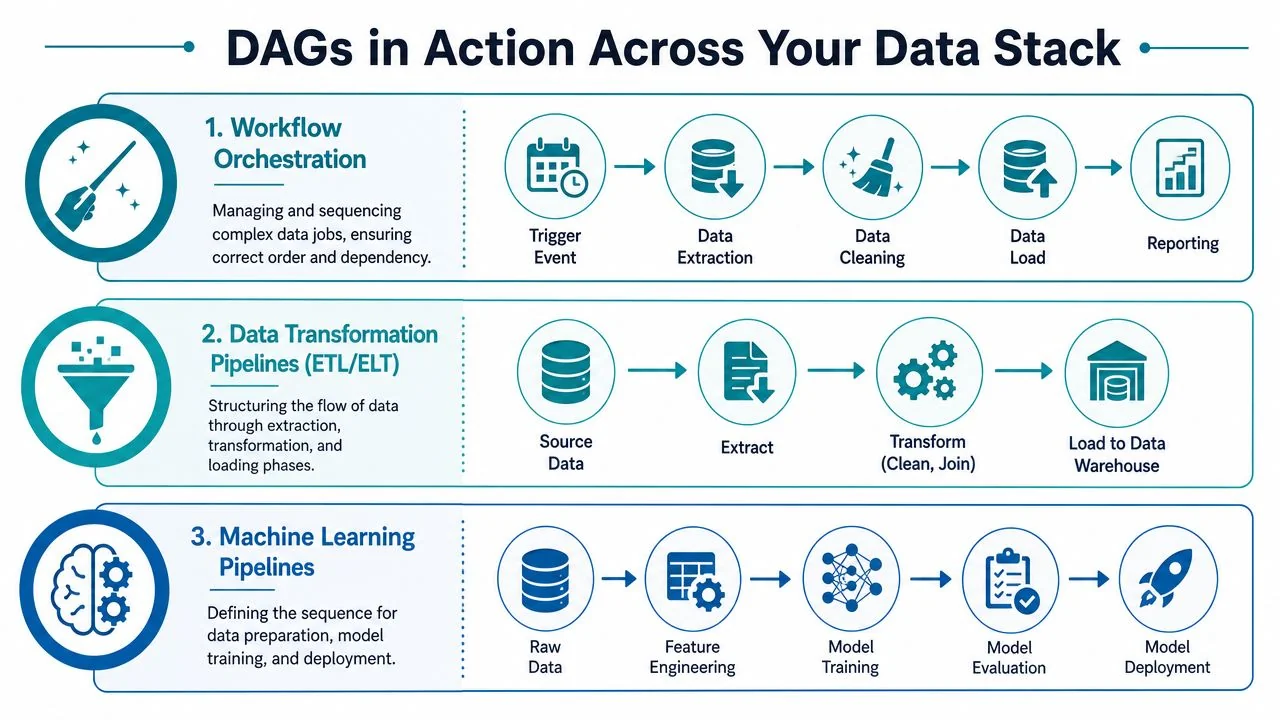
Workflow orchestration
This is the most obvious expression of a DAG. In Apache Airflow, tasks are defined in Python and stitched together as explicit dependencies. In Dagster and Prefect, the interface differs, but the principle doesn’t. The graph is the contract for execution order, retries, and observability.
A typical enterprise flow looks familiar:
- Ingest: Pull source data from SaaS apps, files, or operational databases.
- Transform: Run dbt models, Spark jobs, or SQL procedures.
- Publish: Refresh downstream marts, APIs, or analytics outputs.
If you’re comparing orchestrators, the right question isn’t which UI looks nicer. It’s which platform lets your team express dependencies clearly, test them, and operate them at the level of complexity your estate already has. This DataEngineeringCompanies.com guide is useful for framing that decision around actual workflow trade-offs.
Lineage and governance
DAGs also surface the shape of your data lineage. When an executive asks what breaks if a CRM field changes, a lineage graph should answer that in minutes. When governance teams ask which transformation produced a regulated metric, the graph should show both upstream and downstream relationships.
