Data Engineering for Biotech and Pharma: A CTO's Guide

Your team isn’t blocked by lack of models, dashboards, or cloud spend. You’re blocked because trial data, lab outputs, operational records, and real-world evidence still arrive in different formats, under different controls, with different definitions of “ready.” The result is familiar: analysts wait, scientists build side pipelines, compliance teams intervene late, and platform investments underperform.
That’s why data engineering for biotech and pharma belongs in the same conversation as R&D velocity, submission readiness, and commercial execution. The upside is large. The pharmaceutical data and analytics market is projected to grow from $1.47 billion in 2024 to $4.18 billion by 2034, and organizations that integrate data engineering workflows have reported a 30% reduction in development costs and a 25% reduction in time to market, according to RS on biotech and pharma data integration. If you’re a CTO, that isn’t background context. It’s your operating mandate.
The High Cost of Data Friction in Drug Development
Monday morning, your clinical operations lead asks for an updated enrollment view, your biometrics team is waiting on reconciled trial data, and quality has blocked a downstream release because no one can show exactly how a derived dataset was produced. By Friday, you have burned a week of expensive staff time without moving the program forward. That is what data friction looks like in drug development.
The cost is not abstract. It shows up as rework, idle scientists, delayed database locks, failed handoffs between research and clinical, and validation cycles that start late because the pipeline was never designed for GxP use. In a regulated environment, every unclear transformation becomes an approval problem. Every missing lineage record becomes a quality problem. Every uncontrolled copy of PHI becomes a HIPAA problem.
CTOs usually underestimate this because the spend is scattered across teams. One group pays for manual reconciliation. Another pays for consultants to repair a broken integration. A third group buys a new platform because the first one never reached production. Finance sees software and services. You should see delay risk.
A practical diagnostic for quantifying friction
Use this five-question check before you approve another platform purchase or issue an RFP:
-
How many handoffs does a priority dataset go through before it is analysis-ready?
More than three is a warning sign. Each handoff adds delay, ownership confusion, and validation work. -
Can your team trace a regulated output back to source, transformation logic, and approver without manual reconstruction?
If not, you do not have a production data system. You have a reporting workflow with compliance exposure. -
How often do scientists or analysts create side pipelines outside the governed stack?
That is not team creativity. It is a signal that your central platform is too slow, too rigid, or poorly scoped. -
How much time do data engineers spend on source-specific fixes instead of reusable pipeline components?
If most effort goes to one-off ingestion and cleanup, your architecture is not scaling. -
Who owns validation for data products used in GxP processes?
If the answer is unclear, the implementation is already off track.
If you cannot answer these questions quickly, your organization is paying a friction tax every day. Put numbers on it. Count cycle time from source arrival to approved use. Count duplicate datasets. Count failed releases. Count the hours spent preparing evidence for audit or inspection. That baseline matters more than a glossy platform demo because it tells you whether to buy a tool, redesign the operating model, or replace an implementation partner.
Where CTOs make expensive mistakes
The first mistake is treating Snowflake, Databricks, or a lakehouse decision as the strategy. It is not. The strategy is deciding what must operate as a validated, governed data production system and what can remain exploratory. Make that call first. Then choose tooling that supports it.
The second mistake is hiring a generic data partner that has never worked inside GxP and HIPAA constraints. In pharma, those requirements shape pipeline design, access controls, change management, test evidence, and release procedures from day one. If a vendor talks about speed first and validation later, remove them from the shortlist.
The third mistake is approving a build plan without a cost model. Building in-house makes sense when data products are a core competitive asset, your team can own validation long term, and you have enough platform engineering depth to avoid permanent contractor dependence. Buying or partnering makes sense when the bottleneck is execution speed, regulated delivery discipline, or domain-specific implementation experience. That is the true build-versus-buy decision. It is an operating model decision, not a branding exercise.
If you need a reference point for what a fit-for-purpose biotech platform can look like, review approaches that build your biotech R&D engine. Then pressure-test vendors against your own friction baseline, validation burden, and support costs. That is how you avoid paying twice for the same transformation initiative.
Why Biotech Data Is Uniquely Challenging
Most enterprise data teams are used to structured records, predictable schemas, and stable source systems. Biotech and pharma teams don’t get that luxury. They deal with mixed formats, domain-specific semantics, and evidence chains that have to stand up to quality review.

Three data classes that break generic playbooks
Genomic and assay data arrives in high-dimensional forms, often with metadata that matters as much as the primary measurement. Storage is only part of the problem. The hard part is preserving provenance, sample context, and transformation history so downstream analysis stays interpretable.
