Data Engineering for SaaS Companies: Leaders' 2026 Guide

Most advice on data engineering for SaaS companies is upside down. It starts with tools, ingestion patterns, and architecture diagrams. That’s the wrong order.
A SaaS CTO doesn’t win by collecting more data. You win by turning product, billing, CRM, and support data into reliable operating metrics and customer-facing capabilities without letting the platform turn into a margin tax. If your warehouse bill, pipeline sprawl, and governance debt rise faster than product value, you didn’t build an asset. You built overhead.
The right question is simple: which data platform design gives the business trustworthy metrics, AI-ready data, and customer-facing analytics at a cost structure you can defend? That’s the standard I use when advising software companies on data platform modernization, vendor selection, and consulting engagements.
The Real Challenge in SaaS Data Engineering Is Cost not Capability
The problem often isn’t one of capability. It’s a cost discipline problem.
The market already offers more than enough ways to move data into Snowflake, Databricks, BigQuery, Redshift, or Azure. You can wire up Fivetran, Airbyte, dbt, Airflow, Dagster, Kafka, Spark, and half a dozen observability tools in a quarter. That doesn’t mean you should.
A better framing comes from Centric Consulting’s discussion of data engineering unit economics and ROI discipline. Their point is the one most SaaS leaders miss: coverage usually focuses on pipeline capability and speed, while the harder business question is how to keep data costs proportional to product growth.
Treat data spend like data COGS
If your product depends on usage reporting, customer health scoring, embedded analytics, revenue reporting, or AI features, your data platform is part of delivery. That means you should track it like data COGS, not like a vague shared services budget.
Use four lenses:
- Ingestion cost per source. Know which connectors, CDC jobs, and event streams justify their spend.
- Transformation cost per domain. If finance, product, and support each run duplicative models, fix the model design before you blame the warehouse.
- Serving cost per workload. Internal BI, reverse ETL, customer dashboards, and ML features should not all share the same latency and compute assumptions.
- Governance overhead per team. Every manual permission review, schema fix, and broken metric definition is operating cost.
That discipline starts with cloud basics. If your finance and engineering teams need a good operating baseline, Buttercloud’s guide to cloud cost optimization strategies for startups is a useful companion for setting expectations before your data stack expands.
Practical rule: If a platform decision doesn’t improve margin, retention reporting, or product capability in a measurable way, defer it.
The expensive mistake
The most common mistake is building for hypothetical scale. Teams buy a streaming architecture before they’ve identified one workload that requires it. They stand up Databricks because it feels future-proof, then run mostly SQL transformations that a warehouse and dbt would handle more easily. They let every department add tools, then act surprised when governance and cloud bills drift.
For data engineering for SaaS companies, the standard should be harsh: prove the use case, prove the ownership model, then build the minimum architecture that survives growth.
Architecting for Isolation Multi-Tenant Data Patterns
For SaaS companies, your hardest architecture decision usually isn’t Snowflake versus Databricks. It’s how tenant data is isolated.
Get this wrong and you inherit one of two bad outcomes. Either your cost per tenant becomes absurd, or your governance model collapses the first time an enterprise customer asks detailed questions about access boundaries, data residency, or customer-facing analytics.
The three patterns that actually matter
There are three workable models.
| Attribute | Silo Model (Database per Tenant) | Pool Model (Shared Database) | Hybrid Model (Pooled with Premium Silos) |
|---|---|---|---|
| Isolation boundary | Strongest logical separation | Shared storage with tenant filters | Mixed, based on tenant tier or risk |
| Cost per tenant | Highest | Lowest | Controlled, if used selectively |
| Operational burden | High | Lower at baseline | Medium to high |
| Performance isolation | Strong | Variable unless carefully engineered | Strong for premium workloads |
| Governance complexity | Lower inside each tenant, higher across fleet | High because policy errors affect everyone | Highest because two models coexist |
| Customer-facing analytics fit | Good for strict isolation requirements | Good for broad scale if row-level controls are mature | Best when large tenants need custom treatment |
| Migration flexibility | Weak if you over-customize | Strong if schemas stay disciplined | Strongest if tenant promotion paths are planned |
Silo works when isolation beats efficiency
The silo model gives each tenant its own database, schema, or full environment. It’s expensive, but the trade-off is obvious and sometimes necessary.