That’s why DAG literacy matters beyond platform engineering. It affects incident response, auditability, and trust in BI. For leaders connecting pipelines to reporting outcomes, Wonderment Apps’ BI strategies offer a practical view of how pipeline structure shapes business intelligence delivery.
Execution engines and ML workflows
Spark also relies on DAG concepts internally. A job gets broken into stages and tasks based on dependencies and opportunities for parallel execution. Your team doesn’t need to micromanage every internal edge, but your consultancy should understand how transformation choices affect that graph, especially in Databricks environments where cost and runtime are tightly linked.
ML workflows follow the same pattern. Feature engineering depends on clean data. Training depends on features. Evaluation depends on training output. Deployment depends on passing gates. If those links aren’t explicit, the system stops being a pipeline and becomes a pile of scripts.
Essential DAG Design Patterns and Anti-Patterns
Teams don’t typically fail because they chose DAGs. They fail because they implement them carelessly.
Patterns worth enforcing
The best DAGs are boring to operate. That’s a compliment.
| Pattern | What good looks like | Why it works |
|---|---|---|
| Modular tasks | Small, single-purpose nodes for ingestion, validation, transform, and publish | Easier testing, clearer ownership, safer reruns |
| Idempotent execution | A rerun produces the same correct outcome without duplicate side effects | Incident recovery stops being a data correction project |
| Explicit dependencies | All sequencing lives in the orchestrator or model graph, not in side channels | Debugging gets faster and governance gets cleaner |
| Controlled parallelism | Fan-out only where data is independent, fan-in only where consolidation is required | Better runtime without creating hidden contention |
| Dynamic generation with guardrails | Parameterized DAG creation for repeated patterns across tenants, domains, or tables | Scales architecture without copy-paste sprawl |
Anti-patterns that cost money
The most expensive one is the God DAG. One giant workflow tries to handle everything: ingestion, transformations, ML scoring, exports, alerts, and cleanup. It becomes unreadable, slow to deploy, and dangerous to modify.
Other anti-patterns show up just as often:
- Dependencies outside the graph: A task waits for an S3 file naming convention, a Teams message, or a manual checklist.
- Branching nobody can reason about: Conditional logic sprawls until no one knows which path executed.
- Mixed concerns inside one node: A single task extracts data, transforms it, writes to the warehouse, and sends a notification.
- Platform mismatch: Airflow manages orchestration, but business logic lives in shell scripts and warehouse-specific hacks.
Architect’s test: If replacing one upstream source requires reading five repos and asking three people, the DAG isn’t your source of truth.
For teams reviewing alternatives, it helps to explore data pipeline designs before locking into one orchestration style. Good architecture standards start with examples the whole team can critique.
A short walkthrough like the one below is often enough to align engineers and buyers on what “good” looks like in production.
What to demand in implementation reviews
Don’t accept “it runs” as a design standard. Ask for evidence that the pipeline is operable.
- Show rerun behavior: What happens if a transform task fails after partial write?
- Show dependency ownership: Where is the canonical dependency graph defined?
- Show blast-radius containment: Which downstream tasks stop, and which continue safely, when one node fails?
Those three questions expose weak DAG design fast.
How to Vet a Consultancy’s DAG Expertise
Many procurement processes frequently encounter breakdowns. Plenty of firms can talk about DAGs. Far fewer can apply them across enterprise data estates where Airflow, dbt, Spark, Snowflake, Databricks, and cloud-native services all intersect.
That gap becomes severe when teams move from workflow orchestration into causal and analytical dependency modeling. A 2025 study found that 74% of data teams attempting causal inference in enterprise settings fail due to unvalidated DAG assumptions, and no vendor-neutral guide exists for this, according to the ScienceDirect study abstract cited here. For buyers, the lesson is broader than causal inference. If a consultancy can’t validate the assumptions inside a graph, it won’t manage complexity well when your production pipelines get messy.
