Strategic Data Engineering for Government Agencies

Government data engineering sits in the blast radius of two hard truths. First, national statistical and administrative data now operate as core public infrastructure, shaping political representation, business decisions, economic monitoring, program evaluation, and action across every level of government. The scale shift is visible in the government data-intensive sector, which grew from $407.9 billion in 2012 to $778.0 billion in 2022 according to the U.S. National Academies. Second, most IT delivery still goes badly.
If you’re leading a first major modernization, don’t copy a commercial playbook and slap controls on later. That approach creates a platform nobody can procure cleanly, accredit on time, or sustain after the integrator rolls off. Good data engineering for government agencies starts with delivery discipline, compliance boundaries, and operating model decisions. The tools matter. The bureaucracy matters more.
Why Government Data Projects Demand a Different Playbook
A widely cited project-management statistic says only 1 in 200 IT projects meets all three success measures of scope, time, and budget, and only 1 in 14 is delivered on time and on budget, according to this project-management analysis. In government, those odds get worse fast because every delay compounds into procurement extensions, expiring budget authority, oversight scrutiny, and political frustration.
Private-sector teams often optimize for speed, local autonomy, and tool flexibility. Government teams answer to audit, records retention, accessibility, procurement law, security authorization, and multi-year funding constraints. A fast decision that ignores those realities doesn’t save time. It creates rework.
Treat delivery controls as architecture
In government, schedule and cost control belong in the technical design. If your migration plan doesn’t show environment sequencing, dependency management, data ownership, and cutover criteria, it’s not an engineering plan. It’s a slide deck.
I recommend three controls before you approve any build:
- Standardize project data early: Every workstream should use the same definitions for scope, milestones, dependencies, environments, and acceptance criteria.
- Plan capacity explicitly: Data migration, governance, testing, security review, and user enablement compete for the same staff. If no one owns capacity planning, the critical path becomes fiction.
- Detect conflicts while they’re still cheap: Legacy extraction, identity integration, warehouse modeling, and dashboard remediation often collide. Surface those clashes before procurement modifications make them painful.
Practical rule: If your PMO tracks dates but your engineering team can’t trace data dependencies and approval gates in the same view, you’re managing optics, not delivery.
The public-sector version of technical debt
Commercial teams can live with rough edges if revenue arrives quickly. Agencies can’t. Your platform has to survive leadership turnover, appropriations cycles, inspector general questions, public-records scrutiny, and cross-agency coordination.
That changes what “good enough” means:
| Delivery area | Commercial tolerance | Government reality |
|---|---|---|
| Documentation | Often deferred | Needed for handoff, audit, and continuity |
| Security review | Sometimes parallelized late | Must shape design from the start |
| Procurement alignment | Light vendor management | Formal requirements and traceable decisions |
| Stakeholder model | Small buyer group | Program, legal, security, finance, procurement, operations |
The mistake I see most often is framing the project as a stack selection exercise. It isn’t. It’s a constrained institutional change effort with technical components.
Defining Mission Objectives and Compliance Guardrails
Agencies waste months on platform debates that should happen later. The first decision is simpler and harder. Decide what the system must do for the mission, then set the compliance boundary that will govern every technical choice after that.
As noted earlier, government data systems now support core public functions at massive scale. Treat this platform as institutional infrastructure. If you define it loosely, procurement will drift, security review will expand, and your first useful release will slip into the next budget cycle.
