Your Data Pipeline Cost Guide: How to Benchmark & Budget for Consulting Engagements

Your data pipeline costs are out of control. A typical mid-market company spends between $300,000 and $1.2 million annually on its data pipelines, yet most of that spend is a black box. This guide provides a direct framework for engineering leaders to dissect data pipeline costs, justify consulting engagements, and regain control of their budget. We will focus on the three primary cost drivers: cloud infrastructure, platform licensing, and engineering talent.
The 5 Layers of Data Pipeline Total Cost of Ownership (TCO)
To accurately budget for a data pipeline, you must look beyond the obvious cloud and SaaS bills. The Total Cost of Ownership (TCO) is spread across five core areas. Overlooking one component leads to budget overruns and operational failures.
Think of TCO as the direct result of your architecture, team efficiency, and the often-ignored price of understanding the true costs of data debt. This debt quietly inflates every other cost category.
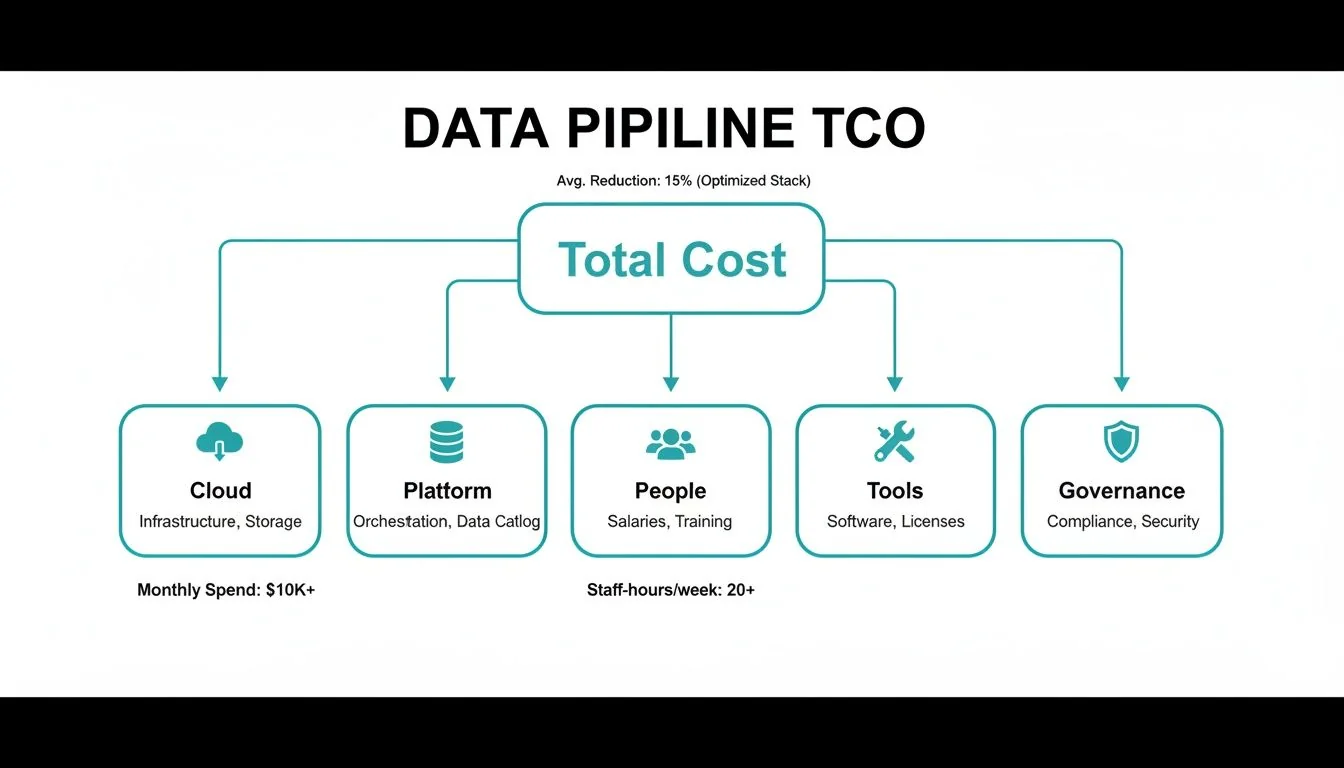
This breakdown reveals a critical insight: people—your engineers and consultants—represent the largest share of the budget. At the same time, crucial areas like data governance and specialized tooling are consistently underfunded, creating downstream data quality issues and security risks.
