Strategic Data Engineering ROI Measurement for CTOs

Most ROI discussions around data engineering collapse the minute a CFO asks a simple question: what exactly are we buying, when do we get payback, and how do we know the consultancy caused it?
If your answer is “better data foundations,” you don’t have a business case. You have a technical preference.
For a multi-million dollar Snowflake, Databricks, dbt, or Airflow modernization, data engineering ROI measurement has to do three jobs at once. It has to justify spend, govern delivery, and protect you during vendor selection. If it only does the first, the project drifts. If it only does the second, finance won’t fund it. If it ignores the third, you’ll over-credit the consultancy and under-manage your own team’s role.
Your CFO Asks for the ROI on Data Engineering What’s Your Answer
Most CTOs answer this question backwards. They start with architecture. The CFO cares about economics, risk, and timing.
A real answer sounds like this: we’re investing to cut manual engineering effort, reduce downtime and data trust failures, and speed up business decisions that are currently blocked by stale or unreliable pipelines. Then you quantify each one.
That’s the difference between a funded platform program and a “phase zero” that never scales.
Why standard IT ROI logic fails
Traditional infrastructure ROI models focus on hard cost takeout. That’s too narrow for data engineering. A migration from legacy ETL to modern cloud data pipelines on Snowflake, Databricks, BigQuery, or Azure isn’t just a hosting change. It changes transformation speed, reliability, governance, developer workflow, and the speed at which business teams can act on data.
That’s why vendor-sponsored and practitioner-backed benchmarks matter. A Nucleus Research study reported that customers of a leading ETL platform achieved 328% three-year ROI with a 4.2-month payback period, driven by 30-50% faster data transformations and error reduction that saved organizations an estimated $12.9 million annually (Integrate.io ETL ROI benchmarks).
That does not mean your project gets the same result. It means your finance narrative should be anchored in measurable operational changes, not generic modernization language.
Practical rule: If your business case doesn’t show baseline pain, target metrics, owners, and a payback path, finance will treat it as discretionary spend.
Build the business case before the architecture deck
Before you debate Databricks versus Snowflake, or dbt versus in-platform SQL, put the economics into a structure your executive peers can review. A clean format like WeekBlast’s business case template helps because it forces explicit assumptions, options, costs, risks, and ownership.
Use it to answer five essential questions:
- What is broken now: Manual rework, slow transformations, unreliable pipelines, weak lineage, duplicated metrics.
- What changes in the target state: Automated orchestration, testable transformations, clearer ownership, lower latency, stronger governance.
- Who benefits: Data engineering, analytics, finance, operations, and executive decision-makers.
- How value shows up: Labor savings, fewer incidents, faster decisions, reduced bad-data exposure, better AI/ML readiness.
- How you’ll prove it: A baseline and review cadence tied to named KPIs.
If you can’t explain ROI in those terms, don’t issue the RFP yet.
Beyond Cost Savings The Three Layers of Data Engineering ROI
A strong ROI model has three layers. If you only present one, the case looks weak.