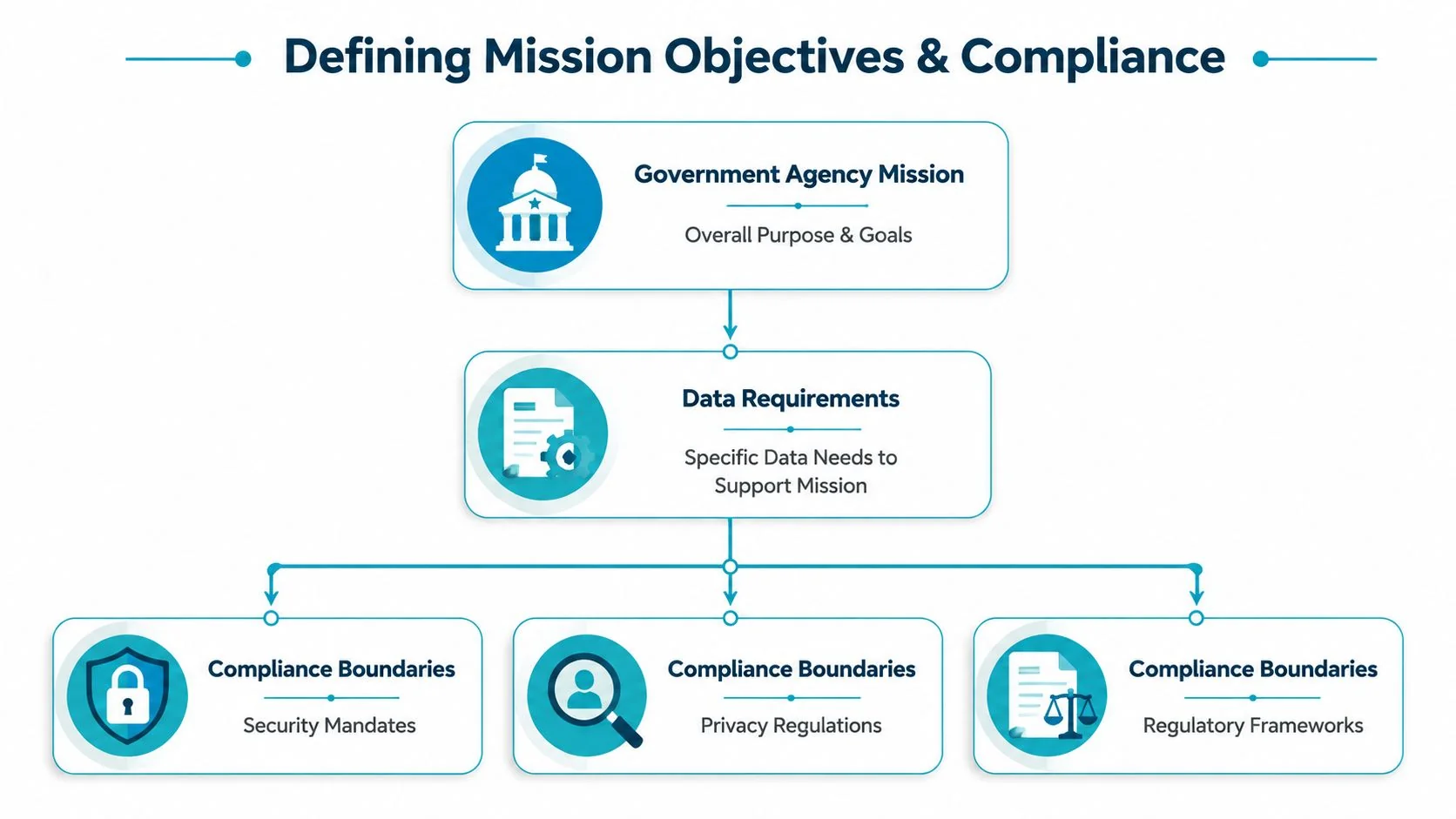
Start with mission products, not source systems
Write down the products the platform must produce for the agency. Be specific. A funding dashboard for program leadership. A caseworker view that resolves eligibility conflicts. A statutory reporting extract with traceable calculations. A governed dataset for state or federal sharing. A public release with suppression and disclosure review built in.
That framing matters because government failure rarely starts with code. It starts when a project is approved around vague technical activity such as “modernize data” or “integrate systems,” then gets pulled apart by finance, legal, privacy, and program offices that were never aligned on the actual outcome.
For each mission product, define four things before you approve any architecture work:
- The decision or action it supports
- The legal or policy authority for using the data
- The timeliness requirement
- The consequence if the data is wrong, late, or exposed
If a proposed dataset cannot pass that test, keep it out of phase one. Agencies get in trouble by dragging low-value data into the security boundary too early. That increases cost, review scope, and records burden without improving mission delivery.
Set compliance guardrails before vendor conversations
FedRAMP, FISMA, privacy rules, records schedules, and agency-specific overlays shape the project long before production. They affect hosting options, identity design, logging standards, encryption choices, administrative access, subcontractor eligibility, and whether your preferred managed service will survive the authorization process.
This is also where government projects hit non-technical resistance. Procurement wants requirements that can survive protest. Security wants a boundary they can assess. Privacy wants approved uses and disclosures. Finance wants something that fits the current appropriation and does not create an unplanned operations bill two years from now. If you wait for those groups to react to a draft architecture, they will block it. They should help define it.
