Data Engineering for Private Equity: The 2026 Guide

Private equity firms still talk about analytics as if the hard part is dashboards. It isn’t. The hard part is engineering a data system that can survive the scale and messiness of the asset class.
That’s obvious once you look at the market’s underlying data footprint. LSEG’s private equity and venture capital dataset covers 43,000+ PE/VC firms, 91,000+ funds, and 316,000+ current and former backed companies, with transaction history dating back to the 1970s, according to LSEG’s private equity data overview. If your firm still relies on spreadsheet-driven portfolio reporting, disconnected CRM exports, and ad hoc SQL built around one fund at a time, you don’t have a reporting problem. You have an operating model problem.
For CTOs, this changes the mandate. Data engineering for private equity isn’t a support function for the investment team. It’s the infrastructure that determines whether sourcing, diligence, portfolio operations, and LP reporting run on a shared truth or on conflicting versions of reality.
The firms that get this right don’t start with AI demos. They start with architecture, governance, and procurement discipline.
Introduction The New Alpha Is Engineered
Alpha in private equity comes from data infrastructure long before it shows up in a dashboard, a model, or an AI pilot.
Firms lose speed and margin in the same places over and over: duplicate entities, inconsistent portfolio definitions, stale operating metrics, and reporting logic trapped inside spreadsheets or vendor black boxes. The result is predictable. Deal teams debate numbers instead of decisions. Operating teams rebuild the same KPI mappings company by company. Finance spends quarter-end reconciling outputs that should have matched on day one.
Private equity now operates at a scale and history depth that informal tooling cannot handle, as noted earlier. What creates advantage is not more software. It is a data foundation built to standardize entities, preserve history, and produce numbers your investment, operating, and finance teams will all accept.
What creates advantage
A PE data platform has to do three jobs well from the start:
- Normalize messy entities: The same company, sponsor, executive, lender, or advisor often appears under different names across CRM, fund accounting, portfolio reports, and third-party datasets.
- Preserve history: Sourcing, benchmarking, value-creation tracking, and exit planning all depend on time-series data, not overwritten snapshots.
- Prove lineage: If a KPI reaches the IC deck or LP report, your team needs to know the source, transformation logic, owner, and refresh cadence.
Private equity does not have a data scarcity problem. It has a trust and operating discipline problem.
This matters in procurement as much as architecture. CTOs should reject vendors that demo polished dashboards but cannot explain entity mastering, pipeline monitoring, change management, and handoff ownership after go-live. The expensive mistake is buying presentation before foundation.
Data engineering for private equity belongs in the Data pipeline architecture hub because the work is operational, not cosmetic. The right implementation plan defines system boundaries, integration order, data ownership, and the cost to support the platform after the SI has left. That is where the return gets won or lost.
Why Data Engineering Is a Mandate Not a Project
Private equity outgrew project-based data work. The asset class itself made that inevitable.
According to Codal’s summary of PE analytics trends, assets under management rose from just over $2 trillion in 2013 to over $4.4 trillion in 2022, and a typical private equity investment is held for 5 to 7 years. That combination changes everything. More capital means more portfolio complexity. Longer holds mean data has to support continuous operating decisions, not just acquisition memos.

Why the old model breaks
A classic analytics project has a clear finish line. A dashboard gets delivered. A model gets tested. A reporting pack gets automated.
That framing fails in PE because the workload never stops:
- Deal teams need current market and target data
- Operating teams need ongoing portfolio signals
- Finance needs governed LP reporting
- Leadership needs cross-fund comparability
Those are recurring platform responsibilities, not temporary deliverables.
What CTOs should treat as mandatory
If you’re leading technology in a PE environment, the minimum viable mandate is straightforward:
-
Create a common data layer across firm and portfolio Internal deal data, portfolio KPIs, and external market data can’t live in separate logic silos.
-
Standardize data contracts with portfolio companies If every company reports differently, your central platform becomes a reconciliation factory.
-
Build governance before model complexity A bad metric delivered fast is worse than a delayed metric. It drives bad intervention decisions.
-
Fund the platform as operating infrastructure If budget owners treat this as a one-time transformation, they’ll under-resource maintenance and break trust within a year.
Practical rule: If a PE firm describes its data platform as a project with an end date, the design is already wrong.
This is also where many firms waste money. They buy enterprise tooling before they’ve agreed on portfolio-level definitions, ownership, or ingestion standards. Then they blame the platform. The platform usually isn’t the problem. Weak operating discipline is.