Use it when you have:
- Strict enterprise boundaries where customers expect hard separation
- Custom compute or retention policies for a subset of tenants
- Contractual obligations that require dedicated treatment
- Heavy customer-facing analytics that would otherwise create noisy-neighbor problems
The downside is operational drag. Every migration, schema update, and quality check multiplies across tenants. Consulting teams often underestimate this because the early implementation looks clean. The pain shows up later in fleet management.
Pool wins by default, but only with disciplined policy design
The pool model is the default choice for most SaaS platforms because it gives the best cost profile. One shared platform, one set of models, one warehouse, one observability layer.
But pooled architecture only works if you treat tenant controls as first-class engineering, not as an afterthought. That means:
- Tenant keys are mandatory in raw, staged, and modeled layers
- Row-level access rules are versioned and tested
- Metric definitions are tenant-aware from the start
- Schema changes are reviewed for downstream tenant impact
- Customer-facing workloads don’t query ad hoc shared tables
Shared infrastructure is cheap right up until one bad join leaks cross-tenant data.
Hybrid is usually the right answer for serious SaaS businesses
The hybrid model is where mature SaaS platforms end up. Pool the majority of tenants. Promote selected tenants or workloads into silos when economics, compliance, or performance justify the move.
That lets you keep baseline costs under control while preserving a premium path for larger accounts.
My recommendation for choosing
Don’t pick a tenancy pattern as a philosophical preference. Pick it based on these decision criteria:
-
Revenue model
If premium accounts pay for dedicated analytics, hybrid is usually the commercial fit. -
Customer-facing data requirements
If your product exposes usage dashboards, benchmarking, or exports, pooled models need stricter semantic controls. -
Support model
If your support team frequently inspects customer-level data, access boundaries must be explicit and auditable. -
Migration path
If a pooled tenant can’t move into a dedicated setup without a rewrite, your architecture is brittle. -
Consulting team capability
Many firms can build pipelines. Fewer can design tenant isolation, promotion paths, and policy automation cleanly.
The mistake to avoid is trying to solve multi-tenancy inside BI alone. Isolation belongs in platform design, transformation logic, and permissioning. If you leave it to dashboards, you’ve already lost control.
The Modern SaaS Data Stack Blueprint
For most SaaS companies, the best stack is modular. Not maximal.
That means managed ingestion where speed matters, SQL-first transformation where repeatability matters, and warehouse or lakehouse choices based on workload shape, not hype.
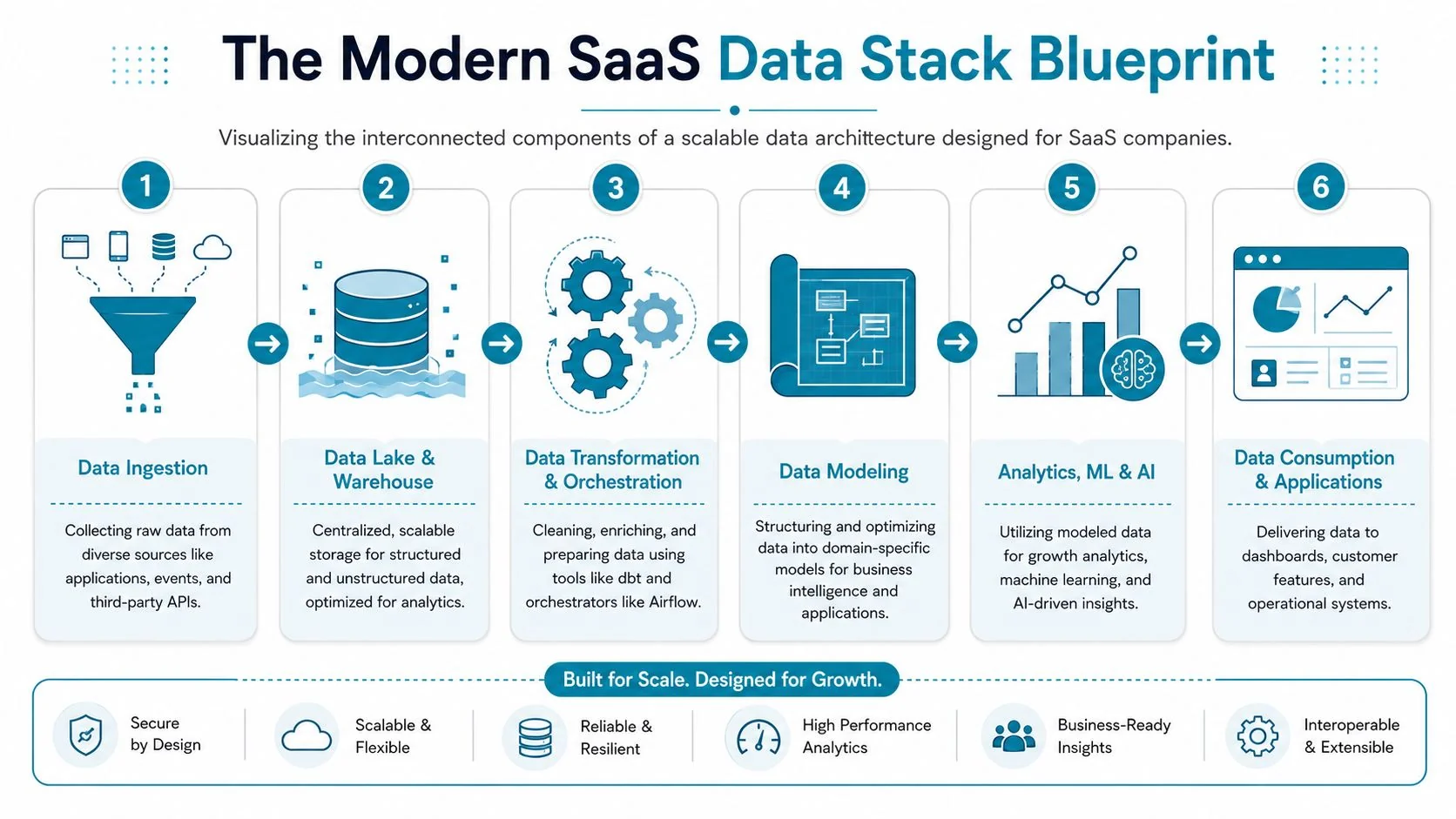
A blueprint that survives growth