Use a short set of guardrails that convert policy into build constraints:
- Security boundary: define which data types can enter the environment, who can administer it, and how duties are separated
- Identity and access: settle federation, role structure, privileged access, and service account controls before pipelines are built
- Data classification: label PII, confidential, public, and restricted data at ingestion
- Retention and deletion: assign lifecycle rules for raw, staged, curated, and published data so records obligations do not become indefinite storage
- Disclosure controls: require review, suppression, aggregation, and approval workflows for public or interagency outputs
If ownership is fuzzy, stop and fix it. Use clear data governance best practices for assigning stewardship, policy ownership, and decision rights before the platform enters procurement.
Translate mission and compliance into procurement-ready requirements
I recommend a one-page control matrix before any demo, market research session, or draft RFP. Keep it plain. Each row should connect a mission requirement or compliance obligation to a technical consequence and an operational owner.
For example:
| Mission or compliance need | Technical implication |
|---|---|
| Sensitive individual-level data | Restricted landing zone, masking, least-privilege access |
| Cross-department reporting | Canonical identifiers, shared semantic definitions, lineage |
| Public reporting | Reviewable transformations, release workflow, disclosure checks |
| Long-lived institutional use | Documentation, runbooks, ownership model, support operating model |
This document does more than guide engineering. It protects the project from avoidable government failure modes. It keeps procurement from buying a platform the security office cannot authorize. It keeps integrators from proposing features that trigger scope growth your appropriation cannot absorb. It gives legal and privacy teams something concrete to review before they are asked to approve production use.
If you skip this step, the agency usually pays twice. First in procurement delays, then in redesign after the winning vendor discovers the actual compliance constraints.
Selecting the Right Cloud and Data Platform Architecture
Your cloud and platform decision locks in governance patterns, vendor dependence, staffing requirements, and cost behavior. Don’t treat it like a feature bake-off. Evaluate whether the stack fits your agency’s authorization path, operating model, and sharing requirements.
For data engineering for government agencies, the core decision usually has two layers. First, pick the cloud environment that matches your procurement and compliance path. Then choose the data platform that your team can operate under those constraints.
Choose the cloud you can govern
AWS, Azure, and Google Cloud all offer public-sector paths, but the right choice depends less on marketing and more on three practical questions:
- Which environment fits your existing security and identity standards
- Which provider your operations team can support without a permanent consultant dependency
- Which managed services you can adopt without triggering a control and accreditation bottleneck
AWS often fits agencies that want broad infrastructure control and mature service depth. Azure often fits environments already anchored in Microsoft identity, productivity, and enterprise administration. Google Cloud and BigQuery can work well for analytics-centric teams that want a more opinionated warehouse experience and simpler operational patterns.
The wrong move is chasing the most flexible platform when your agency lacks the staff to govern that flexibility.
Snowflake versus Databricks for government use
This choice gets framed badly. Snowflake is not “for SQL people” and Databricks is not “for data science people.” For government buyers, the primary question is which platform better supports your control model, workforce, documentation needs, and sharing pattern.
| Criterion | Snowflake | Databricks | Government-Specific Considerations |
|---|---|---|---|
| Operating model | More managed and warehouse-centric | More engineering-centric across data, ML, and lakehouse patterns | Pick the one your agency can run with existing admin depth |
| Team profile | Strong fit for SQL-heavy analytics and governed consumption | Strong fit for mixed engineering, data science, and custom data processing | Government teams often underestimate platform administration burden |
| Governance style | Centralized data access and curated sharing are straightforward | Flexible governance, but requires more architectural discipline | Flexibility without stewardship becomes audit pain |
| Pipeline pattern | Works well with ELT, dbt, and managed ingestion patterns | Strong for complex transformations, notebooks, Spark workloads, and medallion-style pipelines | Match platform to workload complexity, not hype |
| Documentation burden | Still required, but platform complexity is often lower for analysts | Higher need for engineering standards, code review, environment controls, and handoff discipline | Turnover resilience matters more than initial build speed |
| Interagency sharing posture | Strong fit when you want tightly managed governed datasets | Strong fit when multiple teams need open engineering patterns and shared data products | Sharing rules, privacy review, and stewardship determine success |
Here is my blunt view.