High-Value Use Cases for PE Data Engineering
The best use cases aren’t the flashiest ones. They’re the ones that remove friction from recurring decisions across the investment lifecycle.
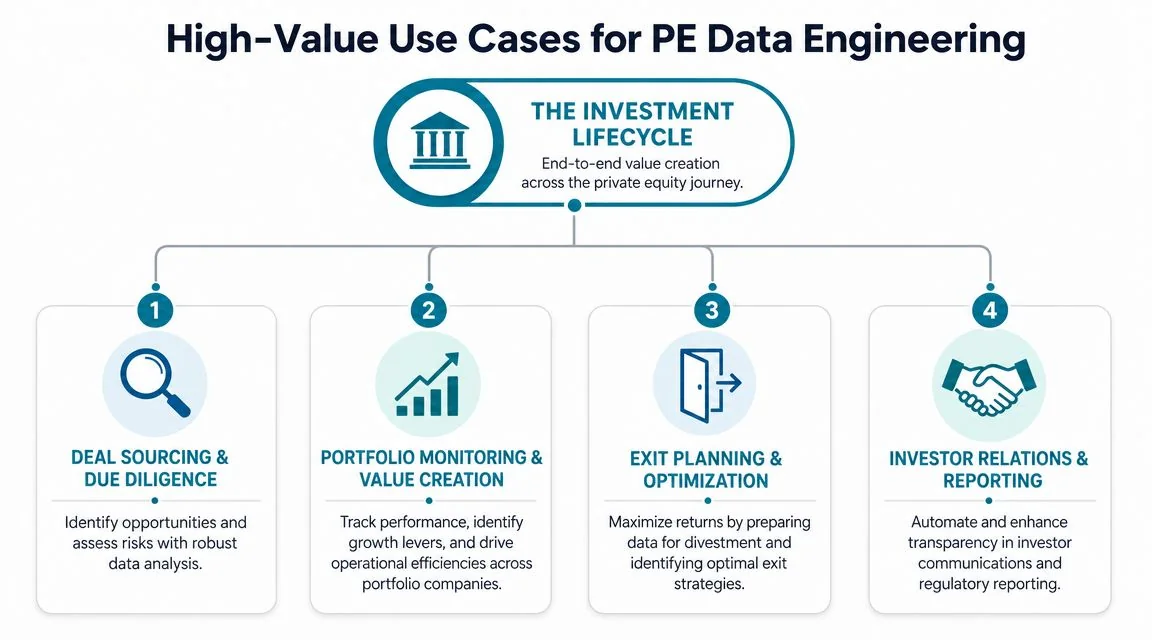
Deal sourcing and diligence
A strong platform lets the investment team work from a unified target universe instead of scattered notes, CRM records, banker materials, and third-party feeds. That matters because sourcing logic is only as good as the underlying entity matching and enrichment.
In practice, firms get value when they can:
- Rank targets against firm-specific criteria
- Pull historical deal and ownership context into one workflow
- Trace source data used in screening and diligence
- Reuse diligence models across similar deals
For sourcing and diligence, which require reusable pipelines, versioned transformations, and auditable inputs, data engineering surpasses generic BI. A nice dashboard won’t fix broken joins between sponsor, fund, and company records.
Portfolio monitoring and value creation
The highest recurring payoff comes after the deal closes. According to Analytics8’s view of modern PE portfolio management, the important shift is from periodic reporting to a 360-degree data architecture that supports continuous ingestion and governance. That architecture gives firms a fuller view of performance and operational risk, reducing decision latency and improving the chance of acting before KPI deterioration becomes irreversible.
That’s the difference between seeing a problem in time and discovering it in the next board pack.
A capable PE data platform should support:
- Continuous KPI ingestion from portfolio systems
- Cross-company metric standardization
- Alerting on operational variance
- Board and operating-partner views from the same governed models
When portfolio reporting depends on PowerPoint assembly, operating partners react to history instead of managing the present.
Exit readiness and investor reporting
Exit work exposes every weakness in your data estate. Buyers ask for consistency. Management teams scramble. Finance rebuilds numbers yet again.
Firms with sound data engineering can package cleaner operating history, defend metric definitions, and prepare diligence rooms faster. The same foundation also improves investor relations. LP reporting becomes less about manual compilation and more about controlled publishing from trusted models.
That doesn’t make exits easy. It makes them less chaotic.