Clinical and real-world evidence data is worse from an engineering standpoint because it mixes structure and ambiguity. You’re dealing with EHR extracts, physician notes, claims, surveys, wearables, and trial datasets in the same program. Those sources don’t align cleanly, and forcing them into a simplistic common model too early destroys context.
Lab and operational data from LIMS, ELN, instrument outputs, and study operations systems creates another layer of fragmentation. Even when the data looks structured, naming conventions, identifiers, and process states differ across teams, sites, and vendors.
This is why retail-style ELT patterns fail here. In ecommerce, you normalize transactions. In pharma, you normalize biology, operations, and evidence.
Curation is the real schedule risk
The hardest phase isn’t loading data into cloud storage. It’s curation. Pharma data curation frequently extends project timelines by 40% to 60% beyond initial estimates because normalization and quality control across source systems are labor-intensive, according to Aventior on pharma big data challenges.
That has two implications for your consulting strategy:
- Don’t let vendors underprice curation. If a proposal makes transformation and quality control look trivial, the team doesn’t understand the domain.
- Don’t staff the project with only generic data engineers. You need people who understand healthcare standards such as HL7 and FHIR, plus unstructured data handling and biomedical context.
- Don’t define success as “data landed in the lake.” Success means validated, queryable, governed data with business-ready semantics.
The bottleneck in pharma isn’t cloud storage. It’s turning messy, multi-source biomedical data into something a scientist, analyst, and quality reviewer can all trust.
Domain context belongs in the platform design
Many biotech teams go wrong when they scale. They buy a modern platform, then bolt domain logic on later. That creates hidden costs and permanent complexity. If you’re trying to build your biotech R&D engine, the data model, ontology strategy, and workflow design need to be part of the architecture, not an afterthought.
A strong partner will ask hard questions early. Which identifiers are canonical? Where does sample lineage live? Which datasets support exploratory work, and which support regulated decisions? If a consultancy jumps straight to “we’ll set up dbt and Airflow,” keep looking.
GxP-Compliant Reference Architectures on the Cloud
The right architecture for data engineering for biotech and pharma is not a generic warehouse and not a chaotic data lake. It’s a cloud-native lakehouse with controlled data zones, explicit lineage, policy-based access, and separate paths for exploratory work versus validated production.
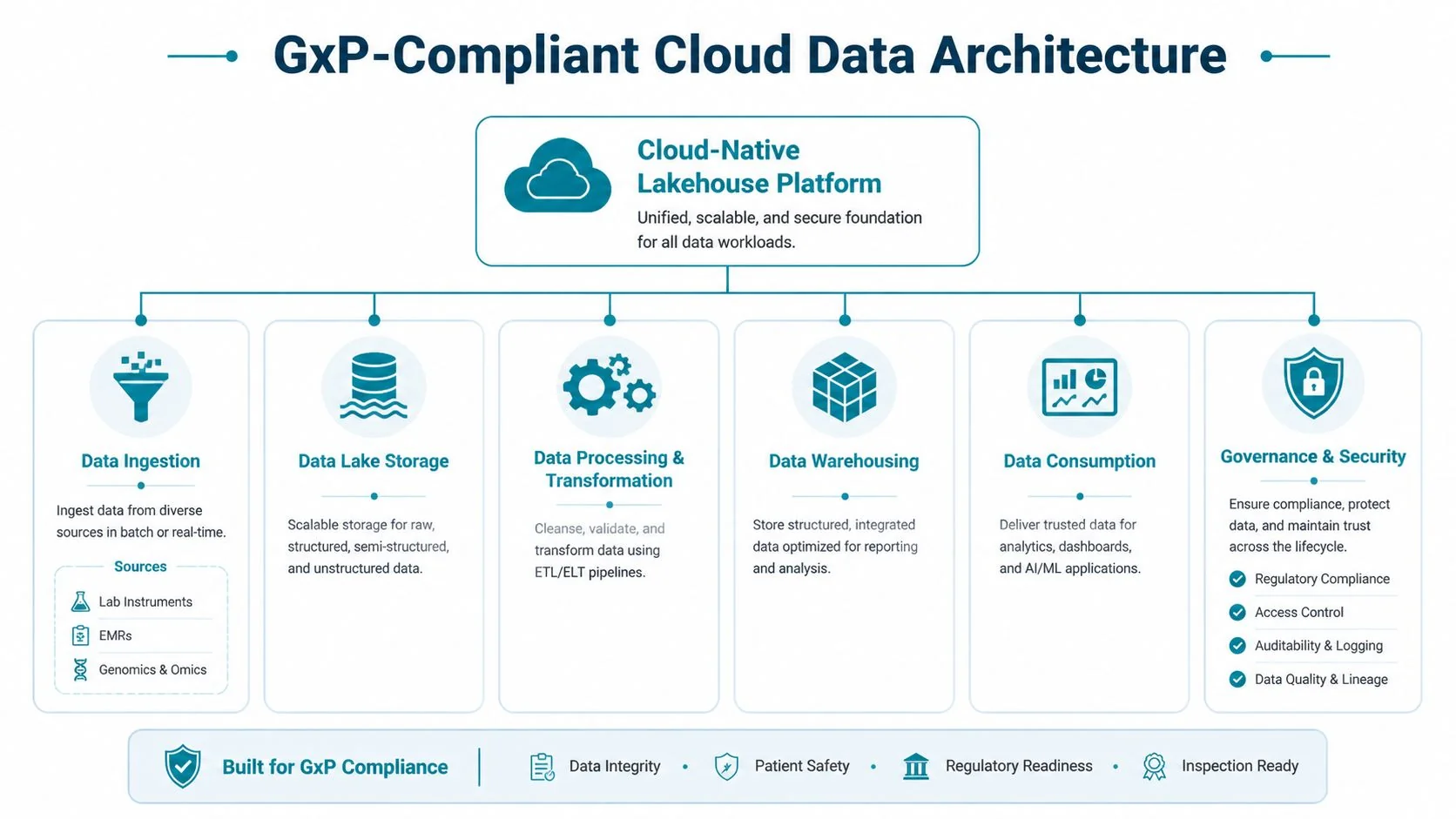
The baseline architecture
A practical regulated stack usually includes:
- Cloud foundation on AWS, Azure, or GCP with network segmentation, centralized identity, encryption, and environment separation.
- Raw and curated storage layers so you preserve source fidelity while creating governed, reusable datasets.
- Orchestration with Airflow for cross-system workflow control and observable scheduling.
- Transformation with dbt or equivalent SQL-based framework for structured data products, tests, and documentation.
- A lakehouse or warehouse layer for governed consumption, depending on workload.
- Metadata, lineage, and audit controls embedded across ingestion, transformation, and access.
If you’re under GxP and handling PHI, every layer has to support traceability and controlled change. “We’ll document it later” is not a real plan.
Snowflake versus Databricks for pharma workloads
A single-platform answer shouldn’t be forced.
| Workload type | Better fit | Why |
|---|---|---|
| Structured clinical operations, finance, commercial reporting | Snowflake | Strong fit for governed SQL analytics, data sharing, and controlled marts |
| Exploratory science, genomics, unstructured processing, feature-heavy ML | Databricks | Better fit for notebook-led experimentation, distributed compute, and complex data processing |
| Cross-functional enterprise data products | Hybrid | Use each where it fits instead of overextending one platform |
Snowflake is usually the cleaner choice for standardized reporting, commercial analytics, and controlled data serving. Databricks is usually the stronger choice for data science-heavy R&D programs, especially where file-based, multimodal, or iterative processing dominates.
Use dbt where your transformations are stable, reviewable, and SQL-centric. Use notebooks and code pipelines where the workload demands it. Don’t force genomics engineering into warehouse conventions, and don’t force commercial reporting into notebook chaos.
Modernization has to start upstream
Many pharma organizations still run data management processes that resemble the early 2000s, despite adopting cloud and big data tooling. IQVIA documented a 72x efficiency gain in global analytics processes after systematic modernization in its white paper on data engineering in commercial pharma.
That finding matters because it exposes the underlying problem. Platform migration alone doesn’t fix broken sourcing and transformation workflows. If your upstream systems remain fragmented and manually reconciled, Snowflake or Databricks just becomes the last stop in a bad pipeline.
Buy the platform that matches the workload. Fix the operating model that feeds it. Do both, or you won’t get the return.
Embedding Governance and Validated MLOps into Your Pipelines
If you’re using machine learning in biopharma, the model is not the hard part. The hard part is proving where the data came from, how it changed, who approved it, and whether the exact output can be reproduced under review.