The questions that separate operators from slideware
You want to know whether the partner can build DAGs that survive handoff, incident response, and scale. Ask for specifics, not philosophy.
| Evaluation Area | Key Question to Ask | What to Look for (Green Flag / Red Flag) |
|---|---|---|
| Orchestration approach | Which orchestrator do you recommend for our stack, and why? | Green flag: Ties Airflow, Dagster, or Prefect choice to team skills, platform fit, and operational model. Red flag: Pushes a favorite tool without explaining trade-offs. |
| Dependency design | Where will dependencies be defined and enforced? | Green flag: One canonical graph with clear boundaries between orchestration and transformation logic. Red flag: Dependencies split across scripts, tickets, and undocumented conventions. |
| Task design | How do you ensure tasks are rerunnable? | Green flag: Can explain idempotency, state handling, and partial failure recovery. Red flag: Treats reruns as a manual cleanup exercise. |
| Testing discipline | How do you test DAG logic before production? | Green flag: Covers unit tests, integration tests, and dependency validation. Red flag: Relies on staging runs alone. |
| Observability | How will operators detect upstream failure impact quickly? | Green flag: Shows logs, lineage, alerting, and task-level monitoring strategy. Red flag: Focuses only on whether the scheduler itself is up. |
| Performance tuning | How do you reduce runtime and warehouse spend in a DAG-based pipeline? | Green flag: Connects graph design to parallelism, warehouse workloads, and expensive transformations. Red flag: Talks only about infrastructure sizing. |
| Governance and lineage | How will this design support audits and change impact analysis? | Green flag: Explains lineage, ownership, and traceability from source to report. Red flag: Treats governance as documentation after build. |
| Handoff quality | What does our team receive at go-live? | Green flag: Runbooks, graph documentation, failure scenarios, and ownership mapping. Red flag: Hands over code with minimal operating guidance. |
Hire the consultancy that can show how dependencies are enforced, tested, and recovered from. Don’t hire the one that only knows how to draw the boxes.
Non-negotiables for modern stacks
For cloud data platform work, DAG expertise has to connect to the rest of the delivery.
- Snowflake and BigQuery projects: The partner should have a strong understanding of SQL, because advanced query optimization and efficient scale performance remain central skills for data engineers, as outlined in dbt’s 2025 data engineer skills view.
- Databricks and Spark-heavy projects: The partner should explain how graph design affects stage boundaries, runtime behavior, and cost control.
- Governance-led programs: The partner should map execution DAGs and lineage models into your operating model, not bolt them on later.
If a firm can’t answer these questions crisply in an RFP or technical interview, remove them early.
Your Action Plan for Building Resilient Pipelines
Start with one critical workflow. Map every task, every dependency, and every out-of-band handoff. Then remove anything that isn’t enforced in the graph. Audit your current workflows before the next incident does it for you.
Next, standardize on a DAG-native orchestrator as the source of truth for execution dependencies. Airflow, Dagster, and similar tools differ in ergonomics, but the principle is the same. One graph. One operating model. One place to troubleshoot.
Finally, upgrade your consultancy vetting process. Turn the checklist above into a required part of every RFP, architecture review, and reference call. If you want a faster way to compare firms on capabilities, platform fit, and delivery criteria, DataEngineeringCompanies.com provides rankings, shortlists, and evaluation tools built for data engineering buyers.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Featured Data Engineering Partners
Vetted firms whose specialty matches this article.
Related Analysis

A Practical Guide to Modern Data Pipeline Architecture
Discover how a modern data pipeline architecture can transform your business. This practical guide covers key patterns, components, and vendor selection.

A Practical Guide to Data Orchestration Platforms
Discover how modern data orchestration platforms power AI, cloud-native stacks, and real-time workflows. Compare top tools and build a future-proof strategy.

Extract Transform Load Python: Production Pipelines Guide
Build production-grade Extract Transform Load Python pipelines. Learn architecture, scaling, orchestration, and how to evaluate consulting partners effectively.