Choose Snowflake when your agency’s near-term goal is governed analytics, cross-functional SQL access, standard ELT pipelines, and controlled sharing with less platform complexity. Pair it with dbt for transformation discipline and either managed ingestion or a lightweight orchestration pattern.
Choose Databricks when you need heavier data engineering, file and streaming workloads, complex transformation logic, or a single environment for engineering and advanced analytics. But don’t buy it unless you also fund platform engineering, standards, and durable documentation.
Tooling should reduce, not multiply, control surfaces
The biggest architecture mistake isn’t choosing the “wrong” warehouse. It’s assembling too many tools.
A government-friendly baseline often looks like this:
- Cloud foundation: AWS, Azure, or GCP aligned to existing enterprise controls
- Core platform: Snowflake or Databricks
- Transformation layer: dbt for versioned SQL transformations and testable models
- Orchestration: Airflow when you need explicit DAG control and cross-system coordination
- Storage pattern: raw, curated, and published layers with clear ownership and access boundaries
Don’t add extra catalog, observability, ingestion, notebook, and reverse-ETL products unless a named operating team owns them. Every new tool adds procurement overhead, integration risk, and another contract renewal.
Buy the minimum platform that can pass scrutiny and support the mission. Extra flexibility is expensive when nobody owns the controls.
Architecture decisions to force before procurement
Before the RFP goes out, get alignment on these:
-
Primary workload shape
Analytics-centric, mixed engineering, or advanced processing. This narrows warehouse and orchestration choices. -
Authoritative system strategy
Decide whether the platform is mastering identifiers, reconciling records, or only integrating source views. -
Data product model
Define whether teams publish governed datasets, domain-aligned products, or centralized curated marts. -
Support model
Internal operations, managed service, or hybrid. This choice affects platform complexity more than demos admit.
Without those answers, vendors will sell whatever they already know how to deliver.
Designing Resilient and Auditable Data Pipelines
Government pipelines need to answer three questions on demand. Where did the data come from. What changed. Who touched it. If your architecture can’t answer those quickly, the platform won’t survive audit, turnover, or contested reporting.
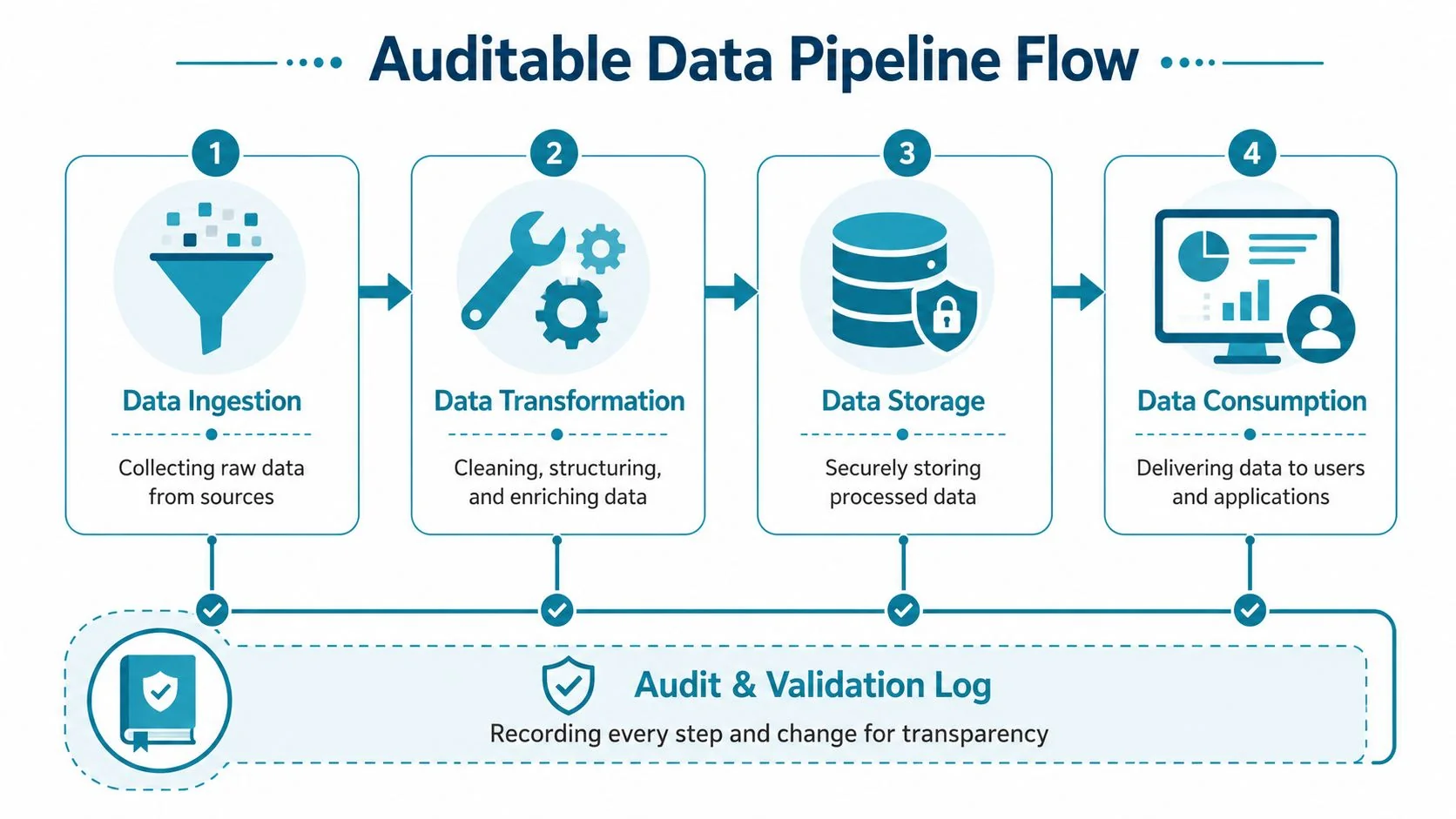
Public job postings for government data engineers emphasize maintaining a data inventory, documenting pipelines and dependencies, and cleaning and standardizing data from multiple systems. That points to a practical truth: agencies aren’t buying just code. They’re buying institutional memory and auditability, as reflected in these government data engineer job requirements.
Build for traceability first