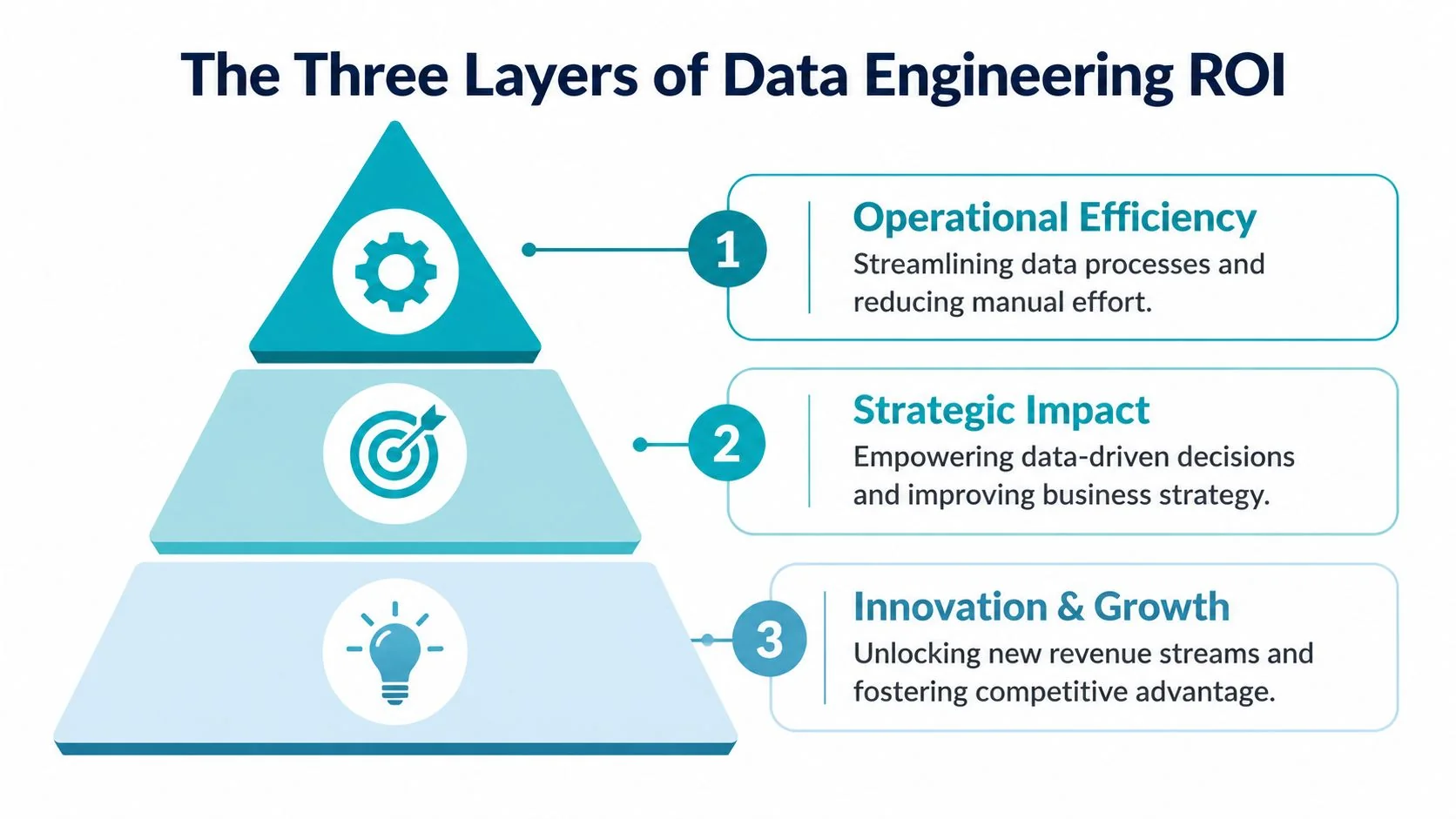
Operational efficiency
This is the floor. It covers the obvious gains from better pipeline architecture, orchestration, and transformation practices.
Think about what changes when a consultancy replaces brittle legacy ETL with well-structured dbt models, Airflow orchestration, and cloud-native storage and compute. Engineers spend less time patching jobs. Analysts wait less. Teams stop rebuilding the same logic in multiple places.
The strongest benchmark here comes from modern analytics engineering. A Forrester Consulting Total Economic Impact study commissioned by dbt Labs found 194% ROI with breakeven within the first six months, tied to improvements in developer productivity, data quality, and collaboration efficiency (dbt Labs analytics ROI research).
Operational efficiency is the easiest layer to model because it maps directly to labor and support effort. It’s also the weakest layer to lead with if you’re asking for a large modernization budget. Cost savings alone rarely justify a platform shift.
Strategic impact
At this point, the business case becomes credible.
Strategic impact sits between engineering output and executive value. It includes lower data latency, more reliable reporting, faster issue resolution, and greater confidence in planning, pricing, supply chain, or growth decisions. The point isn’t “our pipelines are better.” The point is “leaders stop making decisions on stale or suspect data.”
A data platform earns executive support when it changes decision velocity, not when it merely improves architecture hygiene.
This layer is what connects platform work to planning cycles, operating cadence, and cross-functional trust. It’s also where governance belongs. Governance isn’t compliance theater. It’s what lets finance, operations, and product teams use the same numbers without relitigating definitions every week.
Innovation and growth
This is the top layer. Organizations frequently mention it too early and too vaguely.