Deconstructing the 3 Largest Cost Drivers
When a data pipeline budget spirals, the cause is almost always one of three factors: cloud infrastructure spend, platform licensing, or talent costs. Mastering these is fundamental to achieving predictable and efficient data operations.

Cloud Infrastructure Bills
Your cloud invoice is the cost foundation. While compute and storage are significant, the hidden killer is data egress fees—the cost of moving data out of your cloud or between regions. These charges are frequently missed during architectural design but appear prominently on the bill.
Each cloud provider presents unique cost challenges:
- AWS: Offers a vast service portfolio, but its pricing is notoriously complex. Data egress fees are a primary source of budget surprises if not explicitly modeled.
- Azure: The logical choice for Microsoft-centric organizations. However, pricing for services like Azure Data Factory is complex, with multiple billing dimensions like DIUs and vCore-hours that must be tracked.
- GCP/BigQuery: Praised for performance and a cleaner pricing model. The risk here is cost escalation from high query volumes if SQL is not optimized for BigQuery’s slot-based architecture.
Platform Licensing Models
Modern data platforms like Snowflake and Databricks operate on consumption-based pricing. Your bill is directly tied to usage, making a deep understanding of their billing units non-negotiable.
Snowflake’s credit model is consumed by virtual warehouse uptime. Databricks’s DBU model is tied to cluster runtime. The outcome is identical: a poorly written, long-running query burns budget on either platform. The cost simply manifests differently based on their unique pricing mechanics.
Engineering and Consulting Rates
Talent is the single largest line item in any data engineering initiative. It is a direct supply and demand problem: the market for data pipeline tools will reach $48.33 billion by 2030, but the supply of skilled engineers has not kept pace.
The right team delivers massive returns—organizations report an average 3.7x ROI on data projects. These returns are contingent on securing top-tier talent. Use these statistics to build your business case for investing in data pipeline efficiency.
What should you budget for consulting? According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, hourly rates vary dramatically by geography.
Data Engineering Consulting Rate Benchmarks
| Role | Onshore (US/CAN) Rate | Nearshore (LATAM/EE) Rate | Offshore (India/SEA) Rate |
|---|---|---|---|
| Data Architect | $175 - $300 /hr | $95 - $160 /hr | $65 - $110 /hr |
| Senior Data Engineer | $150 - $250 /hr | $80 - $140 /hr | $50 - $95 /hr |
| Mid-Level Data Engineer | $120 - $190 /hr | $65 - $115 /hr | $40 - $75 /hr |
| Data Quality/Test Engineer | $110 - $180 /hr | $60 - $100 /hr | $35 - $65 /hr |
A blended team model incorporating nearshore or offshore talent can extend your budget significantly. The priority is to partner with a firm that guarantees quality across all locations, ensuring you do not sacrifice engineering excellence for a lower hourly rate.
Selecting the Right Consulting Engagement Model
Selecting the wrong engagement model is the fastest way to blow your budget. The commercial structure must align with your project’s clarity and goals. A mismatch risks paying for your consultant’s learning curve or getting locked into a scope that is no longer relevant.
Time and Materials (T&M)
With T&M, you pay for hours worked and direct costs incurred. This model provides maximum flexibility, making it ideal for projects with undefined paths, such as architectural discovery or agile development. The tradeoff is that all risk falls on you. If scope expands or unexpected complexity arises, you pay for the extra time.
