Data Contracts in Data Engineering: A Guide for Engineering Leaders

Broken dashboards, unreliable ML models, and eroding trust from business leaders are symptoms of a deeper problem: bad data flowing unchecked through your pipelines. These failures are not inevitable; they are the direct result of a lack of clear agreements between data producers and consumers.
Data contracts in data engineering solve this by creating enforceable, API-like agreements that guarantee data quality before it can disrupt downstream systems. For engineering leaders, implementing data contracts is the most direct way to stop firefighting data quality issues and shift your team’s focus back to building value.
The Root Cause of Data Pipeline Failures
The problem originates in how modern engineering organizations are structured. Autonomous teams are incentivized to ship code and optimize their own services, often with zero visibility into who uses the data their applications generate. An application owner renames a field, changes an enum value, or alters a data type, and is completely unaware they have broken a critical financial report.
This forces your data team into a reactive, defensive posture. They spend their cycles diagnosing upstream changes instead of delivering new analytics and AI/ML capabilities. The data platform, intended to be a strategic asset, becomes a source of recurring, high-cost maintenance.
If your data pipelines consistently break, your data ecosystem is not producing trusted data. It is enabling teams to ship code without accountability, with data failures as an acceptable externality.
Without a formal agreement, every application dependent on that data—from a dashboard in Tableau to a model in Databricks—is vulnerable to unannounced, breaking changes.
The Quantifiable Cost of Unreliable Data
This instability carries direct financial consequences beyond wasted engineering effort.
- Eroded Business Trust: When executives cannot rely on the data presented, they lose faith in the data team and the expensive platform investments made.
- Wasted Engineering Spend: According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, data teams spend up to 40% of their time resolving data quality fires. This represents a massive productivity and salary sink.
- Delayed Project ROI: High-value analytics and AI initiatives stall because foundational data is untrustworthy, directly delaying time-to-market for revenue-generating projects.
- Compliance and Financial Risk: Inaccurate data in financial reporting or regulated domains (e.g., GDPR, CCPA) exposes the business to significant fines and legal jeopardy.
Data contracts break this cycle by shifting accountability for data quality upstream to the source. This transforms data from a fragile byproduct into a reliable, documented data product.
The Anatomy of an Enforceable Data Contract
A data contract is a machine-readable, enforceable agreement that defines the structure, semantics, and quality expectations for a data asset. It is not a Word document; it is a formal specification, much like designing a clear API contract in software engineering.
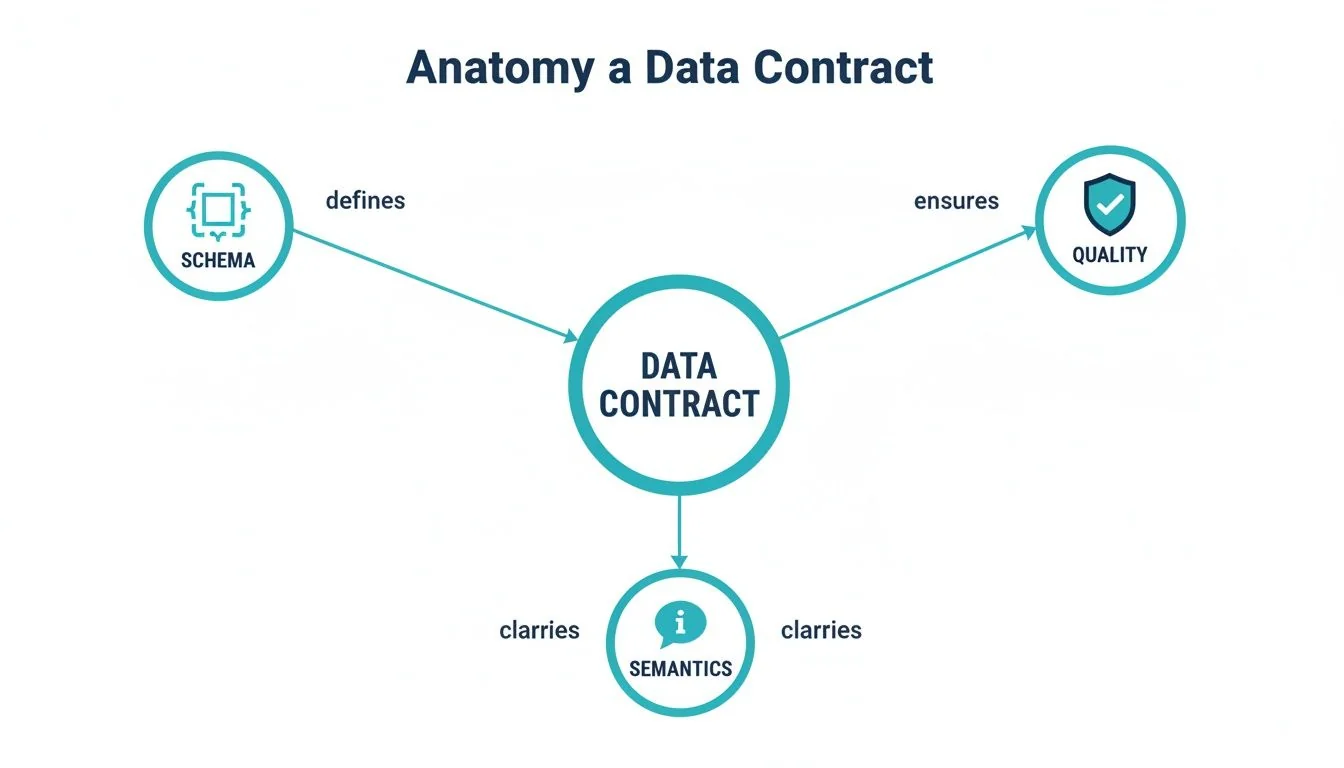
To be effective, a data contract must include several key components that establish a source of truth between producers and consumers.
Core Structural and Semantic Components
These elements form the foundation of the agreement and prevent the most common breaking changes.
- Schema Definition: The blueprint of the data. It defines field names, data types (
string,integer,timestamp), and structure. This is what stopscustomer_idfrom changing from an integer to a string, breaking every downstream query. - Semantic Guarantees: Defines the business meaning of the data. For example, a
statusfield is not just a string; it must be one of['active', 'inactive', 'pending']. These rules catch logical errors that a simple schema check would miss.
Operational and Quality Guarantees
Beyond structure, a robust contract specifies operational behavior and codifies reliability into measurable targets.
An enforceable data contract transforms vague promises into measurable commitments. It is the difference between “the data should be fresh” and “this dataset is guaranteed to be updated by 6 AM UTC with less than a 1% null rate on critical fields.”
Key operational components include:
- Data Quality Metrics: Explicit thresholds are written into the contract. Examples include freshness (data is no more than 60 minutes old), completeness (the
emailfield is non-null in at least 99% of records), or validity (acountry_codemust be a valid ISO 3166-1 alpha-2 code). - Service Level Agreements (SLAs): Performance expectations for data delivery, such as latency guarantees or uptime commitments for the data asset.
- Evolution Protocol: Defines a clear process for managing change, including versioning strategies, deprecation policies for old fields, and rules for backward compatibility. This prevents uncontrolled evolution.