Use an architecture that preserves raw input, versions transformation logic, and records orchestration events. In practical terms:
- Immutable landing zone: keep raw extracts unchanged and time-stamped.
- Version-controlled transforms: use dbt or equivalent so every model change is reviewable.
- Orchestration logs: Airflow or a managed orchestrator should retain execution context, failures, retries, and dependencies.
- Metadata and lineage: capture dataset owner, source system, schema changes, downstream dependencies, and release status.
This isn’t overhead. It’s how you defend the numbers when leadership, audit, or legal asks why a metric changed between reports.
Documentation is part of the deliverable
Most consulting teams underwrite documentation and over-deliver code. That’s backwards for government.
Your statement of work should require:
| Documentation artifact | Why it matters |
|---|---|
| Source-to-target mappings | Supports validation and future change management |
| Pipeline runbooks | Reduces dependency on the original implementation team |
| Data inventory | Establishes ownership, sensitivity, and stewardship |
| Access model documentation | Supports audit and least-privilege reviews |
| Dependency diagrams | Helps operations teams assess incident impact |
A platform that only the contractor understands is a failed public-sector implementation, even if the dashboards look good.
Here’s a useful walkthrough before we get into operating implications.
Staff for continuity, not just launch
The team design matters as much as the data model. You need people who own metadata, release discipline, quality checks, and stakeholder translation. Pure builders won’t keep the platform healthy.
I advise agencies to assign clear ownership across these functions:
- Platform owner: accountable for reliability, environment standards, and roadmap
- Data stewards: accountable for definitions, quality decisions, and release approval
- Pipeline engineers: accountable for ingestion, transformation, and remediation
- Business-facing leads: accountable for explaining tradeoffs to policy, operations, and executives
A pipeline survives scrutiny when ownership survives contractor turnover.
If you don’t fund those roles, the platform degrades into a warehouse full of stale tables and undocumented exceptions.
Building the RFP and Evaluating Data Engineering Vendors
Most failed procurements don’t fail because nobody responded. They fail because the RFP asked for “a modern scalable data platform” and left the hard parts unstated. Vendors then fill the gaps with assumptions that favor their delivery model, not your agency’s reality.
The market won’t make this easier. One industry source projects the global big data engineering services market will reach $187.19 billion by 2030, and says demand for data engineering roles is expected to increase by 35% in 2026, according to these data engineering market statistics. Government buyers compete in that same talent market, usually with slower procurement cycles.
