A CTO's Guide To Real-Time Data Pipeline Architecture

Building or procuring a real-time data pipeline is a high-stakes decision. Relying on outdated batch processing creates operational blind spots and revenue leaks. The decision is no longer if you need real-time data, but how to build a scalable and cost-effective architecture without derailing your engineering roadmap. This guide provides a decision framework for engineering leaders evaluating pipeline architecture, platform selection, and the partners needed to execute.
Choosing Your Architectural Pattern: Streaming, Lambda, or Kappa
Picking the right architectural pattern is the single most important decision. It directly dictates system complexity, budget, and long-term maintenance overhead. The choice is stark: move away from batch processing to become “real-time ready,” or accept the revenue loss that comes with data delays.
Sticking with slow, batch-based systems is no longer a viable option when competitors operate in real-time. The shift to streaming unlocks immediate business impact:
- Fraud and Anomaly Detection: Block suspicious transactions the moment they happen, not after the funds are gone. See how GPU instances are used for real-time identity verification.
- Dynamic Pricing: Adjust prices based on live demand and competitor moves, maximizing revenue per transaction.
- Operational Intelligence: Monitor system health, user activity, and supply chains on live dashboards to solve problems instantly.
Comparing Core Architectural Patterns
Three primary architectural patterns exist: pure streaming, Lambda, and Kappa. Each has distinct trade-offs in complexity, cost, and data accuracy.
- Pure Streaming: The most direct approach. Data flows in a single line from ingestion to the end-user. It is fast and efficient but makes reprocessing historical data or correcting errors difficult.
- Lambda Architecture: A dual-path approach. A “hot” path provides immediate streaming analytics, while a “cold” path runs comprehensive batch jobs for accuracy. This creates a robust, fault-tolerant system, but the cost and complexity of building and maintaining two separate codebases are significant.
- Kappa Architecture: A modern simplification of Lambda. Kappa uses a single, unified streaming pipeline for both real-time events and historical reprocessing by “replaying” data from an immutable log like Apache Kafka. The primary driver for adopting Kappa is to slash the operational complexity of managing two codebases.
For a deeper analysis of these models, review our guide on stream processing vs. batch processing.
Actionable Framework: Making the Right Choice
Your decision depends on business requirements, team skills, and your existing tech stack. This table maps project requirements to the right architectural foundation.
Architectural Pattern Comparison Checklist
| Criterion | Pure Streaming | Lambda Architecture | Kappa Architecture |
|---|---|---|---|
| Operational Complexity | Low | High | Medium |
| Development Overhead | Low | Very High | Medium |
| Data Consistency | Good (but hard to correct) | High (eventually consistent) | High (unified source) |