A practical stack for data engineering for SaaS companies usually looks like this:
- Product event ingestion with Segment or Snowplow when event governance matters
- Operational source ingestion with Fivetran or Airbyte for Salesforce, HubSpot, Zendesk, NetSuite, and similar systems
- Core platform on Snowflake, Databricks, BigQuery, or an AWS/Azure-native architecture depending on team skill and workload shape
- Transformation layer in dbt for standardized, testable business logic
- Orchestration with Airflow or Dagster when workflow control and dependencies matter
- Consumption layer for BI, reverse ETL, embedded analytics, ML features, and application services
Snowflake versus Databricks for SaaS
Here’s the blunt version.
Choose Snowflake first if your immediate goals are finance-grade metrics, modeled analytics, internal reporting, and predictable SQL-heavy delivery. It’s usually the cleaner fit for teams that need fast time to value with strong separation between storage, compute, and governed sharing.
Choose Databricks first if your platform already has heavy data science, large-scale event processing, unstructured or semi-structured workloads, or engineering teams comfortable with Spark-oriented patterns. It’s a better fit when analytics and ML engineering are tightly coupled.
BigQuery is strong when the team is already committed to GCP. AWS and Azure-native patterns make sense when procurement, security, and platform operations already center there. But don’t let cloud loyalty override workload reality.
Why dbt and orchestration matter more than tool fashion
dbt became the standard for a reason. It forces business logic into version-controlled, testable transformations. That matters more than connector count.
Your orchestrator matters too, but less than people assume. Airflow remains a solid choice when you need broad ecosystem support and explicit dependency management. Dagster is attractive when you want stronger software-defined assets and developer ergonomics. Either works if the team owns it.
If you’re planning AI-heavy workloads, this piece on AI integration in data stacks is a useful reference for separating core analytical architecture from experimentation layers.
Don’t buy six tools to avoid writing standards. Standards are the real platform.
What to avoid
Avoid these stack mistakes:
- Connector sprawl where each team buys its own sync tool
- Transformation split-brain where logic is scattered across SQL, Python notebooks, BI dashboards, and app code
- Single-cluster thinking where every workload shares one compute posture
- Premature streaming without a real product or operational need
- Opaque vendor lock-in where nobody can explain how critical models are built
The stack should reflect business priorities. If the current priority is board metrics and embedded reporting, optimize for governed SQL and clear tenancy patterns. If the current priority is ML feature velocity, optimize for data contracts, feature consistency, and notebook-to-production discipline.