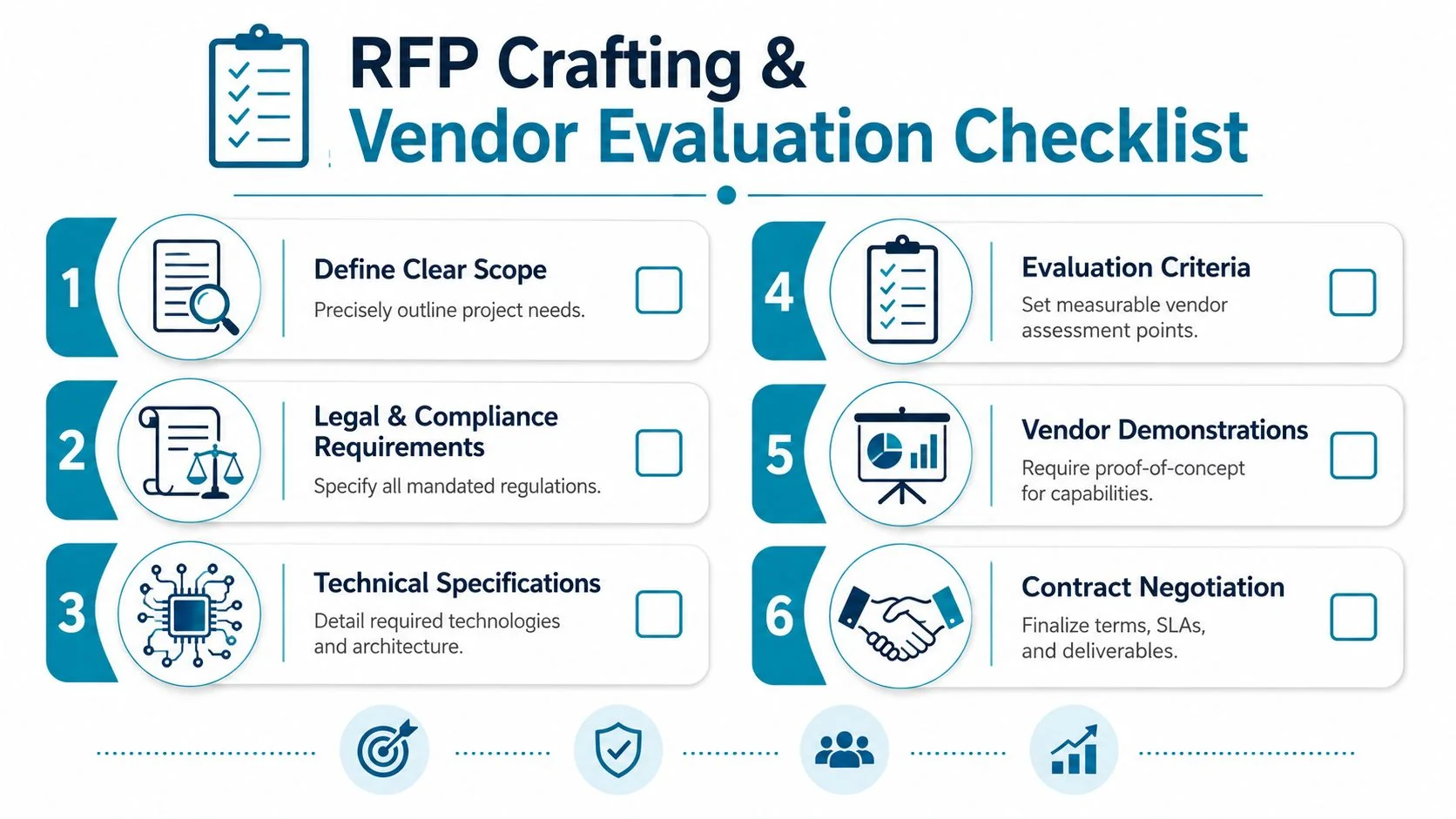
Write the RFP around constraints, not aspirations
A good RFP forces vendors to show they understand your environment. It doesn’t ask for a generic capability deck.
Require responses on these topics:
- Security and compliance fit: Ask how the vendor works inside controlled environments, handles separation of duties, and supports evidence collection for reviews.
- Operating model: Ask who documents pipelines, who maintains metadata, who owns runbooks, and how knowledge transfer happens.
- Migration approach: Ask for dependency handling, cutover sequencing, rollback planning, and validation methods.
