Data Engineering Staff Augmentation: A 2026 Playbook

The worst advice in data engineering staff augmentation is “just add engineers fast.” Speed matters. It isn’t the hard part.
The hard part is buying the right control model, locking down the contract before the first sprint, and forcing real integration into your architecture, governance, and delivery rituals. If you miss those three, you don’t gain the expected benefit. You get extra people, extra meetings, and extra failure modes.
That matters because the labor gap is real. There are nearly 2.9 million job openings worldwide for data-related roles, which is exactly why many teams use augmentation to fill specialized gaps without waiting through full hiring cycles, according to data engineering labor market statistics. But scarcity alone doesn’t justify the model. Plenty of teams use augmentation when they should buy managed delivery, or hire full-time, or pause until scope is stable.
If you’re evaluating a first major deal for Snowflake, Databricks, dbt, Airflow, AWS, Azure, or BigQuery work, treat this as a procurement and operating manual, not a talent article.
When to Choose Augmentation and When to Avoid It
Staff augmentation is not the default answer to every data platform problem. Use it when you want control of architecture and backlog but need outside specialists inside your team. Skip it when you need a vendor to own outcomes end to end.
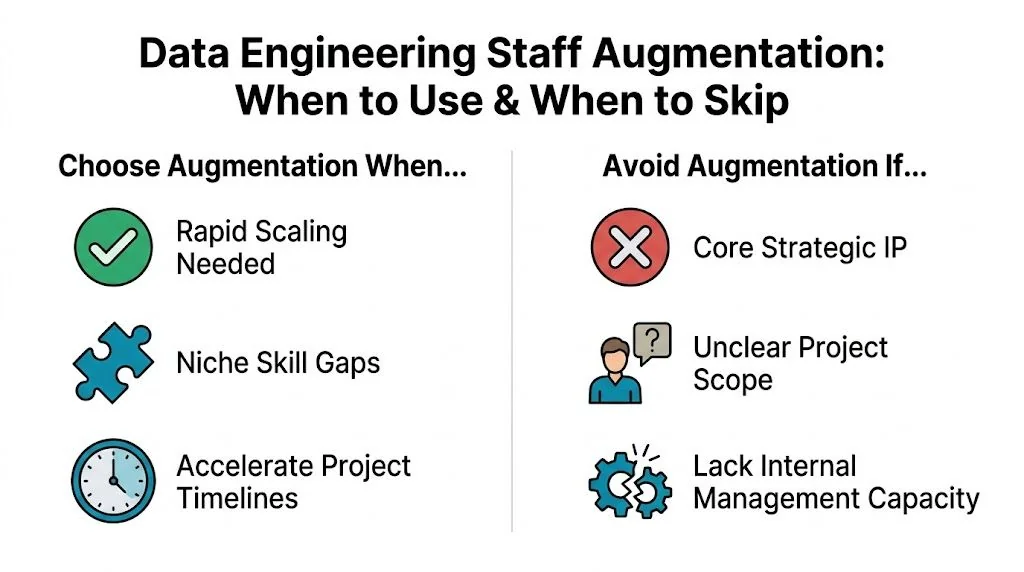
Choose augmentation for deadline-bound specialist work
Data engineering staff augmentation fits well when the work is clear, the deadline is real, and your internal leaders still want design authority.
Good examples:
- Snowflake or Databricks migration with a fixed target date. You already know the platform, have an internal owner, and need engineers who’ve done warehouse migration, ELT refactoring, dbt modeling, and orchestration in Airflow.
- Cloud modernization on AWS, Azure, or GCP. Your platform team knows the security model and cost controls, but lacks enough hands with Terraform, data lake patterns, or warehouse-specific tuning.
- Governance-heavy programs. You need temporary expertise for cataloging, lineage, access policy implementation, or audit preparation, but not a permanent bench of governance specialists.
- Backlog compression after architecture is set. Your staff architect already chose the stack. Now you need execution capacity.
If you already have a competent Head of Data, platform lead, or principal architect, augmentation gives you speed without surrendering the steering wheel.
Practical rule: If your team can write the first 20 tickets with clear acceptance criteria, augmentation is usually viable.
Avoid augmentation when ownership is the real problem
A lot of leaders claim they need more capacity. What they lack is product direction, architectural ownership, or stakeholder alignment.
Don’t use augmentation when:
- The target state is undefined. If you still haven’t decided between Snowflake and Databricks, or whether dbt belongs in the stack, external engineers will amplify indecision.
- The work includes core strategic IP that you won’t expose. If critical transformation logic, pricing models, or regulated decisioning systems can’t be shared cleanly, the engagement will stall.
- No internal manager can run the team. Augmented engineers need a real counterpart. If nobody owns backlog, review standards, and business tradeoffs, buy a managed service instead.
- You want a vendor to absorb delivery risk. Augmentation gives you labor and expertise. It does not transfer accountability in the same way a managed delivery contract does.
Teams often confuse augmentation with outsourcing. If you need a clean comparison, this breakdown of staff augmentation vs outsourcing is useful because it frames the decision around control and ownership rather than generic cost talk.
Use this decision lens
Here’s the simplest way I advise peers to decide.
| Model | Best fit | Bad fit | Who owns delivery |
|---|---|---|---|
| Staff augmentation | Clear backlog, internal architecture control, short-to-midterm specialist need | Undefined scope, weak internal management | You |
| Managed service | Need outcome ownership, cross-functional execution, lower management burden | Team wants deep day-to-day control of individuals | Vendor |
| Full-time hire | Long-term platform ownership, stable recurring need, culture-sensitive roles | Urgent deadline or rare niche skill needed briefly | You |
The test most buyers skip
Ask one uncomfortable question: What happens after month six?
If the answer is “they’ll keep owning the platform,” you probably don’t want augmentation. That’s a sign you need permanent hires or a managed model with explicit accountability. Augmentation works best as a force multiplier, not as a disguised replacement for internal leadership.
Buy augmentation for execution under your system. Don’t buy it to compensate for the absence of a system.
The RFP Playbook for Evaluating and Selecting a Partner