Modern Data Architectures for Private Equity
Architecture choice should follow business intent. Too many PE firms reverse that order and buy a platform first.
The technical pattern that matters most is the proprietary data engine. According to CLA’s guidance on PE data engines, that engine unifies internal deal records, external market data, and enrichment layers into a single auditable system. It improves origination precision by ranking opportunities against firm-specific criteria and speeds execution by giving teams a single source of truth. That’s why off-the-shelf CRM and generic data lake setups usually fall short for PE workflows.
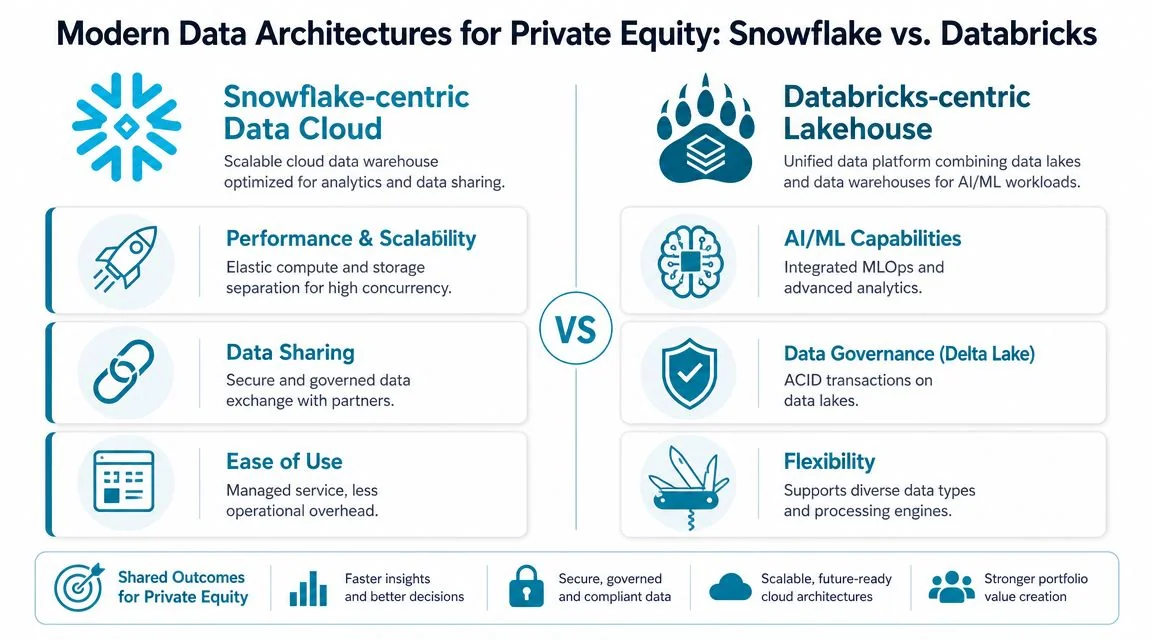
Snowflake-centric stack
Choose a Snowflake-led architecture when governance, SQL-first analytics, and controlled data sharing matter most.
This pattern usually fits firms that prioritize:
- Portfolio and fund reporting
- LP-ready governed datasets
- High-concurrency analytics
- Lower platform operations burden
A common implementation looks like Snowflake plus dbt for transformation, Airflow for orchestration, and cloud storage on AWS, Azure, or GCP. It’s a strong fit when your highest-value workflows are reporting-heavy and your users live mostly in analytics and finance.
Databricks-centric stack
Choose Databricks when your strategy depends on heavier data science, flexible processing, and machine-learning-driven sourcing or value creation.
This pattern is stronger when the firm needs:
- Feature engineering for proprietary scoring
- Mixed structured and semi-structured data
- Advanced notebooks and ML workflows
- Lakehouse flexibility across large raw datasets
Databricks plus Delta Lake, dbt, and Airflow works well when the data team behaves more like a product engineering group than a reporting team.
The decision table CTOs should use
| Architecture pattern | Best fit in PE | Strength | Watch out for |
|---|---|---|---|
| Snowflake-centric | LP reporting, portfolio analytics, finance-led governance | Managed experience and clean analytics workflows | Teams sometimes bolt on AI ambitions without designing for them |
| Databricks-centric | Quant sourcing, advanced analytics, ML-heavy enrichment | Native support for broader data and model workflows | Governance discipline can lag if engineering standards are loose |
| Hybrid | Larger firms with distinct reporting and ML needs | Lets each workload run where it fits best | Integration overhead and duplicated logic can get expensive fast |
Cloud choice matters less than discipline
AWS, Azure, and GCP all work. The bigger mistake is unclear storage and compute design. Teams still confuse application compute with data storage decisions, especially on AWS. If your team needs a straightforward refresher on that distinction, this EC2 vs S3 comparison is a useful way to reset the conversation before architecture workshops start.