- Delivery governance: Ask how they manage changes when procurement, security, and program stakeholders disagree.
- Public-sector realism: Ask for examples of navigating approval gates, not just building pipelines.
If accessibility artifacts are part of the procurement package, make vendors show they understand them. This guide for enterprise VPAT compliance is a practical reference for what serious procurement teams expect before software clears enterprise and government review.
Use an evaluation checklist that exposes weak vendors
Don’t overvalue partner badges or flashy architecture diagrams. Score vendors on whether they can deliver in your constraints.
A strong evaluation model includes:
-
Public-sector delivery evidence
Did they explain how they handle auditability, records, documentation, and handoff? -
Architecture fit
Does their proposed stack align to your chosen cloud, control boundary, and team capability? -
Governance maturity
Did they propose data ownership, issue triage, release discipline, and metadata management? -
Implementation discipline
Did they provide a credible migration and dependency plan, or just target-state diagrams? -
Sustainability
Will your internal team be able to operate the result without permanent outside dependence?
For teams that want a structured scoring approach, this checklist on how to evaluate data engineering vendors is useful for turning qualitative impressions into procurement criteria.
If a vendor can’t explain how the platform will survive after their last invoice, they haven’t proposed a government-ready solution.
Questions that separate practitioners from sales teams
Use direct questions in oral presentations:
| Ask this | What you’re really testing |
|---|---|
| Show the artifacts you’d hand over at go-live | Whether they treat documentation as deliverable work |
| Walk through a failed migration dependency and how you’d surface it | Whether they manage risk or hide it |
| Explain your model for stewarding data definitions across agencies | Whether they understand governance beyond ETL |
| Tell us which responsibilities stay with the agency | Whether they are honest about operating burden |
Reject proposals that promise speed without naming assumptions. In public-sector work, hidden assumptions become contract changes.
From Pilot to Production A Governance and Operations Roadmap
Roughly one in three federal IT projects run over cost or schedule. Data programs do worse when agencies treat the pilot as a technical exercise instead of a governance test. Your pilot should prove that the agency can make decisions, approve access, sustain operations, and defend the platform through the next budget cycle.
A pilot earns its keep only if it answers political and operational questions. Pick a narrow, production-intent use case with one decision, one user group, and a clear path to adoption. Test the hard parts early: data-sharing approvals, authority to operate constraints, records retention, privacy review, and who pays for year two.
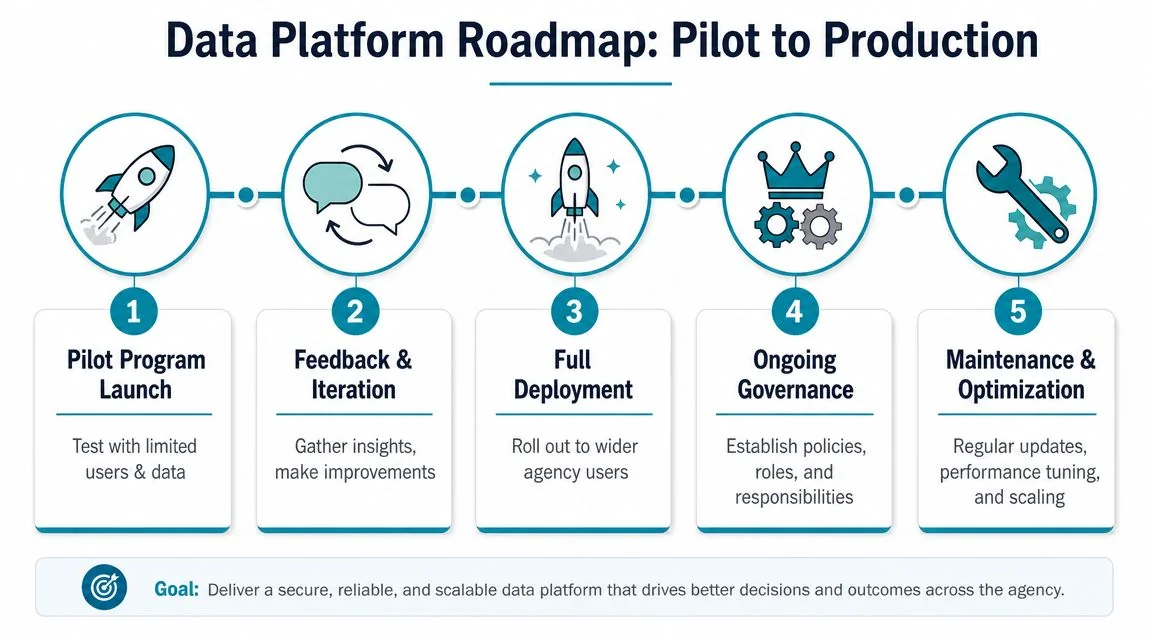
Build the pilot around one decision and one audience
The first production candidate should be small enough to govern and important enough to survive scrutiny. Choose a use case with named users, a defined approval chain, and a measurable operational result. If the audience is “the agency,” the scope is still political theater.