Modeling for Growth Analytics ML and Customer Features
A platform becomes valuable when the data model serves real consumers. For SaaS, those consumers usually fall into three groups: operators, models, and customers.

One SaaS-focused KPI guide makes the point clearly: CAC, LTV, Churn, MRR, and NRR all depend on engineered data pipelines. It also notes that some teams set targets such as reducing CAC by 20% or increasing NRR to 110% by Q3 2025, which shows how tightly data engineering connects to financial execution, not just reporting (Phoenix Strategy Group on SaaS KPI data engineering).
Internal analytics needs one metric layer
If finance, sales, and product all calculate MRR differently, the problem isn’t dashboard design. It’s model design.
Build an explicit semantic layer for:
- Customer grain with account, tenant, contract, and lifecycle status
- Subscription grain with plan, effective dates, expansion, contraction, and cancellation events
- Usage grain with normalized product events tied to account identity
- Support and CRM grain for health, funnel, and retention analysis
dbt demonstrates its worth. Keep the metric logic centralized. Test it. Version it. Don’t let Looker, Power BI, Sigma, and ad hoc SQL each invent their own revenue definitions.
ML workloads need stable features, not hero notebooks
Most SaaS ML efforts fail because feature logic differs between experimentation and production.
For churn models, lead scoring, anomaly detection, or product recommendations, define feature pipelines that reuse the same trusted entities and event models from the analytics layer. Then expose them through a feature-serving pattern your platform team can support consistently.
That doesn’t require a heavyweight feature store on day one. It does require discipline around:
- Point-in-time correctness
- Entity keys and tenant scope
- Refresh cadence
- Training-serving consistency
Here’s a useful engineering overview before you push models into production:
Customer-facing features need product-grade data contracts
Many internal data teams stumble on this point: embedded analytics, usage dashboards, benchmarks, customer exports, and admin reporting are not BI side projects. They are product features.
Model them separately from internal analytics.
Use these rules:
-
Create product-serving models
They should be tenant-scoped, latency-aware, and backward-compatible. -
Version customer-facing metrics
If a definition changes, support migration intentionally. Don’t surprise customers. -
Precompute what’s expensive
Your app should not fire complex warehouse queries for every dashboard load. -
Define freshness by feature
Some customer metrics can be delayed. Others can’t. Don’t overbuild real-time where near-real-time is enough.
If a customer sees the number, your product team owns the definition with data engineering. Not BI.
A SaaS Framework for Data Governance and Security
Most governance programs fail because they start as policy writing exercises. SaaS companies need something else. They need operational governance that survives continuous schema change, fast product releases, and cross-functional data access.
A recent overview of data engineering trends highlighted the gap directly: governance for customer-facing and AI-ready SaaS data is under-addressed, especially around schema change, data quality, and safe sharing. It also noted that the field is shifting from infrastructure plumbing to reliability engineering for decisioning and AI (Refonte Learning on data engineering trends and governance).

Five controls that matter
Policy tied to data products
Every critical domain needs an owner. Product events, billing data, customer identity, support data, and financial metrics should each have accountable ownership.
Use a shared standard for classification, retention, and acceptable use. If you need a starting point, the DataEngineeringCompanies governance template is a practical way to structure ownership and policy decisions.
Access control at the right granularity
Role-based access is the floor, not the ceiling.
Use:
- Column-level restriction for sensitive attributes
- Masked development datasets for lower environments
- Tenant-aware policies for shared environments
- Auditable privileged access for support and operations teams
Application security still matters around the edges of the platform too. If your engineering org is tightening controls end to end, this guide on how to secure your SaaS application is a useful complement to data-layer governance.
Data quality contracts
Data quality should be attached to models and interfaces, not reviewed in a meeting after something breaks.
Require tests for:
- Schema stability
- Null and uniqueness expectations
- Accepted value ranges
- Freshness windows
- Tenant key integrity
Observability beats blame
When sources change, dashboards break, ML features drift, and support teams lose trust. That’s why observability matters.