Buy the platform that fits your dominant workflow. Don’t buy optionality you won’t operationalize.
Your Phased Implementation Roadmap
Most PE data programs fail because the firm tries to industrialize everything at once. Don’t. Build a sequence that proves value early and tightens standards as you go.
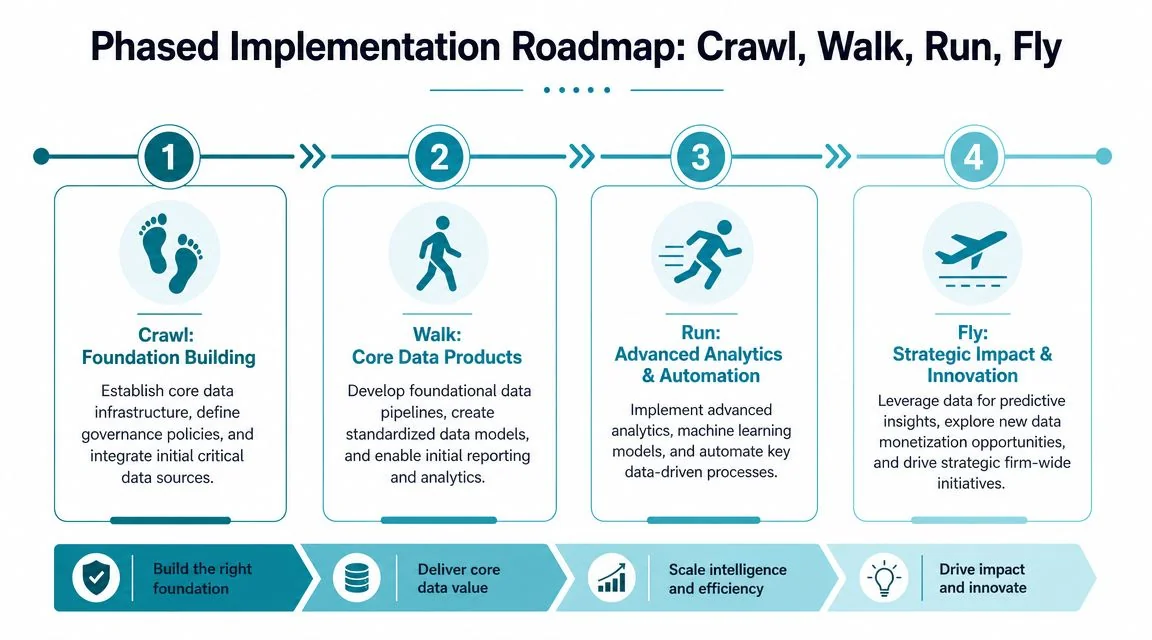
Crawl
Start with a narrow, central platform. Pick a warehouse or lakehouse. Stand up ingestion for the firm’s core internal data and a small set of recurring portfolio company feeds.
Your goal here is boring by design:
- One governed data model for portfolio reporting
- Basic orchestration with Airflow
- Transformation standards in dbt
- Named owners for source-system definitions
Don’t start with AI. Don’t start with broad enterprise lake ambitions. Start with data that the CFO, operating partner, and deal team all recognize as essential.
Walk
Now standardize what enters the platform. With this standardization, governance stops being a policy deck and becomes operating practice.
Add:
- Portfolio company submission templates
- Metric definitions with sign-off
- Data quality tests in pipelines
- Role-based access rules
This phase should produce the first reusable data products, not just reports. If every new dashboard still requires custom reconciliation, you’re not walking yet.
Run
Once the foundation is trusted, bring in external data and automate higher-value workflows. That includes market data, diligence enrichment, and proprietary scoring logic.
Typical work in this phase includes:
- Third-party data integration for sourcing
- Cross-portfolio benchmarking models
- Operational alerting and workflow triggers
- Early ML use cases where labeled data is credible
The right time to add predictive models is after your metric definitions stop changing every quarter.