Most RFPs for data engineering staff augmentation are weak. They ask for resumes, rate cards, and generic platform logos. That’s how buyers end up choosing on price and regretting it later.
The selection criterion that matters most is embedded delivery fit. Data from Everest Group shows firms that prioritize it achieve 2.5x higher ROI, yet 70% of buyers select vendors based on rates alone, contributing to a project failure rate 15% higher than managed services, according to this analysis on data engineering augmentation partner selection.
What your RFP must force vendors to prove
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, the strongest evaluation process tests six things: platform depth, cloud implementation history, governance maturity, delivery integration, staffing realism, and commercial discipline.
If the vendor can’t answer these cleanly, they’re not ready for serious Snowflake, Databricks, dbt, Airflow, AWS, Azure, or BigQuery work.
| Evaluation Category | Criteria | What to Ask/Verify |
|---|---|---|
| Platform expertise | Hands-on delivery in Snowflake, Databricks, dbt, Airflow | Ask for named certifications, recent implementation examples, and who on the proposed team holds them |
| Cloud infrastructure | Depth in AWS, Azure, or GCP | Ask which cloud they’ve used for ingestion, orchestration, storage, IAM alignment, and observability |
| Data architecture | Pipeline design, medallion or warehouse patterns, transformation standards | Ask for a sample architecture decision log and how they choose between platform-native features and external tools |
| Governance and security | Access controls, lineage, audit readiness, data handling discipline | Ask how they work within your policies, who approves access, and what documentation they produce |
| Industry context | Experience in healthcare, fintech, retail, or enterprise environments | Ask for comparable environments, especially where data sensitivity or compliance shaped design choices |
| Embedded delivery fit | Ability to work as part of your team | Ask how they run standups, code reviews, incident response, and stakeholder communication |
| Staffing model | Seniority mix and replacement process | Ask who is actually assigned, who shadows them, and how quickly they replace a weak performer |
| Commercial terms | Rate transparency, ramp clauses, exit rights | Ask for notice periods, substitution terms, non-solicit language, and how unused capacity is handled |
Don’t ask for more case studies. Ask for operating evidence
Case studies are marketing. Delivery mechanics are real.
Your RFP should require responses to questions like these:
-
Who will review pull requests in week one?
If the answer is vague, they don’t know how to embed. -
What artifacts do you produce during architecture work?
You want decision logs, environment diagrams, lineage notes, test standards, and runbooks. -
How do you handle a mismatch between your preferred stack and ours?
Good partners adapt. Bad ones try to smuggle in their house style. -
What’s your replacement policy for an underperforming engineer?
This needs a contractual answer, not a relationship answer. -
How do you work inside our governance model?
This matters more than generic “security first” language.
For a broader procurement lens, some of the same evaluation discipline used in choosing an AI consulting firm applies here too. The common thread is simple: don’t buy logos, buy proof of delivery inside your constraints.
The shortlisting process I’d use
Use a three-stage filter.
Stage one screens for capability truth
Cut vendors that can’t show direct work in your actual stack. If you’re migrating to Snowflake with dbt and Airflow on AWS, don’t entertain a generic “cloud and data” pitch. Ask for the exact mix.
Stage two screens for team realism
Interview the proposed architect and at least one proposed engineer. Not sales. Not an account lead. The actual people.
Probe for specifics:
- dbt standards such as model layering, testing habits, and CI expectations
- Airflow discipline around retries, idempotency, and ownership of failed jobs
- Warehouse design choices in Snowflake, Databricks, or BigQuery
- Cloud controls for IAM, secrets handling, and environment separation
Stage three screens for operating fit
Run a working session. Give them a sanitized problem from your environment. Ask how they would structure discovery, identify risk, sequence delivery, and communicate tradeoffs.
That will tell you more than ten reference calls.
The vendor you want is the one that asks hard questions about your environment before talking about headcount.
For leaders building the process from scratch, this guide to RFP process best practices is a solid operational reference.
Benchmarking Rates and Sizing Your Augmented Team
Most buyers obsess over rates and ignore team shape. That’s backwards. A cheap team with the wrong mix burns time in architecture churn, code review delays, and platform mistakes.
The problem with this section is the market doesn’t give you clean, universal benchmarks you can trust across every role, geography, and platform. So be disciplined. Use rates as a screening tool, not as your decision model.