| Fault Tolerance | Low (reprocessing is difficult) | Very High (batch layer as source of truth) | High (replayable stream) |
| Best For | Simple, low-latency alerting; IoT dashboards | Mission-critical systems requiring absolute accuracy and uptime | Modern data platforms where a unified approach is feasible (Databricks, Snowflake) |
Modern cloud data platforms like Databricks and Snowflake make Kappa-style architectures more accessible, often eliminating the need for Lambda’s dual-path complexity in new projects. The pattern you select will define your team’s daily workload and your pipeline’s resilience for years.
Building a Modern Real-Time Component Stack
Architecting a real-time pipeline requires selecting a set of high-performance components that integrate into a cohesive system. For enterprise architects, this means choosing the right tools for each layer of the stack.
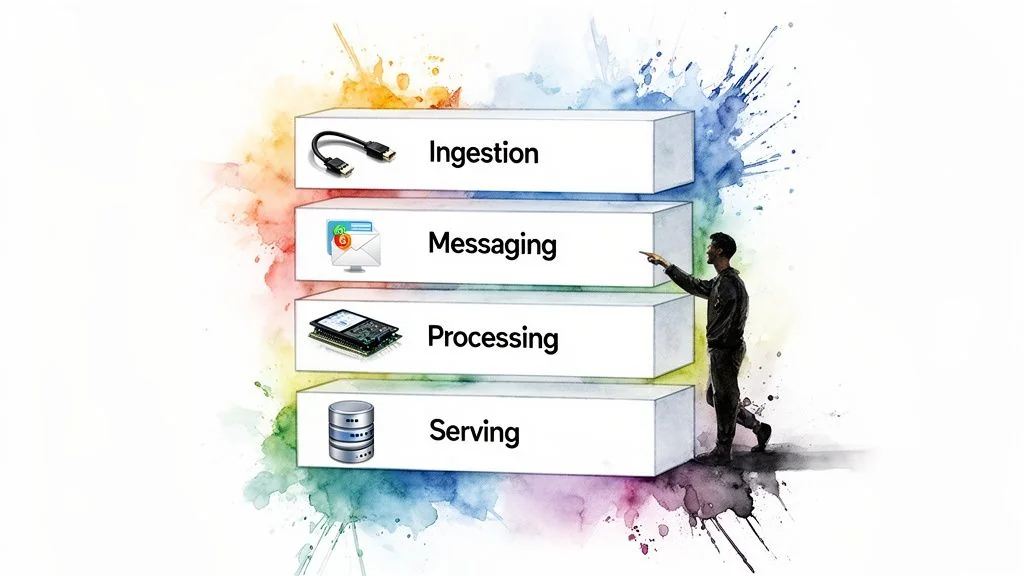
The pipeline begins with capturing data from source systems the moment it changes.
Ingestion and Change Data Capture (CDC)
For transactional databases, Change Data Capture (CDC) is the gold standard. It taps into the database’s transaction log, turning every INSERT, UPDATE, and DELETE into a streamable event.
Key CDC tools include:
- Debezium: An open-source CDC toolkit with connectors for major databases, built to integrate seamlessly with Kafka. It offers maximum control for building decoupled pipelines.
- Fivetran: A managed ELT service that handles the CDC process as an “easy button.” It accelerates development for standard sources at the cost of some fine-grained control.
Robust database replication software is key to ensuring data consistency from source to destination.
Messaging and Stream Processing Layers
Once captured, data needs a messaging layer to act as a central, durable hub for event streams. A stream processor then transforms and enriches that data in motion.
- Messaging Layer: Apache Kafka is the dominant technology, serving as a high-throughput, fault-tolerant distributed log.
- Processing Layer: The decision often comes down to two frameworks:
- Apache Flink: Built for true, low-latency stream processing, handling complex event processing and stateful computations where every millisecond is critical.
- Spark Streaming: Operates on a micro-batching model, processing data in tiny, rapid batches. It is simpler to manage and integrates seamlessly with the broader Spark ecosystem, making it a natural choice for teams already using Spark.
The Serving Layer
Finally, the processed, real-time data needs a serving layer optimized for fast lookups by applications and users. Modern cloud platforms like Snowflake (with Snowpipe Streaming) and Databricks (with Delta Live Tables) are blurring the lines by offering unified environments for both processing and serving. This consolidated approach, detailed in our guide to choosing a streaming data platform, can dramatically simplify your real-time data pipeline architecture and reduce total cost of ownership.
Making Critical Design Decisions That Scale
The long-term success of your real-time data pipeline depends on a handful of key design decisions made upfront. Getting these wrong leads to costly re-architecture.