Fly
This is the scale phase. By now, the firm should be treating the data engine as shared infrastructure across sourcing, diligence, portfolio operations, and reporting.
What changes here is less technical than organizational. The platform team starts acting like an internal product team. Roadmaps become explicit. Portfolio onboarding gets templated. Data contracts become part of acquisition and integration planning.
That’s the point where data engineering for private equity stops being a transformation effort and becomes part of how the firm operates.
Selecting the Right Data Engineering Partner
Most PE firms shouldn’t build the whole capability from scratch. It’s slower, riskier, and usually more expensive than leaders expect. The right consulting partner accelerates platform design, avoids avoidable mistakes, and forces architectural discipline early.
The wrong partner does the opposite. They staff generalists, over-customize the stack, and leave behind a system your internal team doesn’t want to own.
What matters in vendor evaluation
For PE, generic cloud credentials aren’t enough. You need a partner that understands portfolio-company variability, fund reporting pressure, and governance in a high-trust financial environment.
Use this shortlist of criteria during RFP review. For a broader consulting evaluation framework, this guide to data engineering consulting services is a practical reference.
| Evaluation Category | Key Question | Look For (Green Flag) | Watch Out For (Red Flag) |
|---|---|---|---|
| Industry fit | Have they worked with PE, financial data, or multi-entity operating models? | They can discuss portfolio integration and LP-grade governance in concrete terms | They speak only in generic modern data stack language |
| Architecture judgment | Can they explain when Snowflake, Databricks, dbt, and Airflow fit or don’t fit? | They recommend tradeoffs, not default stacks | They push one platform regardless of your workflows |
| Delivery model | Who actually builds the platform? | Named senior architect, clear handoff model, documented ownership | Sales-led process with vague delivery staffing |
| Governance approach | How do they handle metric definitions, lineage, and access control? | Governance built into pipeline design from day one | Governance deferred to a later phase |
| Operability | Can your internal team run it after go-live? | Strong documentation, CI/CD, tests, and runbooks | Consultant-dependent custom code |
| Commercial model | Is pricing aligned to scope and outcomes? | Transparent assumptions and change-control discipline | Cheap initial quote followed by broad “discovery” expansion |
Questions I’d ask in every finalist call
- Show me a sample dbt project structure
- Show me how you test source freshness and schema drift
- Explain how you’d onboard three portfolio companies with different ERP maturity
- Tell me what you would not build in phase one
- Show me how lineage and access control work in your preferred stack
If a partner can’t answer those crisply, they’re not ready for a PE data platform. They may still be fine for staff augmentation. That’s a different purchase.
Budgeting Your Data Engineering Initiative
Here’s the blunt answer. A real PE data platform is expensive enough to require partner-level sponsorship, but cheap enough to justify if you avoid overbuilding.
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, blended rates for consultants with PE-specific experience range from $195 to $350 per hour in 2026, and a typical foundational data platform build-out for a mid-market firm costs $250k to $600k in the first year, including consulting and platform fees. For rate context, use this 2026 data engineering consulting rates guide.
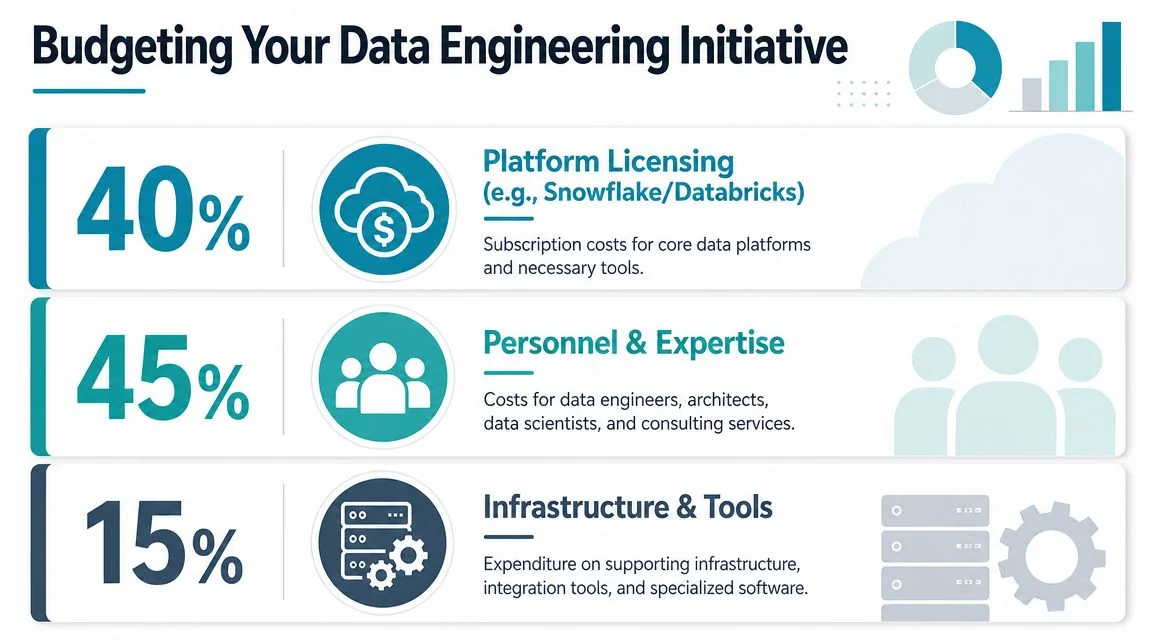
Where the money goes
The first-year budget usually breaks into three buckets:
-
Platform licensing and core tools Snowflake or Databricks, plus dbt, orchestration, observability, and cloud services.