What should drive budget
Start with these cost drivers:
- Platform complexity. Snowflake migration and optimization work prices differently from generic SQL pipeline maintenance. Databricks plus lakehouse design shifts the profile again.
- Seniority concentration. One strong architect and a few execution-focused engineers beats a team full of expensive generalists.
- Governance load. If the work involves access design, audit requirements, lineage, or regulated data handling, expect heavier senior oversight.
- Time-zone overlap. If your team insists on deep overlap for standups, reviews, and incident handling, you’ll narrow the talent pool.
The broader market confirms why this buying pattern is accelerating. The global IT staff augmentation market was valued at USD 107.3 billion in 2024 and is projected to reach USD 200.6 billion by 2033, growing at a 7.5% CAGR, according to IT staff augmentation market data.
Team shapes that usually work
Don’t start with a giant pod. Start with the minimum team that can own architecture, delivery, and handoff.
For a warehouse modernization or migration, I’d usually want:
- One lead architect or principal engineer for target-state design, security alignment, and review standards
- Two to four data engineers for ingestion, transformation, testing, and orchestration
- Optional analytics engineer if dbt model quality and semantic consistency matter early
For a governance-heavy platform hardening effort:
- One senior platform or data architect
- One or two engineers focused on access patterns, lineage, policy implementation, and operational cleanup
- Strong internal security or governance counterpart, which cannot be outsourced in practice
For an initial ML data foundation effort:
- One senior data engineer who understands feature pipelines and production data quality
- One engineer for integration and orchestration
- Internal ML owner to define requirements and acceptance, because external engineers should not invent your model priorities
What to challenge in vendor proposals
Push back when you see:
- Too many leads. You’re funding meetings.
- No architect at all. Then your team is doing hidden architecture work anyway.
- A giant first-month ramp. That usually signals weak discovery discipline.
- A fully offshore team for high-collaboration migration work when your internal team is new to the platform.
If you want a current market reference point for commercial planning, this breakdown of data engineering consulting rates is worth reviewing alongside your shortlist.
Onboarding and Delivery Best Practices
Most staff augmentation failures happen after signature, not before. The vendor sold capability. Your operating model failed to absorb it.

Week one is about access and norms
In the first week, don’t chase output. Chase friction removal.
Your augmented engineers need working access to Git, Jira, cloud consoles, warehouse environments, dbt repos, orchestration tooling, monitoring, and communication channels. They also need your standards in writing: branching model, PR expectations, naming conventions, incident rules, and what “done” means.
Use a checklist.
- Tooling access. Grant only the minimum necessary permissions, but grant them fast.
- Architecture briefing. Walk through sources, pipelines, warehouses, transformation layers, and known pain points.
- Team rituals. Explain standups, escalation paths, review etiquette, and response-time expectations.
- Delivery scope. Define what they own now, what they influence, and what stays internal.
If an engineer spends the first five business days waiting for permissions, that’s your failure, not theirs.
Week two is about productive integration
By week two, they should be inside the actual work. Not in a sandbox forever.
Good onboarding means they take on contained tasks that expose the core system: one ingestion path, one dbt model family, one Airflow DAG group, one warehouse optimization issue. You want them to learn your environment while shipping useful work.
A good manager also pairs them with internal peers for code review and design discussion. That cuts the “external team” dynamic before it starts.
This walkthrough is worth sharing with internal managers before kickoff:
The first 30 days need visible operating rhythm
By day 30, I expect four things:
- The team works in the same backlog and sprint rhythm
- PRs follow internal standards without constant correction
- Architecture decisions are documented, not trapped in calls
- Leads can name delivery risks without asking the vendor to summarize reality
Use a simple cadence:
- Daily for engineering sync
- Weekly for stakeholder review and risk log
- Biweekly for architecture and governance review
- Monthly for commercial and performance review
Don’t let the vendor run a parallel reporting system. One team, one board, one definition of status.
Governance KPIs and Mitigating Critical Risks
If you can’t govern the engagement, don’t start it. Data engineering staff augmentation touches architecture, access, infrastructure, and business-critical data flows. That means bad contracts and weak oversight become operational risk fast.