The most critical trade-off is latency vs. cost. True sub-second latency is powerful but can be exponentially more expensive than near-real-time (5-30 second) processing. Business stakeholders must quantify the value of every millisecond saved. A fraud detection system requires instant response; an internal operational dashboard does not.
Data Governance is Not Optional
In streaming data, governance is a fundamental requirement to prevent pipeline failure. Failure is a matter of when, not if, without it. Strong streaming governance is built on three pillars:
- Schema Evolution: Upstream schema changes must not break downstream applications. Tools like Confluent Schema Registry enforce compatibility rules (backward, forward, full) to prevent a minor change from causing a major outage.
- Data Contracts: Formal agreements between data producers and consumers that define schema, semantics, and quality standards. A “contract-first” approach, where changes are agreed upon before being coded, prevents the vast majority of breakages.
- Automated Quality Monitoring: Manual data validation is impossible at streaming speeds. Automated tools must constantly monitor data streams for anomalies, schema drift, and quality degradation.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, only 28% have a formal, repeatable process for implementing data contracts in real-time systems. This is a critical gap to investigate when evaluating partners.
Data quality issues directly impact the bottom line. With data pipelines becoming more complex, data teams face an average of 67 data quality incidents per month, which erodes revenue. For any Head of Data, ensuring a prospective partner from the DataEngineeringCompanies.com rankings has proven expertise with platforms like Snowflake or Databricks and a track record of implementing strong governance is non-negotiable. Improving data pipeline efficiency is key to protecting that revenue.
How to Evaluate Data Engineering Partners
Choosing the right data engineering consultancy is a critical decision. Experience with traditional batch ETL does not translate to the high-speed, stateful world of streaming data. Your RFP must go deeper than standard questions to find a team with proven, specific skills in building real-time systems. Otherwise, you risk paying a partner to learn on your dime.
Core Competencies to Validate
A consultancy’s value is in their hands-on experience with specific streaming technologies and governance patterns. The vetting process must include pointed questions about their project work:
- High-Volume Messaging: Ask for case studies managing Apache Kafka or Google Cloud Pub/Sub at scale. What was their peak message throughput? How did they approach partitioning strategies for high consumer parallelism?
- Stream Processing Frameworks: Do not accept “we have Spark experience.” Ask if they have built stateful processing jobs with Apache Flink or unified workloads with Spark Structured Streaming. Why did they choose one over the other for a specific project?
- Streaming Data Governance: How have they handled schema evolution using tools like Confluent Schema Registry? Request an example of a data contract they have implemented on a past real-time project.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, only 35% show deep expertise in both Lambda and Kappa architectures. This reveals a major market gap; many firms can implement one pattern but lack the versatility to advise on the best fit for a client’s specific business needs.
A rigorous evaluation process separates true experts from generalists. Demand proof of successful projects that match your target complexity. This upfront diligence is your best defense against project failure.
Next Steps: Your Action Plan for Going Real-Time
For a CTO, VP of Engineering, or Head of Data, the next step is to translate architectural diagrams into business impact. Follow this three-step plan.
1. Conduct an Internal Latency Audit
First, build the business case. Task your lead architects and business analysts to identify the top three business processes suffering from stale data. They must quantify the “cost of delay” for each. Is it lost revenue from delayed fraud detection? Missed sales from out-of-sync inventory? This exercise provides the financial justification for the investment.
2. Hold an Architectural Strategy Session
With the business case established, decide on a technical path. Use the architectural comparison framework from this guide to facilitate a debate on the merits of pure streaming vs. Lambda vs. Kappa in the context of your specific goals. The outcome must be a documented decision on your target architecture to prevent scope creep and rework.
3. Shortlist Expert Partners
Begin evaluating potential partners to help you build. Create a shortlist of qualified data engineering firms from a resource like DataEngineeringCompanies.com. Focus on finding a team with proven, hands-on experience in your chosen architectural pattern and platform. Ask for case studies that mirror your challenges to separate the true experts from the rest.
Frequently Asked Questions
What Is The Difference Between Real-Time And Near-Real-Time?
The difference is the latency your business actually requires.
- Real-time is instant processing (milliseconds). It is necessary when a delay of seconds makes the data useless, as in high-frequency trading or blocking fraudulent transactions.
- Near-real-time processes data every few seconds up to a minute. It is practical for use cases like live dashboards or website personalization, where the experience feels immediate to a human without the cost and complexity of a true real-time system.
How Do I Justify The Cost Of A Real-Time Pipeline?
Frame the investment around business value by quantifying the “cost of delay.” Get specific. How much revenue is lost to fraud caught too late? How many sales are lost because inventory data is stale? What is the financial impact of customer churn from a slow application? When you attach a dollar figure to these delays, the investment becomes a clear competitive advantage with a measurable ROI.
Can I Build A Real-Time Pipeline On Snowflake Or Databricks?
Yes. Both Snowflake and Databricks have powerful but different capabilities for building these pipelines. The choice depends on your team’s skills, latency goals, and existing tech stack.
- Databricks, built on Apache Spark and Structured Streaming, is a natural fit for a unified batch and stream processing platform, embodying the Kappa architecture.
- Snowflake’s Snowpipe Streaming provides a low-latency ingestion path, while Dynamic Tables allow for declarative, near-real-time transformations directly within the data warehouse.
An expert data engineering partner can map your business goals to the technical strengths of each platform to ensure you select the optimal path.
Choosing the right partner is critical to building a scalable and cost-effective real-time architecture. DataEngineeringCompanies.com provides transparent, data-driven rankings and tools to help you find a consultancy with verified expertise in Snowflake, Databricks, and modern streaming frameworks. Find your expert data engineering partner today.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
Related Analysis

What is data ingestion: a practical guide for 2025
Discover what is data ingestion and why it's the essential first step for AI and analytics. Explore batch vs. streaming, ETL vs. ELT, and modern architectures.

Your Guide to Data Engineering Consulting Services
Unlock the value of your data. This guide to data engineering consulting services covers costs, vendor selection, red flags, and platform-specific insights.

Top 7 Places to Find Data Engineering Service providers in 2026
Discover the 7 best places to find and evaluate data engineering service providers. Get practical, no-fluff insights to select the right partner in 2026.