Contractual tip: Mandate a “right to replace” clause for underperforming resources and negotiate a “not to exceed” (NTE) cap on hours to control weekly burn. Find more details on market rates in our guide to data engineering consulting rates.
Fixed-Price Engagements
A Fixed-Price agreement is a set price for a well-defined scope of work. This model excels when requirements are locked, such as a data migration from a legacy system to Snowflake where source and target schemas are pre-mapped. Risk shifts to the consulting firm, incentivizing them to be efficient.
Red Flag: Be wary of vendors pushing a fixed-price deal on a project with many unknowns. This is a classic tactic. They either bake a massive contingency buffer into the price (which you pay for) or set you up for aggressive change orders for anything not explicitly stated in the original SOW.
Outcome-Based Agreements
This is the most aligned engagement model, tying a significant portion of consultant payment to hitting specific, measurable business goals. For example, final payment could depend on reducing data processing costs by 20% or achieving a 99.9% data quality score.
This model creates a true partnership but requires high trust and mature, reliable metrics to verify outcomes. It is best suited for optimization projects where ROI is clearly measurable.
Your 5-Step Data-Driven Budgeting Framework
Guesswork has no place in a data engineering budget. A defensible budget ties every dollar to a clear business outcome. This five-step process moves your financial planning from abstract estimates to a concrete, data-backed proposal.
The 5-Step Budgeting Checklist
-
Baseline Current Costs: Audit every dollar you currently spend. Dig into your cloud bills from AWS, Azure, or GCP, tally software licenses for Snowflake, Databricks, or Fivetran, and review all consulting agreements. This provides a factual starting point.
-
Scope the Future State: Define the “why.” What specific business outcomes drive this initiative? Are you launching new data products? Unlocking analytics for marketing? This connects the technical work directly to business value.
-
Estimate Platform and Infrastructure Costs: Model costs using official pricing calculators from your cloud and data platform vendors. Run multiple scenarios for compute, storage, and data transfer to understand how usage translates into fees.
-
Calculate Engineering Effort: Budget for the people. Break the project into phases (e.g., discovery, design, build, test, deploy). Estimate the number of sprints or person-weeks for each phase and apply the benchmark rates from your chosen engagement model.
-
Incorporate a Contingency Buffer: No project goes exactly as planned. Add a 15-20% contingency buffer to the total estimate. This is not padding; it is a realistic provision for unexpected technical hurdles or scope adjustments and demonstrates thorough planning.
Use a modeling tool to translate requirements into a concrete budget. You can see how adjusting inputs like project timeline or team composition immediately impacts the total cost. Model your own scenarios with our interactive data engineering cost calculator.
Controlling Pipeline Costs with FinOps
Managing dynamic, consumption-based cloud costs with a static annual budget is a losing battle. The only way to control data pipeline spending is through the proactive discipline of FinOps. A spreadsheet cannot see the real-time impact of an inefficient query or over-provisioned cluster racking up costs.
From Manual Tracking to AI-Driven Control
The industry is shifting away from manual cost tracking. Nearly 48% of teams now use AI-driven tools for anomaly detection. This is a direct response to the fact that architectures with heavy data transfer were causing 30-50% of surprise cloud spending. With a reported 27% of all cloud spend being pure waste from idle or over-provisioned resources, the need for automated oversight is undeniable. These findings on cloud cost trends highlight the urgency.
Core FinOps Strategies for Data Pipelines
Applying FinOps is not about watching dashboards; it is about implementing specific strategies that change how your team operates.
-
Automated Showback and Chargeback: This creates accountability. Implement systems that automatically attribute cloud costs to the specific teams, projects, or products that consumed them. When engineers see the direct financial impact of their code, they code more efficiently.
-
Continuous Resource Rightsizing: Your workloads are not always running at peak. Use monitoring tools to continuously analyze resource utilization. Automatically scale down or pause idle or oversized compute clusters and virtual warehouses.
-
Reserved Instances and Savings Plans: For predictable, baseline workloads like daily ETL jobs, do not pay on-demand prices. Committing to reserved capacity with your cloud provider slashes compute costs by as much as 72%.