-
Consulting and implementation Architecture, ingestion, modeling, governance, migration, and enablement.
-
Internal staffing Product ownership, engineering oversight, security review, and stakeholder coordination.
The expensive mistake isn’t paying for senior talent. It’s paying for rework because the initial design ignored governance, source variability, or handoff requirements.
How to budget without fooling yourself
Use a staged funding model.
Approve enough budget for:
- Foundational architecture
- A narrow first set of data products
- Governance and documentation
- Post-launch stabilization
Don’t approve a giant transformation envelope with vague outcomes. Tie release of later funding to clear platform milestones and adoption evidence.
Cheap implementations get expensive when every portfolio onboarding becomes a custom project.
The infographic above presents fixed percentage allocations, but treat those as directional design guidance, not a universal law. Your actual split will vary based on how much internal engineering capacity you already have and whether you choose a more managed or more engineering-heavy stack.
Your Next Steps to Data-Driven Value Creation
Private equity data programs create value only when they change operating decisions fast, across multiple assets, without turning every onboarding into a custom engineering job.
Start with a 30-day assessment across three portfolio companies. Focus on four things: reporting cadence, source system quality, metric definition consistency, and extraction effort. That gives you the information you need for procurement. You can spot whether you need a lightweight integration layer, a stricter canonical model, or a partner with real experience cleaning up fragmented ERP and CRM estates.
Then write a one-page business case that procurement, finance, and the deal team can all use. Define the first data domains, the decisions they will support, the business owner for each domain, the phase-one delivery scope, and the handoff model after go-live. If the document cannot answer “what gets built first, by whom, and at what cost,” it is not ready for vendor review.
Run two or three partner interviews before you issue an RFP.
Use those conversations to pressure-test scope, staffing, and architecture choices. Ask for a sample implementation plan, named team composition, assumptions about source-system readiness, and a clear view of what they will not own. Good partners challenge vague scope, refuse to promise unrealistic timelines, and explain where internal PE operating teams must stay involved.
Control cloud spend from day one. Warehouse compute, storage growth, orchestration runs, and careless environment sprawl will erode the ROI case faster than most CTOs expect. This overview of CloudCops’ optimization strategies is a useful companion for keeping implementation costs under control while the platform is still taking shape.
If you need a structured way to compare firms, rate bands, and platform fit before you issue an RFP, DataEngineeringCompanies.com offers practical buyer tools including firm profiles, rate guidance, and vendor evaluation resources designed for data platform consulting.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Top Enterprise Partners
Vetted firms whose specialty matches this article.
More in Enterprise Data Engineering

Data Engineering Partner Selection: The 2026 Five-Stage Framework
A 2026 framework for data engineering partner selection: pre-RFP signal scan, sourcing, evaluation, paid pilot, contract, and 90-day handover.

7 Top Nearshore Data Engineering Companies for 2026
Our 2026 guide to nearshore data engineering companies vets 7 top firms on rates, platforms (Snowflake/Databricks), and minimums. Find your ideal partner.

Data Engineering Vendor Scorecard Template (Free Download)
Download our free Data Engineering Vendor Scorecard Template. This guide explains our 8-factor methodology to help you evaluate and select the best consultancy.