Innovation and growth value appears when your platform supports new data products, AI/ML workloads, experimentation, and reusable data assets across teams. That’s the upside a CEO cares about, but it only becomes believable if the bottom two layers are already quantified.
A consultancy pitching “AI readiness” without a measurable plan for pipeline reliability, lineage, and transformation quality is selling aspiration. Don’t buy aspiration.
How to use the three-layer model in executive conversations
Use the layers to separate benefits by audience:
| Executive audience | ROI layer they care about most | What to show |
|---|---|---|
| CFO | Operational efficiency | Labor savings, reduced manual processing, payback timing |
| COO | Strategic impact | Better reliability, lower latency, fewer reporting disruptions |
| CEO or BU leader | Innovation and growth | Faster launch of analytics and AI-enabled use cases |
A consultancy should map its proposal to all three. If it only talks about engineering velocity, it’s underselling the work. If it only talks about transformation and AI, it’s hiding execution risk.
The KPI Toolkit Connecting Engineering Metrics to Business Value
The fastest way to ruin data engineering ROI measurement is to track only financial outputs. You need operating KPIs that move before the money shows up. Otherwise, you’ll discover failure after the budget is spent.
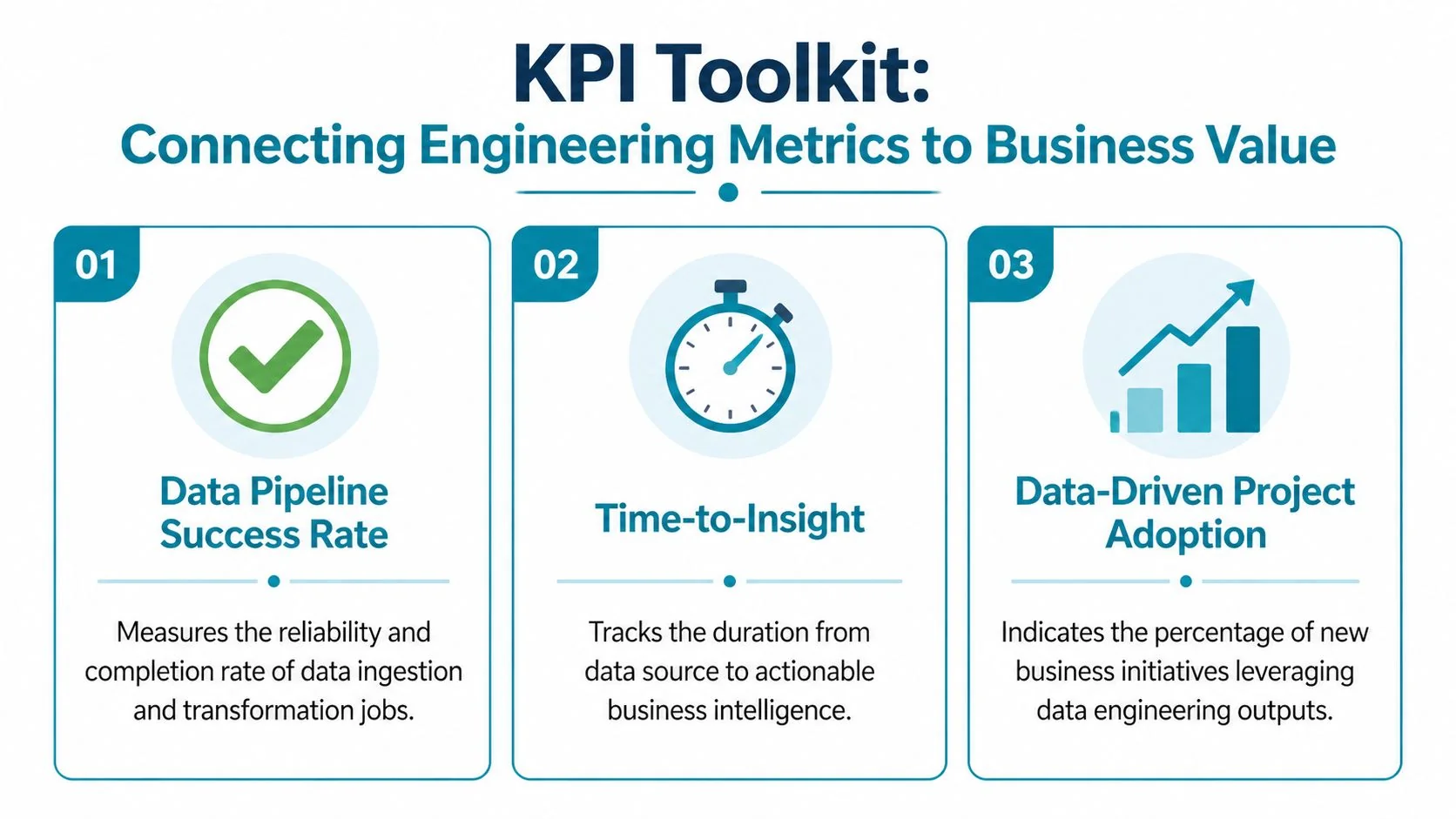
Efficiency KPIs that finance can understand
For platform modernization, I’d start with a small set of operational KPIs and refuse to let the vendor bury them under vanity dashboards.