The risk is not theoretical. Amid tighter regulation such as the EU AI Act, 42% of data engineering augmentations face integration delays and compliance issues that erode 18% of projected cost savings, according to data engineering augmentation risk analysis.
Track operational value, not just activity
Story points are not governance. Hours billed are not governance. Track indicators that tell you whether the team is improving the platform you run.
I’d monitor:
- Pipeline reliability. Are scheduled runs stable, recoverable, and understood?
- Change failure pattern. Which releases break pipelines, models, or permissions?
- Review quality. How many PRs need rework for standards, test coverage, or architectural mismatch?
- Documentation completeness. Are runbooks, lineage notes, and decision records being produced as work happens?
- Knowledge transfer evidence. Can your internal team operate what the vendor built?
Use a monthly scorecard, but keep it operational. If a metric doesn’t drive a management action, drop it.
Contract clauses that separate good deals from bad ones
A proper SOW for data engineering work needs more than rate cards and names.
Non-negotiables:
- IP assignment. All code, models, documentation, workflows, and architecture artifacts produced under the engagement belong to you.
- Data handling rules. Spell out access boundaries, storage restrictions, logging expectations, and approved tools.
- Named resources and substitution limits. Don’t let the vendor swap people casually.
- Right to replace. You need a clean path to remove a weak engineer quickly.
- Documentation obligations. Tie payment or milestone acceptance to artifacts, not just labor.
- Exit support. Require structured handoff, repo hygiene, and transition assistance.
Contract rule: If knowledge transfer is not written into the SOW, it will be postponed until the last week, then done badly.
The red flags I’d treat seriously
Walk away if you hear any of these:
- “We’ll adapt governance as we go.”
- “Our senior architect can float across multiple clients.”
- “We usually use our own internal tooling for visibility.”
- “Let’s finalize replacement terms later.”
- “Access can be broad at first and tightened later.”
That language tells you the vendor wants convenience. You need control.
From Augmentation to Lasting Capability
The right outcome isn’t a long vendor dependency. It’s a stronger internal data engineering function.
Use external specialists to accelerate a migration, harden governance, stand up dbt standards, or modernize orchestration. Then convert what they built into internal muscle. That means named internal owners, shadowing during delivery, architecture records that survive turnover, and explicit handoff checkpoints before the contract ends.
If I were starting this process tomorrow, I’d take three actions this week:
- Decide the model objectively. If you need ownership, buy managed delivery. If you need execution under your direction, buy augmentation.
- Rewrite the RFP around embedded delivery fit. Force vendors to prove they can work inside your stack, cloud, and governance model.
- Lock in onboarding and exit terms before signature. Most pain comes from weak integration and weak handoff, not weak resumes.
If you want to move from theory to execution, use DataEngineeringCompanies.com’s vendor shortlist tools, RFP checklist, and platform comparison resources to pressure-test your shortlist and tighten your procurement process before you sign.
Ready to evaluate partners with less guesswork? Start with DataEngineeringCompanies.com to compare firms by platform, industry, capabilities, and commercial fit, then use its RFP checklist and shortlist tools to run a tighter data engineering staff augmentation process.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

Data Lakehouse vs Data Mesh: A 2026 Decision Guide
Choose the right architecture for your enterprise. A detailed comparison of data lakehouse vs data mesh on cost, governance, performance, and vendor selection.

Data Reliability Engineering A Guide for CTOs
Learn what Data Reliability Engineering (DRE) is, why it matters, and how to implement it. A complete guide for leaders evaluating data engineering partners.

Fivetran vs Airbyte: An Enterprise TCO Analysis for 2026
Choosing between Fivetran vs Airbyte? This enterprise guide analyzes TCO, reliability, and connector quality to help you decide beyond the feature list.