With demand for data engineers projected to outpace supply, as detailed in these data engineering statistics, data contracts serve as an automated line of defense. They prevent the pipeline failures that plague projects lacking these formal specifications.
Architectural Patterns for Data Contract Enforcement
Defining a contract is insufficient; enforcement must be automated within your architecture. Without it, a contract is just documentation that will become outdated. The goal is to weave checks directly into the engineering workflow, making it impossible to ship data that violates the agreement.
The optimal enforcement strategy depends on your technology stack (e.g., Snowflake, Databricks), team topology, and control over data sources.
Producer-Side Enforcement
This is the most proactive approach. It validates data before it leaves the source system, catching issues at the point of origin. Enforcement happens within the producer’s CI/CD pipeline. When a developer commits a code change that would violate a data contract (e.g., altering a column’s data type), the build fails and the deployment is blocked.
- Pros: Prevents bad data from ever entering the ecosystem. Provides immediate feedback to developers. Reduces the monitoring burden on downstream teams.
- Cons: Requires buy-in from application engineering teams. Can introduce friction to their workflow if not implemented as a low-effort, automated check.
Consumer-Side Assertions
Here, the data consumer runs validation checks upon data arrival. This is a defensive posture used to protect downstream processes. If incoming data fails validation, the consumer can reject the batch, quarantine it, or trigger an alert.
This pattern is necessary when consumers have no control over producers, such as when ingesting data from a third-party API. Tools like dbt and Great Expectations are excellent for implementing these checks within a data warehouse or transformation layer.
This approach empowers consumers to protect themselves, but it is fundamentally reactive. The bad data has already been produced and transported, forcing the consumer to spend resources identifying and handling it.
Regardless of the pattern, effective enforcement requires robust data observability. Real-time monitoring of contract adherence helps teams track compliance and quickly diagnose the root cause of failures.
How to Implement Data Contracts
Implementing data contracts is a workflow change, not a single tool purchase. It’s about shifting quality control upstream. The two primary implementation models are contracts-as-code and a registry-driven model.
The contracts-as-code approach integrates validation rules directly into existing data pipelines and CI/CD processes. This is a natural fit for teams that treat their infrastructure as code. Using dbt tests or Great Expectations checkpoints within a Git-based workflow are prime examples.
A registry-driven model uses a centralized service, like Confluent Schema Registry for Kafka or a dedicated data contract platform, to store, version, and enforce contracts. This decouples producers from consumers and acts as a single source of truth, making it ideal for complex microservices or data mesh architectures.
Data Contract Implementation Tooling Comparison
The right choice depends on your existing stack, team structure, and primary use case. This table compares common approaches for implementing data contracts.
| Approach / Tool | Primary Enforcement Point | Best For | Integration Complexity | Cost Model |
|---|---|---|---|---|
| dbt Tests | In-warehouse, post-load | Teams using dbt for transformations in Snowflake or Databricks | Low (within dbt ecosystem) | Open-source (compute costs apply) |
| Great Expectations | CI/CD pipeline or orchestration | Validating data at multiple stages (pre-ingest, post-transform) | Medium (requires Python/CLI integration) | Open-source |
| Schema Registries | Producer-side (e.g., Kafka) | Real-time event streams and microservices | Medium to High (requires client library integration) | Varies (open-source or managed service) |
| Commercial Platforms | Centralized gateway & producers | Enterprises needing a unified governance layer across multiple systems | High (platform integration) | Subscription (SaaS) |
No single tool is a silver bullet. The most successful implementations blend approaches: a schema registry for event streams and dbt tests for analytical models. The goal is to make compliance the path of least resistance for developers.
Based on DataEngineeringCompanies.com’s analysis of 86 data engineering firms, projects that combine producer-side schema validation with in-warehouse assertions reduce data quality incidents by over 60%. A layered strategy provides defense-in-depth, catching issues at the source and just before consumption. Mastering data integration best practices is key to making the right architectural decision.
Building the Business Case for Data Contracts