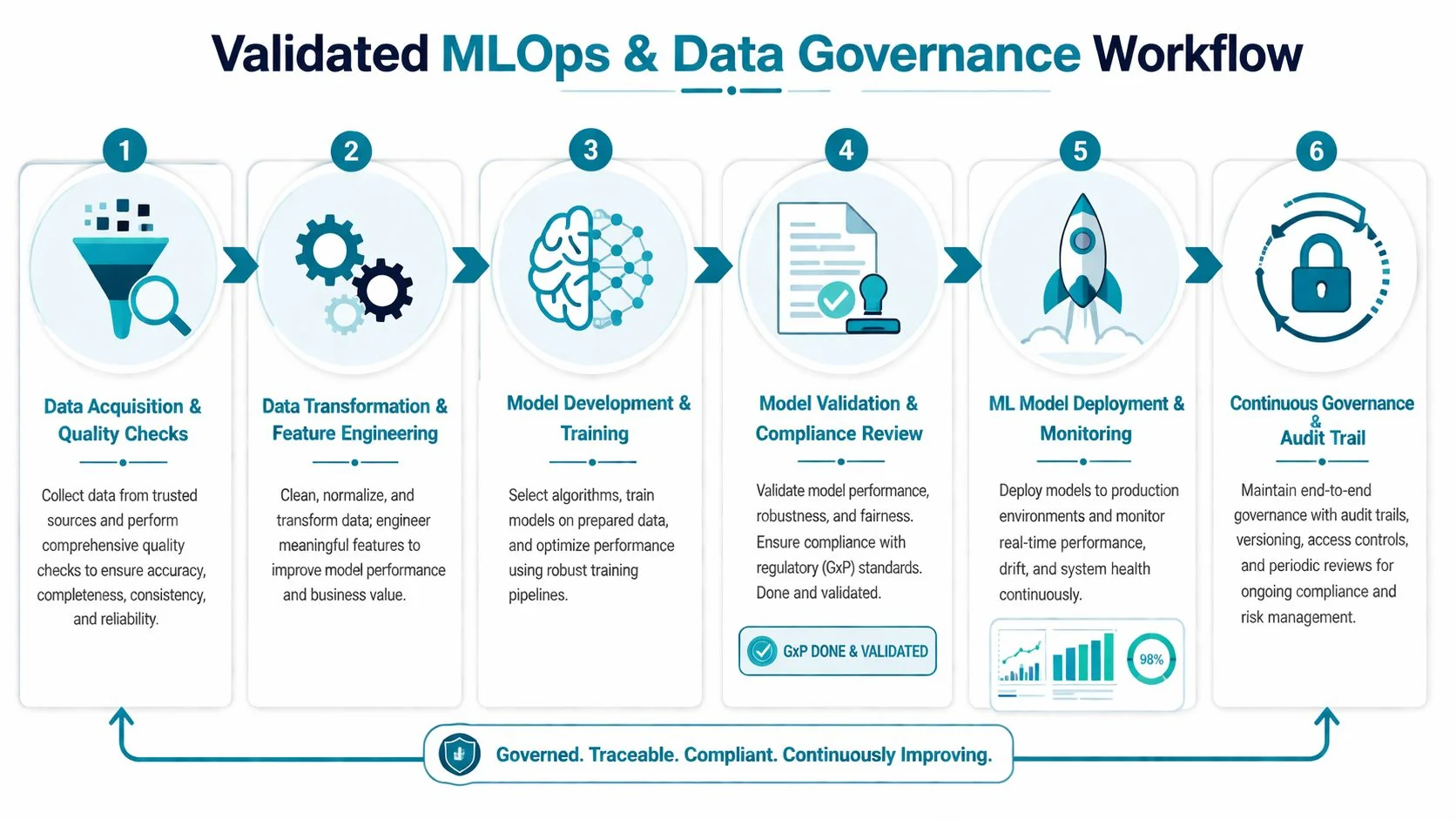
Machine learning adoption in biopharma has grown sharply, with utilization increasing by 250% in journal articles and 357% in patents over a five-year period, yet core data management processes in many large organizations have changed very little, according to the NIH-indexed review of data analytics in biopharma. That’s the gap your architecture and delivery model need to close.
Governance requirements that aren’t optional
A compliant data pipeline needs more than permissions and backups. It needs:
- End-to-end lineage from source ingestion through transformation to downstream model or report.
- Role-based access control tied to data sensitivity, study role, and least-privilege principles.
- Immutable audit trails for data changes, code changes, model versions, and approvals.
- Controlled release processes so validated datasets and models move through formal promotion paths.
- Retention and reproducibility policies that preserve the exact inputs and logic used in regulated outputs.