Track these before the engagement starts:
- Transformation cycle time: How long it takes to build, test, and release a production-ready transformation.
- Manual intervention load: How often engineers step in to rerun jobs, fix schemas, backfill data, or reconcile outputs.
- Support burden: The volume and type of data-related support work created by pipeline failures or broken definitions.
- Delivery throughput: The speed at which the team ships trusted data assets to downstream analytics users.
If you want a useful parallel for measuring the human side of engineering output, this piece on modern approaches to developer productivity is worth reading. The core lesson applies directly here: measure flow and friction, not just raw activity.
Latency is a business KPI, not a plumbing KPI
Most engineering teams understate the value of latency. They treat it as a technical improvement. It’s not. It directly affects decision speed.
Benchmarks show that reducing latency from 24 hours to under 12 hours can yield 20-50% faster strategic decisions, and high-latency systems can cause losses averaging $100K-$500K annually per delayed campaign in mid-market firms (JadaSquad on data engineering ROI metrics).
That gives you a practical way to position latency KPIs:
| KPI | Definition | Business translation |
|---|---|---|
| Data latency | Time from source event to analytical availability | Decision speed |
| SLA adherence | Whether critical datasets arrive on time | Planning reliability |
| Time-to-insight | Time from business question to trusted answer | Commercial responsiveness |
For a retail or fintech stack, that may mean campaign optimization or fraud analysis. For enterprise finance, it may mean faster variance analysis or more credible forecasting. The metric is technical. The value is operational.
Don’t report latency as “pipeline freshness.” Report it as the delay between an event and an executive action.
Reliability KPIs separate serious vendors from slideware
Operational execution determines whether Snowflake, Databricks, Airflow, Kafka, and dbt implementations succeed or fail. If pipelines break constantly, the rest of the ROI model is fiction.
Monitor:
- Pipeline success rate: Percentage of scheduled jobs completing without failure.
- Incident frequency: How often critical pipelines break in a reporting period.
- Time-to-Recovery: How long it takes the team to restore service after a failure.
- Rework load: Engineering and analyst time spent fixing downstream consequences of upstream issues.
These KPIs matter because they expose whether the consultancy is building an operable platform or just delivering initial migration scope.
Governance and adoption KPIs prove the platform is being used
A technically elegant platform with poor adoption has weak returns.
Use governance and adoption measures such as:
- Certified data asset usage: Whether business teams consume governed models and dashboards.
- Metric consistency: Whether teams rely on standardized definitions instead of local spreadsheet logic.
- Lineage coverage: Whether critical datasets can be traced back to source and transformation logic.
- New use-case activation: How quickly a new reporting, analytics, or AI need can move onto the platform.
A sane KPI rule set
Keep the scorecard tight.
- Use a baseline: Measure before consultants touch the stack.
- Tie each KPI to an owner: Finance owns cost assumptions. Engineering owns reliability. Business teams validate adoption.
- Track leading and lagging indicators: TTR and latency move before revenue or cost outcomes.
- Review monthly, not only at the steering committee: ROI drift starts in operating metrics.
The Data Engineering ROI Calculation Template
A bulletproof model is simple enough for finance to audit and detailed enough for engineering to defend. Start with the standard ROI formula already used in ETL modernization analysis: (Net Benefits / Total Costs) × 100. Then make the inputs rigorous.