Securing executive buy-in for data contracts requires framing them as a strategic investment with measurable ROI, not a technical exercise.
Start with engineering efficiency. Analysis of 86 firms shows data teams spend up to 40% of their time debugging bad data—a significant hidden cost. Data contracts automate the prevention of common errors, reclaiming that time and allowing your most expensive technical talent to focus on innovation instead of repair.
Quantifying the Financial Impact
Data contracts generate tangible ROI through several mechanisms:
- Accelerated Time-to-Value: Trustworthy data eliminates the “data cleanup” phase that stalls most analytics and AI projects. This directly shortens the time-to-market for new revenue-generating initiatives.
- Reduced Compliance Risk: An auditable, contract-based framework for data provides a clear system for governance. This lowers the risk of expensive fines related to regulations like GDPR, as detailed in our guide to data governance best practices.
- Improved Talent Retention: Chronic data quality fire drills and inter-team finger-pointing lead to burnout. Data contracts create clear ownership and reduce friction, improving job satisfaction and lowering costly employee turnover.
Market data supports this imperative. The Big Data Engineering Services market is projected to hit USD 187.19 billion by 2030, with a significant portion tied to data integration—the very domain that relies on stable contracts. As this in-depth industry report highlights, with the majority of data deployments now in the cloud, a formal, contract-driven framework is essential for managing complexity and risk.
The business case is straightforward: you can either invest proactively in data contracts or continue paying the compounding tax of unreliable data through project delays, wasted salaries, and missed opportunities. Data contracts shift your spend from reactive repairs to strategic enablement.
By framing the discussion around these outcomes, you demonstrate that data contracts are not a cost center but a direct investment in operational efficiency, reliability, and profitability.
Frequently Asked Questions About Data Contracts
Here are direct answers to the most common questions from engineering leaders about implementing data contracts.
What Is the Difference Between a Data Contract and a Schema Registry?
A schema registry is a tool; a data contract is the complete agreement.
A schema registry, such as the one from Confluent, defines and enforces the structure of data—field names and data types. It is the blueprint.
A data contract is the full service-level agreement. It includes the schema but also adds guarantees for data quality (e.g., null rates), semantics (e.g., allowed enum values), and operational SLAs (e.g., freshness). A contract is the complete set of expectations; a schema registry enforces only one part of it.
How Do Data Contracts Fit into a Data Mesh Architecture?
Data contracts are the enabling technology for a data mesh.
A data mesh architecture treats data as a product, with decentralized teams owning their respective data domains. For this distributed model to function, there must be a standard for how these data products are defined, versioned, and guaranteed.
Data contracts provide that standard. They are the formal, enforceable interface for a data product, defining its quality, reliability, and meaning. It is the mechanism that allows dozens of teams to build and consume data products independently without creating chaos.
What Is the Best First Step in a Legacy Environment?
Do not attempt a “big bang” implementation across all legacy systems. Start with a single, high-value, high-pain use case.
Identify a critical business process that frequently fails due to data issues—a key executive dashboard, a customer-facing ML model, or a regulatory report. This is your pilot project.
Work with the consumers of that data to define a consumer-driven contract. Enforce this contract on the consumer side using tools they already have, such as dbt tests or Great Expectations checkpoints. This delivers an immediate win by stabilizing a critical asset and creates a powerful success story you can use to gain buy-in for broader adoption.
Ready to select the right data engineering partner to implement your data contract strategy? DataEngineeringCompanies.com provides expert rankings, cost benchmarks, and a free RFP checklist to help you choose with confidence. Find your ideal consultancy in minutes.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

A Data Lineage Tools Comparison Framework for Engineering Leaders
Cut through the noise with this data lineage tools comparison. Evaluate top vendors on architecture, integration, and pricing for your modern data platform.

A Practical Guide to Data Management Services
A practical guide to selecting the right data management service. Compare models, understand pricing, and learn key implementation steps to drive ROI.

A Practical Guide to Hiring Data Governance Consultants
Hiring data governance consultants? This guide unpacks their roles, costs, and selection criteria to help you find the right partner for your modern data stack.