If your consultancy talks about governance as a documentation workstream, not a pipeline capability, they’re not ready for GxP work.
What validated MLOps looks like in practice
Validated MLOps is simpler than vendors make it sound. It means every stage is versioned, reviewable, and reproducible.
- Data acquisition and quality gates should fail fast on schema drift, missing fields, and invalid mappings.
- Feature pipelines need code versioning, test coverage, and documented assumptions.
- Training runs should capture dataset version, parameter set, environment, and approval status.
- Validation has to be separate from development, with evidence stored for review.
- Deployment needs controlled promotion, monitoring, rollback, and access logging.
For clinical standards work, teams often need practical guidance on how analytical datasets map into regulated submission structures. OMOPHub’s SDTM guidance is a useful reference for structuring that conversation with data, clinical, and regulatory stakeholders. For a broader operating model, this guide to data governance best practices is worth using as a review checklist against your current pipeline design.
Compliance as code beats compliance by spreadsheet. If lineage, approvals, and controls live outside the pipeline, they will drift from reality.
Mastering Security and Patient Data De-identification
Security architecture in pharma is not a side concern managed after the data platform goes live. It determines what research can happen, who can collaborate, and whether external partnerships move at all. Teams that treat de-identification as a legal cleanup task leave analytical value on the table.

Use the minimum viable data for the use case
For real-world evidence, more data is not automatically better. The right target is the smallest, soundest combination that can credibly generate the evidence you need, and manufacturers need to pair data with clinical expertise and AI to extract value from unstructured sources, as noted in KMS Technology’s discussion of big data in pharma.
That principle should shape de-identification strategy. Start from the decision or analysis you need to support, then decide what fields, granularity, and linkage you need.
Choosing the right de-identification approach
Different use cases need different controls.
| Technique | Best use | Trade-off |
|---|---|---|
| Pseudonymization | Internal analytics with controlled re-linking | Higher utility, tighter control requirements |
| Generalization and suppression | Data sharing with reduced re-identification risk | Lower precision for cohort and temporal analysis |
| Differential privacy | Aggregate reporting and privacy-preserving releases | Stronger protection, less useful for record-level science |
| Synthetic data | Software testing, prototyping, external demos | Useful for development, not a substitute for regulated evidence |
The mistake is picking one enterprise-wide method. That creates either unnecessary restriction or unnecessary risk.
Make HIPAA and GxP operational
Your controls should be embedded in data classes and policy enforcement:
- Restricted identified data for tightly controlled operational or clinical functions.
- Pseudonymized research data for internal approved analytics and model development.
- De-identified partner-ready datasets for external collaboration under contract and review.
- Synthetic or masked non-production data for engineering and QA workflows.
For teams formalizing these controls, Nonprofit HIPAA best practices is a useful operational reminder that compliance lives in process and access discipline, not just in legal text. This overview of healthcare data engineering and HIPAA compliance is also a practical checkpoint for platform and workflow design.
The strategic point is simple. Good de-identification expands usable data access. Bad de-identification either exposes the company or makes the data useless.
Scoping Your Project and Selecting the Right Partner
Most failed consulting engagements start with one of two errors. The scope is too broad, or the vendor is too generic. You need a partner that can design pipelines, operate in regulated environments, and speak fluently with data engineering, quality, security, and business teams.
Don’t start with a giant enterprise migration. Start with one high-value data product or one constrained platform initiative. Examples include a compliant clinical data mart, a governed RWE ingestion pipeline, or a validated transformation layer for one study domain.
Build versus buy
Use this decision logic:
- Build internally if you already have strong platform engineering, data governance leadership, and domain-aware architects who have delivered under GxP.
- Buy implementation help if your team knows the target state but lacks delivery bandwidth or regulated cloud migration experience.
- Use a specialist partner if the project includes trial data, RWE integration, de-identification, or validation-heavy MLOps.
The costliest option is pretending a generic cloud consultancy can learn pharma on your timeline.
What to demand in the proposal
A serious proposal should spell out platform scope, validation approach, data model strategy, operating model, handoff plan, and who owns ongoing support. It should also be explicit about assumptions around source system quality, ontology work, and data stewardship.
If a vendor can’t explain how they’ll handle GxP documentation, HIPAA controls, lineage, and release management in the same plan as Airflow, dbt, Snowflake, or Databricks implementation, reject them.