Instrument pipelines so teams can answer three questions quickly:
| Governance concern | What to monitor | What action to automate |
|---|---|---|
| Schema change | Upstream field additions, deletions, type changes | Block unsafe promotion and alert owners |
| Data freshness | Missed loads and delayed event arrival | Trigger retries and escalate on breach |
| Metric consistency | Divergence between canonical and downstream models | Fail tests before dashboards refresh |
| Access misuse | Unexpected queries against sensitive domains | Audit and revoke when policy is breached |
Governance that slows delivery gets bypassed. Governance embedded in CI, orchestration, and access policies gets adopted.
Discovery closes the loop
You also need discoverability. Every metric and high-value model should have a documented definition, owner, upstream lineage, and intended audience. Without that, analysts fork logic, product managers export raw tables, and ML teams train on unvetted inputs.
For data engineering for SaaS companies, governance is not a compliance annex. It’s what lets the company ship customer-facing analytics and AI features without losing trust.
Vendor Selection and RFP Checklist for Data Engineering
A generalist consultancy can migrate data. That doesn’t mean it can design a SaaS data platform that handles tenant isolation, board metrics, product analytics, and governance without spawning years of cleanup work.
Specialized data engineering exists for a reason. As SaaS adoption accelerated, data engineering grew from a small specialty into critical infrastructure. One historical summary notes that the number of data engineers more than doubled from 2013 to 2015, and that shift tracks with the need for standardized, automated, cloud-based pipelines in SaaS (DataEngi on the rise of data engineering in SaaS).

What I’d put in the RFP
Ask vendors to answer these clearly. If they dodge, remove them.
- Which SaaS data platforms have you built that include tenant isolation?
- What tenancy pattern do you recommend for our product and why?
- How do you model MRR, churn, expansion, contraction, and NRR canonically?
- Which cloud are you strongest on: AWS, Azure, or GCP?
- What is your default warehouse recommendation and what would change it?
- How do you decide between Snowflake and Databricks?
- What ingestion tools do you prefer for CRM, billing, support, and product events?
- When do you recommend dbt, and when don’t you?
- How do you enforce schema change management?
- How do you implement row-level and column-level access control?
- How do you design customer-facing analytics models differently from internal BI?
- What observability stack do you deploy by default?
- How do you document metric definitions and lineage?
- What do you automate in CI/CD for data assets?
- How do you estimate ROI before implementation?
- How do you control data platform unit costs as volume grows?
- What team roles are included, and which are fractional?
- What work is done offshore, onshore, or hybrid?
- How do you transfer ownership to our internal team?
- What does success look like in the first ninety days?
- Show an example of a failed engagement and what you changed afterward.
- What assumptions in our draft architecture do you disagree with?
How to score proposals
Don’t score heavily on slide quality or brand recognition. Score on evidence of judgment.
Use these categories:
- Architecture fit for your tenancy and workload model
- Platform depth in your chosen cloud and core tools
- Governance maturity beyond access-control boilerplate
- Commercial clarity on scope ownership and change control
- Enablement quality so your team can run the platform afterward
The best consulting partner is the one willing to narrow scope early, challenge your assumptions, and say no to unnecessary platform complexity.
Your 90 Day Data Platform Modernization Roadmap
The first ninety days should produce one thing above all else: confidence that your platform direction is financially sane and operationally trustworthy.
Days 1 to 30
Audit the current stack. Map every source, pipeline, model, dashboard, and downstream dependency. Identify where metric definitions diverge, where tenant isolation is weak, and where spend is rising without clear value.
Then make three decisions: your target tenancy model, your core platform choice, and the first business metric domain to standardize.
Days 31 to 60
Build the foundation, not the whole future state.
Stand up the core environment. Implement one high-value path end to end, typically product events plus billing or CRM into the warehouse, dbt models, tests, and a governed dashboard. Add access policies and schema-change alerts now, not later.
Days 61 to 90
Expand to a second source domain and force governance into the operating model. Define owners for key datasets. Publish metric definitions. Add observability. Separate internal models from product-serving models if embedded analytics is on the roadmap.
By day ninety, you should have:
- One canonical metric domain
- One validated tenant isolation pattern
- One production governance workflow
- One clear cost model for further rollout
That’s enough to scale intelligently.
If you’re evaluating consulting partners for data engineering for SaaS companies, use DataEngineeringCompanies.com to compare firms by platform expertise, industry fit, delivery model, and budget. Shortlist candidates, pressure-test them with the RFP criteria above, and choose the team that can defend both the architecture and the economics.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Featured Data Engineering Partners
Vetted firms whose specialty matches this article.