Step one baseline the current state
Capture the current operating reality before vendor selection. Not after kickoff. Before.
You need baseline values for effort, incidents, latency, support burden, and trust issues. Reliability matters here because poor reliability creates real productivity loss. Poor reliability, such as 5-10% weekly pipeline breakages, links to 15-25% productivity loss, equating to over $250K in annual downtime costs for a 500-person data team, and reducing TTR from hours to minutes can yield 4x faster triage (Coalesce on data team ROI metrics).
Step two convert engineering improvements into monetary value
Weak business cases usually fail at this critical juncture. They stop at “faster pipelines” instead of converting outcomes into money.
Use three buckets:
-
Efficiency benefits
Translate lower manual effort and fewer support tickets into labor savings or capacity released for higher-value work. -
Risk reduction benefits
Quantify avoided downtime, avoided rework, and lower exposure to bad-data decisions. -
Enablement benefits
Value faster delivery of dashboards, models, and analytics use cases by tying them to documented business dependencies.
Operator advice: If a benefit can’t be tied to a baseline metric and an owner, exclude it from the core ROI case and keep it as upside.
Step three price the full investment
Count all costs, not just consultancy fees.
Include platform licenses, cloud consumption, migration effort, internal engineering time, training, observability tooling, governance work, and post-go-live stabilization. If you ignore internal time, your model will look good and be wrong.
For teams building reusable tracking into client programs, the discipline used to track client AI automation ROI is a useful reference point. The principle is the same here: define value events, assign ownership, and review actuals against the model from the start.
Step four model year by year
Use a worksheet that finance and procurement can inspect.
| Metric | Formula / Source | Year 1 Value | Year 2 Value | Year 3 Value |
|---|---|---|---|---|
| Efficiency benefits | Baseline engineering and analyst effort reduced after modernization | |||
| Reliability benefits | Downtime and rework avoided based on incident reduction and faster recovery | |||
| Latency benefits | Value from faster decisions on critical workflows | |||
| Governance and trust benefits | Avoided reconciliation effort and reduced bad-data exposure | |||
| Total benefits | Sum of all benefit categories | |||
| Consultancy cost | SOW fees and retained support | |||
| Technology cost | Platform, tooling, and cloud spend | |||
| Internal cost | Staff time, change management, training | |||
| Total costs | Sum of all investment categories | |||
| Net benefits | Total benefits less total costs | |||
| ROI | (Net Benefits / Total Costs) × 100 |
Step five force a payback discussion
Your CFO will ask two things after ROI: when do we break even, and what would cause us to miss?
Answer both in writing. Then tie the risk factors to delivery controls such as stage gates, KPI reviews, and acceptance criteria in the SOW.
The Attribution Problem Isolating Consultancy ROI
Clients over-credit the consultancy when a modernization works and over-blame it when one stalls. Both are lazy. Attribution has to be designed into the engagement.

Why attribution breaks down
In real programs, outcomes come from mixed inputs. The consultancy redesigns pipelines. Your internal team cleans up governance. A platform vendor changes pricing or features. Business teams improve adoption. Then everyone argues about who delivered the return.
An Everest Group report notes that 68% of mid-market firms using external data engineering partners struggle with ROI attribution, leading to a 25-40% overestimation of vendor impact. Without contract-embedded ROI trackers, buyers risk misallocating budgets (Elder Research discussion of data engineering pitfalls and attribution issues).
That should change how you write every SOW.
What to put in the contract
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, top-quartile consultancies proactively define attribution models in their proposals, reducing client-side uncertainty by over 40%.
Require these elements:
- Named KPI ownership: State which KPI the consultancy influences directly, which KPI your internal team owns, and which KPI is shared.
- Pilot-based attribution: Use a scoped migration, pipeline domain, or business unit as a controlled proof point before wider rollout.
- Pre and post baselines: Freeze the baseline period before implementation starts.
- Exclusion logic: Identify benefits that shouldn’t be credited to the vendor, such as parallel internal governance changes or business process redesign.
If attribution isn’t written into the contract, the vendor will still talk about ROI. You just won’t be able to verify whose ROI it is.