RFP Checklist for Biotech Data Engineering Partners
| Evaluation Category | Key Questions to Ask | Red Flags to Watch For |
|---|---|---|
| Regulated delivery | How do you handle GxP documentation, validation, and change control in pipeline delivery? | Treats validation as separate paperwork after build |
| HIPAA and privacy | How do you classify PHI, enforce access controls, and support de-identification workflows? | Gives only generic security answers |
| Source system complexity | Which pharma data sources have you integrated, and how did you handle messy mappings and curation? | Talks only about CRM, ERP, and generic SaaS connectors |
| Platform fit | Why are you recommending Snowflake, Databricks, or a hybrid approach for this workload? | Pushes one platform for every use case |
| Transformation design | Where do you use dbt, where do you use code pipelines, and how do you test both? | No opinion on transformation boundaries |
| Orchestration and observability | How will Airflow jobs, SLAs, failures, retries, and lineage be monitored? | Focuses on build, ignores operations |
| Governance | How are lineage, approvals, metadata, and audit logs captured? | Says governance will be handled manually |
| MLOps | How do you make model training, validation, and release reproducible for regulated review? | Equates MLOps with notebook collaboration only |
| Team composition | Who exactly is on the project, and which members have healthcare or pharma data experience? | Senior people sell, juniors deliver |
| Knowledge transfer | What does the handoff include for internal platform ownership? | No enablement plan, dependency by design |
Ask vendors to walk one real pipeline from source to approved output. Architecture slides are easy. Operational detail exposes whether they’ve done the work.
Your Action Plan for Launching a Data Transformation Initiative
A biotech or pharma data program succeeds when the first phase is narrow, defensible, and built for scale. You don’t need a grand transformation memo. You need a business case, a pilot with clear boundaries, and a partner evaluation process that rewards execution over slideware.
Step one: quantify the operational pain
List where data friction is already costing the business. Delayed study reporting, repeated manual reconciliation, failed reproducibility checks, slow onboarding of new datasets, and weak audit readiness are all valid inputs. Tie each one to a team, a workflow, and a decision that’s slowed down.
Keep this short and sharp. The goal is to prove that the current state is expensive and risky, not to document every defect in the estate.
Step two: pick a pilot with hard boundaries
The best pilots have one business owner, one accountable data owner, and one constrained output. Good examples:
- A validated data mart for a single clinical program
- A governed ingestion pipeline for one RWE source family
- A curated research layer that unifies one lab system with one downstream analytics workflow
Bad pilots try to unify all R&D data, all commercial reporting, and all AI needs at once. That’s not ambition. That’s scope failure.
Step three: define non-negotiables before vendor meetings
Write these into the brief:
- GxP support is mandatory where regulated outputs are in scope.
- HIPAA controls are mandatory for PHI handling, access, and de-identification.
- Lineage and auditability must be built into the pipelines.
- Platform recommendations must be workload-specific.
- Knowledge transfer is part of delivery, not an optional add-on.
This forces serious vendors to answer your real requirements instead of selling a reusable cloud package.
Step four: score partners on delivery reality
Use the RFP checklist, but also run live working sessions. Have each shortlisted partner explain:
- how they would ingest one difficult source,
- where they would use Snowflake, Databricks, dbt, and Airflow,
- how validation evidence would be produced,
- who on their team would handle governance and privacy design,
- what the first production release would look like.
If they stay abstract, they won’t deliver concretely.
Step five: set success metrics before kickoff
Use a small set of measures tied to the pilot. Focus on production readiness, reproducibility, data quality issue handling, release discipline, stakeholder adoption, and auditability. Avoid vanity metrics about dashboard counts or raw ingestion volume.
The strongest program leaders also decide the operating model before the build starts. Who owns metadata? Who approves schema changes? Who signs off on promoted datasets? Those decisions prevent drift later.
Step six: plan phase two before phase one ends
If the pilot works, the next move isn’t a broad rewrite. It’s controlled expansion. Reuse the ingestion patterns, governance controls, and validation approach you already proved. Standardize what worked. Replace what didn’t.
If you’re evaluating firms for that next step, use DataEngineeringCompanies.com to compare specialist consultancies, rate bands, capabilities, and shortlist criteria with less guesswork.
If you’re leading data engineering for biotech and pharma, the decision isn’t whether to modernize. It’s whether you’ll do it with a regulated operating model, the right platform mix, and a partner that understands the domain. Start with one high-value workflow, build auditability into the pipeline itself, and refuse generic consulting answers. That’s how you get speed without losing control.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Data Engineering Partners
Vetted experts who can help you implement what you just read.