Adopting these practices transforms cost management from a monthly autopsy into a real-time optimization engine. It weaves cost awareness directly into your engineering culture.
Action Plan for Immediate Cost Control

Theory is done. It is time for action. This structured approach delivers immediate impact on your data pipeline costs.
Step 1: Audit Current Spend
Establish a clear baseline. Use the budget framework to perform a full audit of your current data stack spend. Line up actuals against benchmarks for cloud, platforms, and engineering. This exercise will immediately highlight your top three cost drivers and expose outliers that require urgent attention.
Step 2: Evaluate FinOps Maturity
Get your data and finance teams in a room for an honest assessment. Review your cost management practices against the FinOps strategies outlined above. Are you rightsizing resources or letting them run? Do you have showback? This discussion reveals the gaps between your current state and target state, creating a clear action plan. Explore advanced strategies for cost reduction using AI to accelerate your FinOps practice.
Step 3: Model Your Next Project’s TCO
Stop making budget requests based on gut feelings. For your next major data initiative, use the DataEngineeringCompanies.com cost calculator to model the Total Cost of Ownership (TCO). Plugging in your project specifics generates a defensible estimate that accounts for platform fees, engineering work, and contingency. This transforms your budget request from a wish list into a data-supported business plan.
These three steps bring immediate clarity to your spending, drive financial accountability, and enable smarter, faster decisions on all future data investments.
Data Pipeline Cost FAQs
These are the most common questions engineering leaders ask when tackling data pipeline costs.
How Much Should a Data Pipeline Cost?
There is no single number. The final cost depends on data volume, pipeline complexity, and the engineering team’s size and location. A typical mid-market company’s annual data pipeline cost is between $300,000 and $1.2 million.
The allocation is more important than the total. A healthy budget breaks down as follows:
- Engineering & Consulting: 40-60%
- Data Platform Licensing (Snowflake, Databricks): 15-25%
- Cloud Infrastructure (AWS, Azure, GCP): 15-20%
- Orchestration & Monitoring Tools: 5-10%
- Data Governance & Quality Tools: 5-10%
A drastically different allocation signals an imbalance that requires investigation.
What Is the Biggest Hidden Cost in Data Pipelines?
The biggest hidden cost is inefficient engineering. This is not a salary problem; it is a force multiplier that quietly inflates every other line item. It manifests as poorly designed architecture that burns cloud credits or teams spending hours on manual fixes instead of automation.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, talent is the largest cost driver. An inefficient team doesn’t just waste salary; they actively drive up platform and infrastructure spending through suboptimal work. This is why selecting the right high-performing engineering partner is the most critical financial decision you will make.
How Can I Justify the Cost of a New Data Pipeline?
Stop discussing cost; start discussing value. Frame the investment around Total Cost of Ownership (TCO) and Return on Investment (ROI). Connect the investment to specific business outcomes.
Frame your business case by answering these questions:
- What new revenue will this data unlock?
- What operational costs will be saved by automating manual reporting?
- What is the financial risk of making decisions with stale, inaccurate data?
When you demonstrate the pipeline is an engine for growth, not an IT expense, securing leadership buy-in becomes straightforward.
Stop guessing. Get clear, defensible numbers for your next data project. DataEngineeringCompanies.com provides transparent rate bands, detailed firm profiles, and a suite of tools to help you select the right data engineering partner with confidence. Find your expert match today.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A CTO's Guide to Ecommerce Data Engineering
Build a high-performance ecommerce data engineering architecture. Compare platforms, integration patterns, and vendor selection criteria for maximum ROI.

How to Hire an Apache Kafka Consulting Firm That Delivers
A guide for engineering leaders on scoping, vetting, and hiring the right Apache Kafka consulting partner. Learn to avoid pitfalls and maximize your ROI.

A CTO's Guide To Real-Time Data Pipeline Architecture
Build a winning real-time data pipeline architecture. This guide helps engineering leaders compare patterns, choose components, and select the right partner.