The simplest attribution model that works
Use a three-part split:
| Contribution area | Primary owner | How to evaluate |
|---|---|---|
| Platform implementation | Consultancy | Delivery against scope, reliability, latency, migration quality |
| Operating model and governance adoption | Internal team | Stewardship, process discipline, metric consistency |
| Business uptake | Shared | Adoption of outputs, use-case activation, stakeholder usage |
That model won’t make attribution perfect. It makes it governable. That’s enough.
Quantifying Negative ROI from Data Downtime and Trust Gaps
Most ROI models are too optimistic because they count delivered features and ignore whether anyone trusts the data after go-live.

A migration can hit scope, go live on time, and still destroy value if schema drift, broken lineage, unstable jobs, or weak quality controls force teams back into manual validation. That’s negative ROI in practice, even if the PowerPoint says the platform is “live.”
Trust-adjusted ROI is the model most teams skip
Gartner’s Q3 2025 DataOps survey found that 62% of cloud platform modernizations yield negative ROI in Year 1 due to untrusted data, averaging $1.2M in losses from delayed decisions. The formula for trust-adjusted ROI is (Value - (Investment + Downtime Cost)) / Investment (Domo glossary coverage of data analytics ROI and trust-adjusted ROI).
That formula matters because it forces you to subtract the cost of instability and distrust, not just implementation spend.
Three trust killers show up constantly in consulting proposals:
- Weak observability: No serious plan for freshness, schema, volume, and lineage monitoring.
- Thin governance design: Ownership and certification get deferred until after migration.
- Success defined as cutover: The vendor treats data moved as value delivered.
For a deeper operating view, review this guide to data reliability engineering. Reliability isn’t an add-on. It’s the control layer that protects ROI after launch.
How to price downtime and trust gaps
Use a simple challenge test during procurement.
Ask every consultancy to show:
- how it will detect broken pipelines,
- how it will surface data quality regressions,
- who responds to incidents,
- how business users will know a dataset is trusted,
- what happens to KPI reporting when a critical dependency fails.
If the answer is vague, your ROI model is inflated.
A platform with low trust has two costs. The first is direct rework. The second is that business teams stop using it and rebuild workarounds outside your controls.
A short explainer is worth watching if your executive team still treats downtime as an IT uptime issue rather than a decision-quality issue.
Red flags that belong in every vendor review
Don’t approve a consultancy proposal if it lacks:
- A production observability plan
- Lineage and ownership definitions for critical data products
- Runbooks for incident response and recovery
- Post-go-live trust metrics
- A method for tracking negative ROI drivers alongside positive gains
If those items are missing, the model is incomplete and the spend is harder to defend.
From ROI Model to RFP Your Action Plan
A good ROI model doesn’t sit in a finance deck. It becomes the backbone of the RFP, the SOW, and the steering committee.
Use this action plan before you engage a consultancy:
- Define the business case in three layers: Separate efficiency, strategic impact, and innovation benefits so each executive stakeholder sees the value relevant to them.
- Baseline the operating KPIs now: Capture latency, reliability, support burden, trust issues, and delivery speed before procurement begins.
- Embed attribution into the SOW: Require named KPI ownership, pilot-based proof points, and exclusion logic for benefits driven by internal work.
- Use trust-adjusted ROI, not headline ROI: Subtract downtime and trust failures from the value model.
- Make reliability part of vendor evaluation: Treat observability, lineage, incident response, and governance design as commercial requirements, not technical extras.
For rate planning and budgeting, use this benchmark on data engineering consulting rates for 2026. It helps procurement pressure-test whether the economics of a proposal line up with the expected return.
Your next move is straightforward. Build the ROI model before you shortlist vendors. Then force every consultancy to respond to that model, not to a generic migration brief.
That’s where DataEngineeringCompanies.com becomes useful. Use it to compare firms, pressure-test capabilities, and tighten your shortlist with more discipline before the RFP goes out.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A Practical Guide to Hiring Data Governance Consultants
Hiring data governance consultants? This guide unpacks their roles, costs, and selection criteria to help you find the right partner for your modern data stack.

Business Intelligence Consulting Services: A Practical Guide
Discover business intelligence consulting services that fit your goals. Learn how to choose the right partner and maximize ROI.

Data Governance vs. Data Management: A Practical Comparison
Understand the critical differences in the data governance vs data management debate. Learn how to align strategy and operations for a modern data platform.