Use tight constraints:
- Named users: a specific program office, operations team, or executive function
- Authoritative sources: no side spreadsheets, shadow databases, or unofficial extracts
- Controlled outputs: every dashboard, file, and API has an owner, reviewer, and release process
- Operational feedback: users validate whether the output changed a decision, not whether the chart looks polished
Breadth is a trap. Government pilots fail because they try to satisfy every stakeholder before they prove one working model.
Stand up a governance council with actual authority
Advisory committees do not get pilots into production. You need a decision body that can settle ownership disputes, approve shared definitions, prioritize data products, and force resolution when security, privacy, and program teams disagree.
Include the people who can say yes and the people who can stop the work:
- Program owners from the missions the platform serves
- Security and privacy leaders with approval authority
- Platform leadership accountable for standards and operations
- Data stewards responsible for definitions, quality, and release decisions
- Procurement or contract staff when scope, option years, or vendor performance are affected
- Finance or budget leadership when ongoing operating funds are uncertain
Meet on a fixed cadence. Approve concrete items. Dataset promotion, access exceptions, interagency sharing rules, retention decisions, and backlog priority should all have a named decision and an owner.
Handle the public-sector blockers first
The hard part is rarely the pipeline. The hard part is getting legal, procurement, security, and program offices to agree on how data can be shared and used without creating audit findings or congressional embarrassment.
Federal guidance matters. The U.S. federal Equitable Data Working Group states that the data system should support disaggregation, directly or through statistical estimates, so historically underserved populations are visible in analysis, and it calls for increased federal-state-local data sharing in the same document, the equitable data vision document. That raises practical operating questions: who approves small-population reporting, how disclosure risk is reviewed, which agency owns definitions across jurisdictions, and what gets published versus restricted.
Set those rules before expansion. Do not wait until the third use case, when every exception becomes precedent.
The production roadmap I recommend
Use a sequence that fits how agencies fund and govern work:
- Pilot one mission-critical data product with fixed success criteria, named users, and a documented approval path.
- Lock down operations with runbooks, incident handling, access recertification, release management, and audit evidence collection.
- Secure year-two funding early by tying operating cost to mission outcomes and budget lines, not innovation language.
- Expand by domain so stewardship, controls, and ownership stay clear as adoption grows.
- Formalize interagency agreements before shared data becomes dependency-heavy and politically hard to unwind.
- Review the platform annually against mission shifts, appropriations, and compliance findings so it survives leadership turnover and budget resets.
The target state is not a finished platform. It is a governed operating model that can survive procurement delays, compliance reviews, election-year scrutiny, and the next continuing resolution.
If you’re evaluating partners for data engineering for government agencies, keep the buying process disciplined. Compare firms on public-sector delivery maturity, governance depth, documentation quality, and platform fit, not just certifications and demos. For a faster shortlist, practical RFP tools, and side-by-side consultancy comparisons, start with DataEngineeringCompanies.com.
Researched & written by
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Vetted partners
Top Enterprise Partners
Vetted firms whose specialty matches this article.
More in Enterprise Data Engineering

50 Data Engineering Discovery Call Questions to Ask Vendors (2026)
Fifty data engineering discovery call questions to ask vendors — buyer-side, with good-answer signals, red flags, and a 60-minute timebox script.

Data Engineering Proof of Concept Scoping: A 4-Week Vendor PoC Playbook (2026)
How to scope a data engineering proof of concept — the 4-week vendor PoC template, SMART acceptance criteria, IP clauses, and the 11-day go/no-go rubric.

Data Engineering Vendor Evaluation Criteria: 35 Criteria for 2026
The complete 35-criterion evaluation framework for choosing a data engineering vendor in 2026 — definitions, verification, red flags, and weighting.